머리를 식힐 겸 유튜브를 보다가 평소에는 관심없이 지나가던 내용을 너무나 쉽게 이해할 수 있도록 정리되어진 코즈님의 정리 영상을 보고 나름대로의 기록하여 기억하기 위해 작성했다.
JDBC vs SQL MAPPER vs ORM 이 세가지의 공통점은 무엇일까?
그것은 바로
PERSISTENCE (영속성)
데이터를 생성한 프로그램의 실행이 종료되더라도 사라지지 않는 데이터의 특성이다.
우리는 데이터베이스를 연결하지 않고 프로그램을 구현하고 어떠한 정보를 입력했을 때 그정보는 남아있지않고 종료와 함께 그 정보가 사라진적을 경험 해본적이 있을 것이다.
지금 부터 설명할 내용은 정보가 사라지지 않도록 어떻게 영속성을 부여할 것인지를 고르는 방법이다.
왜 나왔을까?
나는 평소에 어떠한 기술이 나오기 까지는 나름대로의 순서가 있고, 불편한 점을 해소하기 위해 기술이 발전되었다고 생각한다. 마침 영상에서도 "핵심을 파악해 기술을 이해하려면 그 역사와 배경을 아는것이 효율적이지 않을까?" 는 말이 있는데, 그 말이 좀 더 쉽게 와닿았다.

JDBC API
90년대 중반
- 인터넷 보급과 DB 산업의 성장
- 온라인 비즈니스의 투자 증가와 DB Connector에 대한 니즈가 증가
- JAVA 진영의 DB연결 표준 인터페이스가 나왔다.(JDBC API)
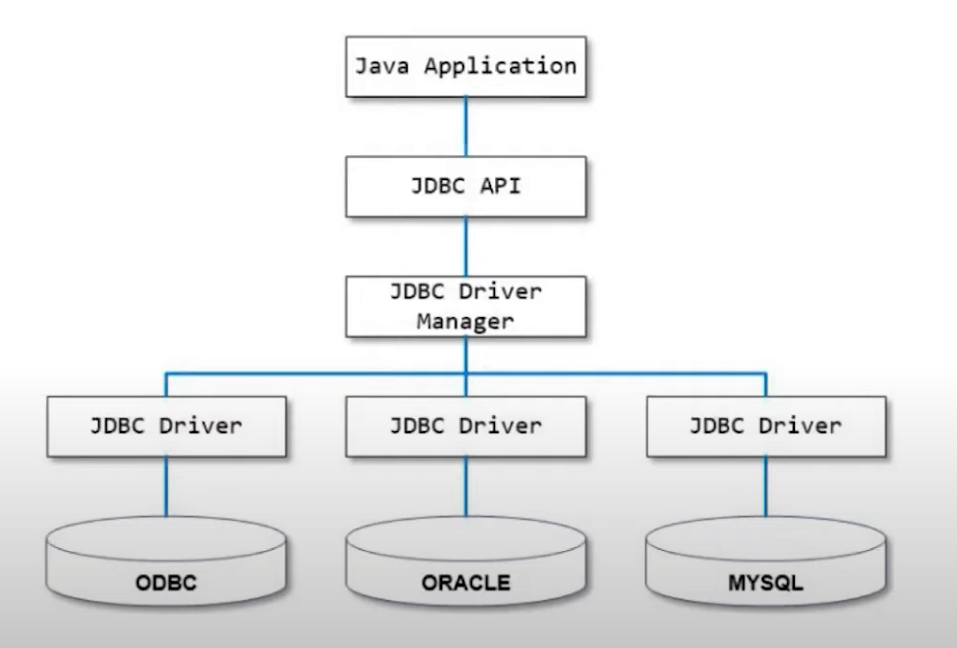
JDBC API 명세를 DriverManager가 구현을 하고 API에 맞게 동작할 수 있게 각 제품군에 따라 Driver가 만들어져 있는걸 볼수가 있다.
따라서, 사용하는 API를 변경하지 않더라도 Driver만 바꿔준다면 어떤 제품이든지 사용이 가능해졌다.
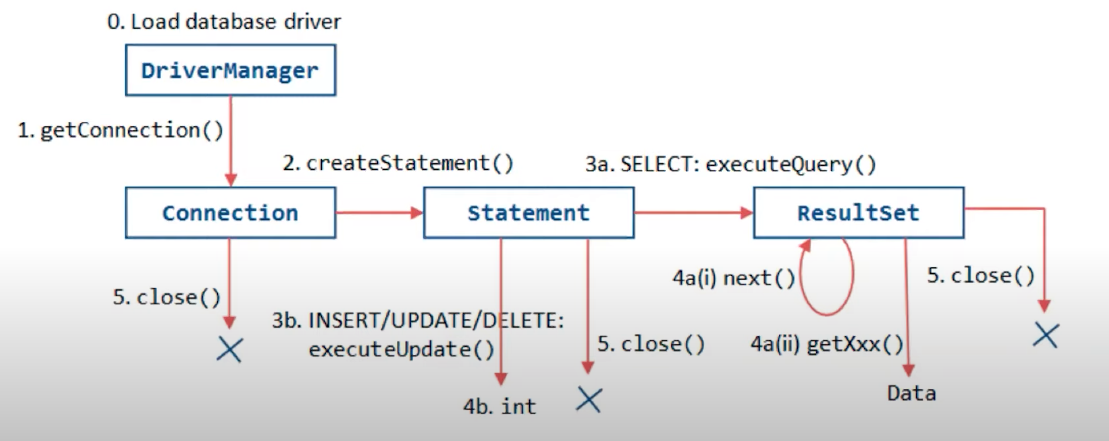
DriverManager를 이용해서 Connection인스턴스를 얻고,
Connection을 통해서 Statement를 얻고,
Statement를 이용해서 ResultSet를 얻어 조회하거나 사용하게된다.
이러한 이용에 불편함점이 있었는데, 중복된 코드,쿼리문 작성,Connection 관리, 예외 처리등이 있었다.
SQL mapper
Spring JDBC
public class CrewDAO{
private JdbcTemplate jdbcTemplate;
@Autowired
public void setDataSource(DataSource dataSource){
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
public List<Crew> getCrews(){
return jdbcTemplate.query("select * from crews", new RowMapper<Crew>(){
@Override
public Crew mapRow(ResultSet rs, int rowNum) throws SQLException{
return new Crew(rs.getInt("id"), rs.getString("name"));
}
});
}
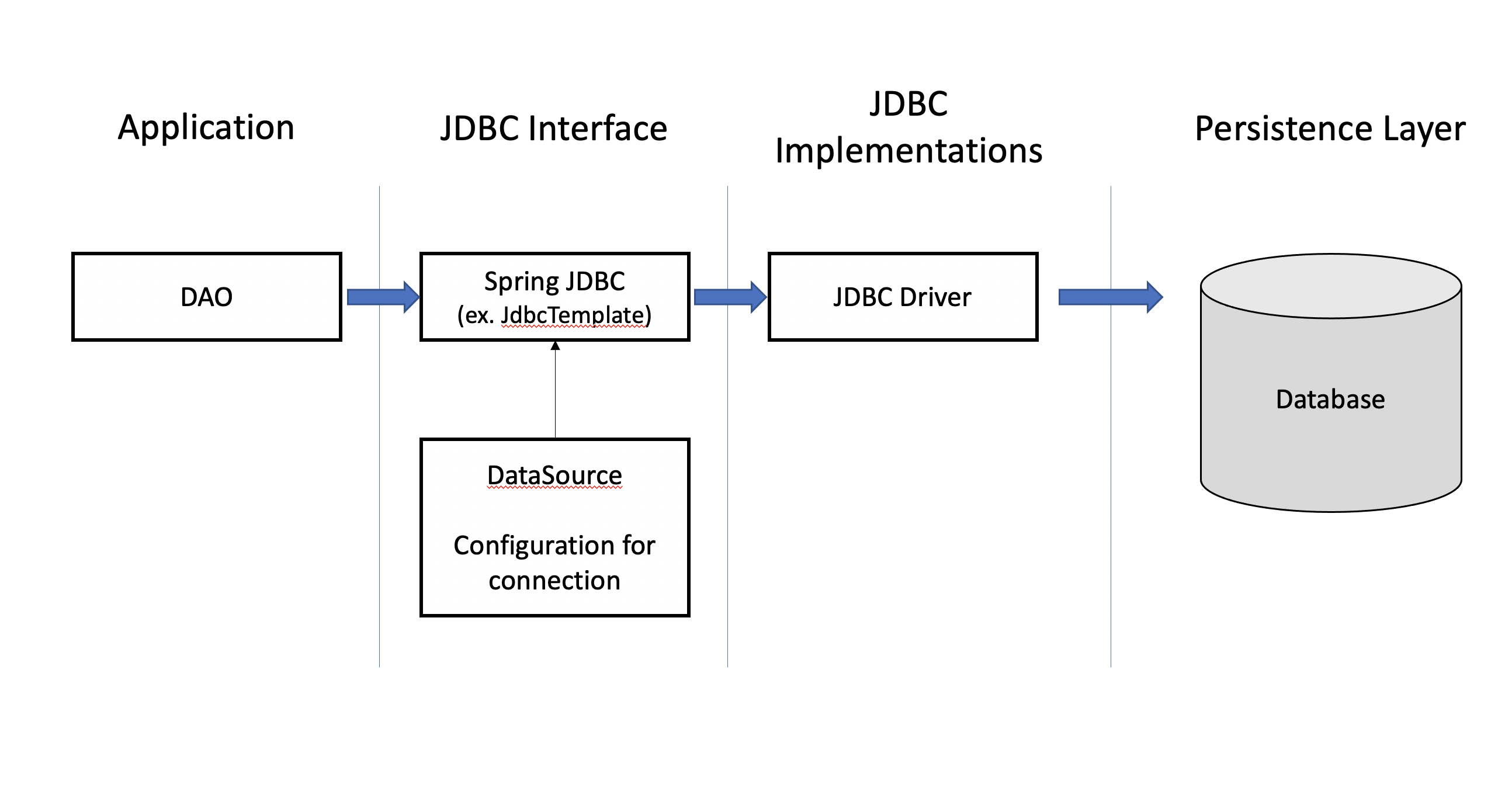
}JDBC API만을 사용할 때보다, Connection에 대한 Configuration을 JdbcTemplate이라는 클래스에 담아 Spring을 통해 주입받는다. 또, 메소드에 쿼리를 매핑해두고 RowMapper를 통해 쿼리 메소드의 결과를 통해 DB의 각 row마다 하나의 인스턴스화를 지원해준다. 추상화가 많이 이뤄져 이전보다 편하게 사용하고 있는 모습을 볼 수 있다.
개발자는 어떤 DB를 사용할 것인지에 대해 연결 파라미터를 넣어주면 Spring이 알아서 연결을 열어준다. 또, 개발자가 원하는 쿼리를 설정하고 해당 쿼리에 들어가는 파라미터를 넣어주면 Spring이 해당 statement를 알아서 수행해주며, 결과 resultset에 대한 루프, 예외처리, 트랜잭션, 종료까지 많은 부분을 대신해주며 기존 방식에서의 불편을 덜어줬다.
Mybatis
교육을 들으면서 가장 먼저 접한 데이터베이스 액세스 기술이다. 비전공이지만 학부시절 DB를 배웠어서 sql문을 작성하는데, 다른 교육생들 보다 조금 쉽게 이해할 수 있었다. 내가 느낀 Mybatis는 직관적이여서 접근하기 편했다.
Mybatis는 기존 JDBC의 문제점을 Spring JDBC와 약간 다르게 해석했다. Java 코드에서 SQL을 쓰는 것 자체를 분리하는 것을 목표로 잡았다. String으로 넣게 되면 띄어스기하나 잘못하면 동작을 안하기때문. Query를 Java에서 XML로 이동하는 것이다.
- 복잡한 JDBC 코드 X(Connection,statement etc..)
- ResultSet과 같이 결과값을 매핑하는 객체 X
- 간단한 설정!
- 관심사 분리!
ORM(Object-Relational Mapping)
나는 자바에서 Mybatis만을 사용해봤기 때문에 교육에서 Python ORM을 사용하면서 굉장히 놀라지 않을 수 없었다. 아니? SQL문을 쓴 기억이 없는데 어떻게 자료를 끌어다쓰고 변경이 가능하지? 라고 그때는 생각하고 말았다. 핑계를 대자면 진도를 따라가기에 급급했기때문.. 그러나 수업을 수강하고나서 혼자 JPA를 사용해보려고 하니 ORM에 대해서 아는 것이 없었는데, 테크 톡이 많은 도움을 줬다.
JPA / Hibernate
객체지향적으로 구현되어 있는 구조에서 관계형데이터베이스와 연결하는 것을 간편하게 하기 위해 등장한 기술이다.
// 변경 전
public class Crew{
private int id;
private String name;
}
// 변경 후
public class Crew{
private int id;
private String name;
private String nickName;
}
위의 코드에서 아래 코드로 변경된다면, 당연히 SQL구문도 변경되어야한다.
String sql = "INSERT INTO CREW(CREW_ID, NAME, NICKNAME) VALUES(?,?,?)";
...
pstmt.setString(3, crew.getNickName());
...
...
SELECT CREW_ID, NAME, NICKNAME FROM CREW WHERE CREW_ID = ?
...이러한 문제는 SQLMAPPER를 사용한다고 해결되지않고 여전히 변경작업을 수행해야한다.
public class Crew{
private int id;
private String name;
private String nickName;
private Team team;
}또 한번 수정하는 일이 생겼다.(사실 처음부터 잘하면 문제가 생기지않지만 그럴일이 거의 없다.)
이번에는 객체다. 이 객체는 어떻게 표현해할까?
객체를 갖는 멤버변수로 갖는 구조는 RDB상에서 그대로 표현되지 않고 team Id를 외래키로 지정하는 형태로 갖기 때문에 점점 작업해줄 것이 많아지고 복잡해진다.
김영한님의 Spring 책
"물리적으로 SQL과 JDBC API를 데이터 접근 계층에 숨기는데 성공했을지는 몰라도, 논리적으로는 엔티티와 아주 강한 의존 관계를 가지고 있다."
한쪽에서 변경이 일어나면 다른 한쪽도 변경이 일어아냐하기 때문.
(물리적으로는 떨어뜨려놨지만,논리적으로는 서로 의존관계라는 뜻)
관계형데이터베이스에서는 객체지향에서의 개념인 연관관계(객체 참조), 상속을 그대로 표현하는 것이 어렵고 불편한 문제가 있었다. 객체 지향과 관계형데이터베이스의 시작점, 설계원칙이 다름-> 패러다임의 불일치 -> 개발자들의 SQL 의존적인 구현 현상 발생
이를 해결하기 위해서 ORM(java에서는 JPA라는 인터페이스가)이 등장한다.
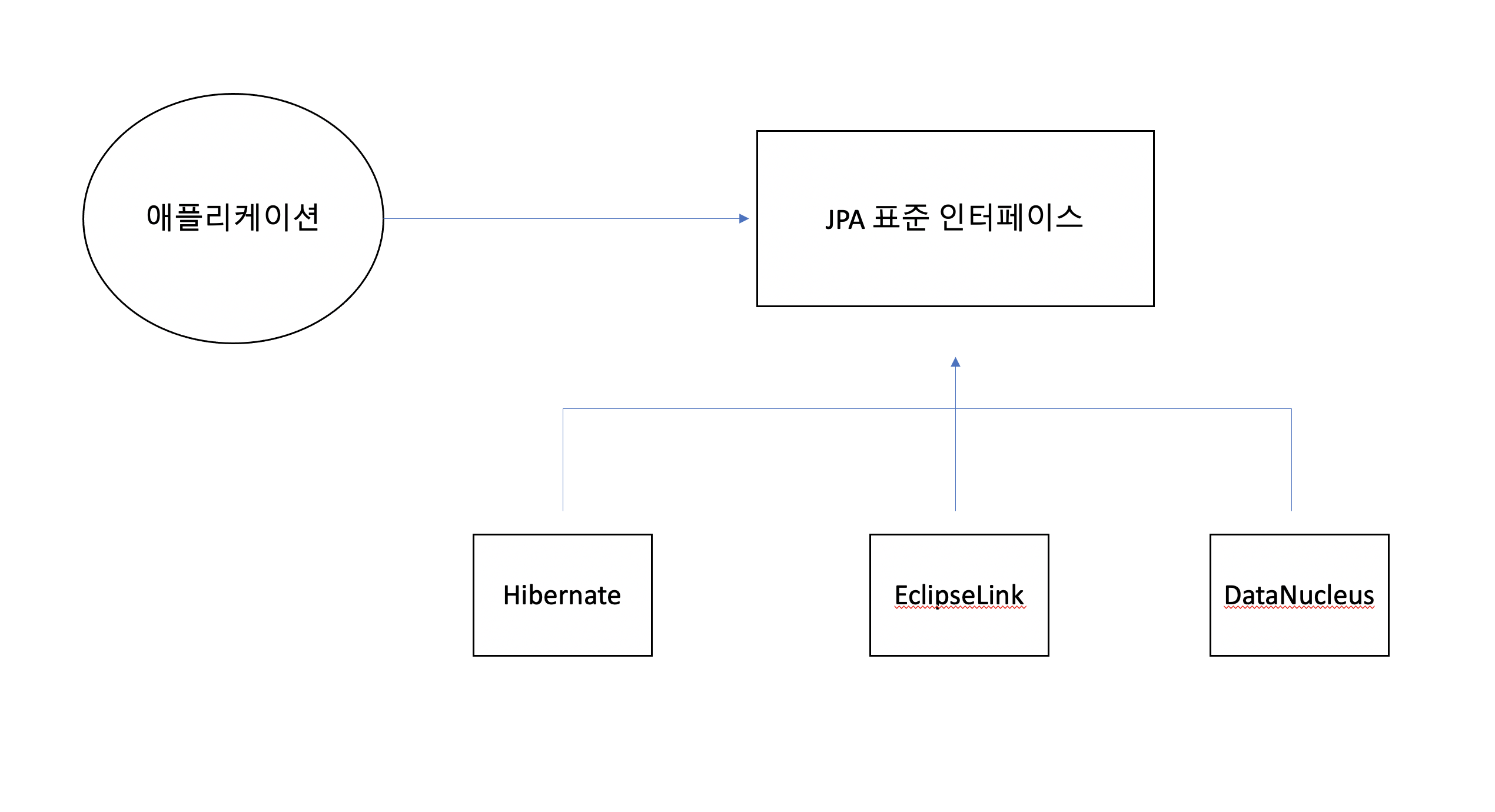
JPA는 표준 인터페이스가 있고, 이를 구현하는 실제 서비스가 여러가지 존재한다. 그 중 하나가 Hibernate이고, 그 외 다양하게 존재한다. JPA도 JDBC API가 여러 Driver를 변경할 수 있던 것처럼 마찬가지로 추상화를 통해 손쉽게 기술 변경이 가능하다.
그렇다면 이들의 핵심 모델은 무엇인가?
바로 EntityMagager 와 영속성 컨텍스트 이다
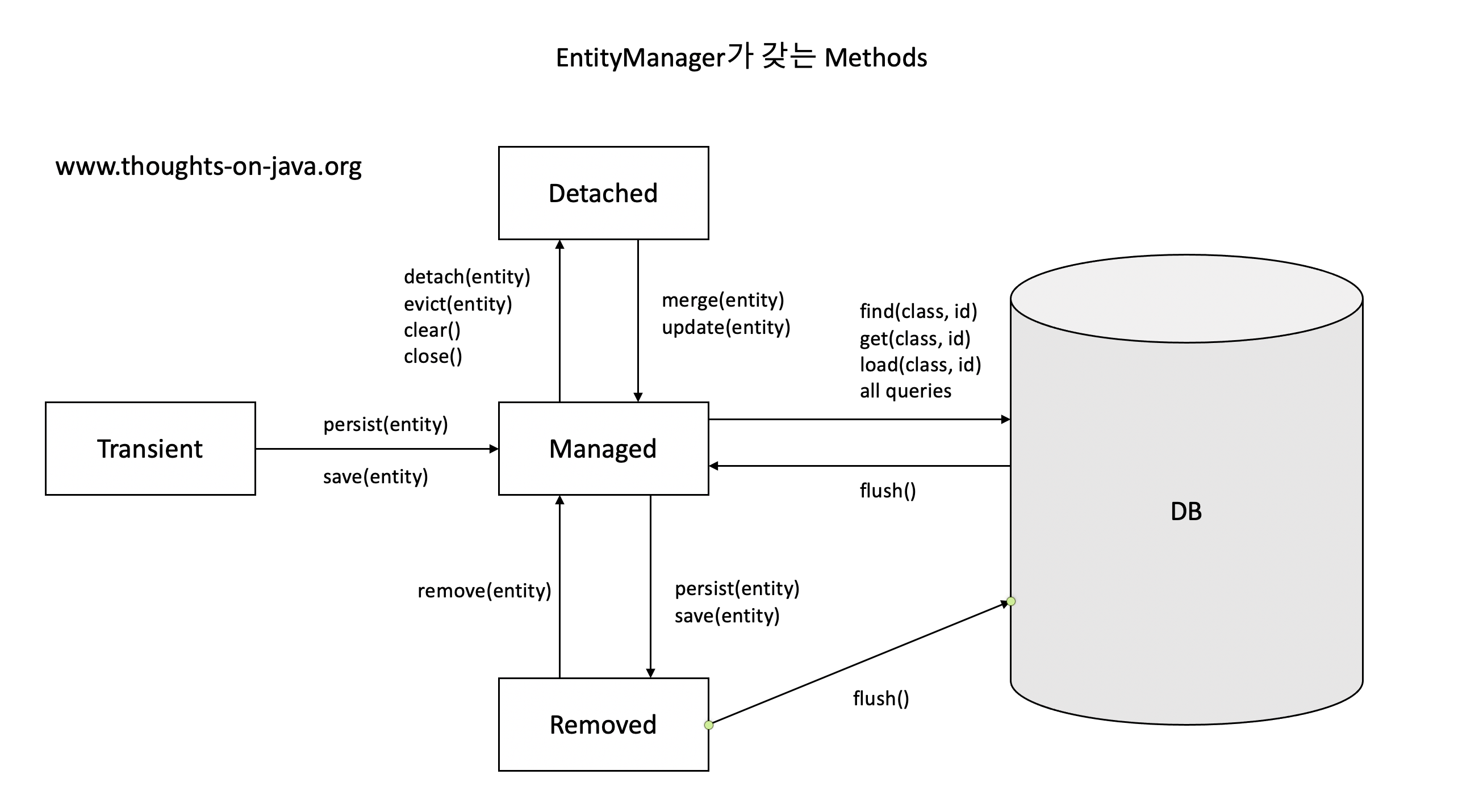
보기만해도 어지럽다.
EntityManager는 말 그대로 Entity를 관리해주는 역할을 한다.
Hibernate, JPA 측에서는 Entity의 Context를 4개로 분리한다.Detached, Managed, Removed, Transient.
Entity는 먼저 Persist(entity)를 통해 영속성 컨텍스트에 올라오고 해당 Entity는 EntityManager 에 관리 받는 상태가 된다.그상태에서 Flush()가 발생하면 DB에 접근하고 그 시점에 SQL이 생성되어 동작하게된다.
즉 쿼리를 개발자가 직접 관리하지 않고 EntityManager에게 맡기게 된다!
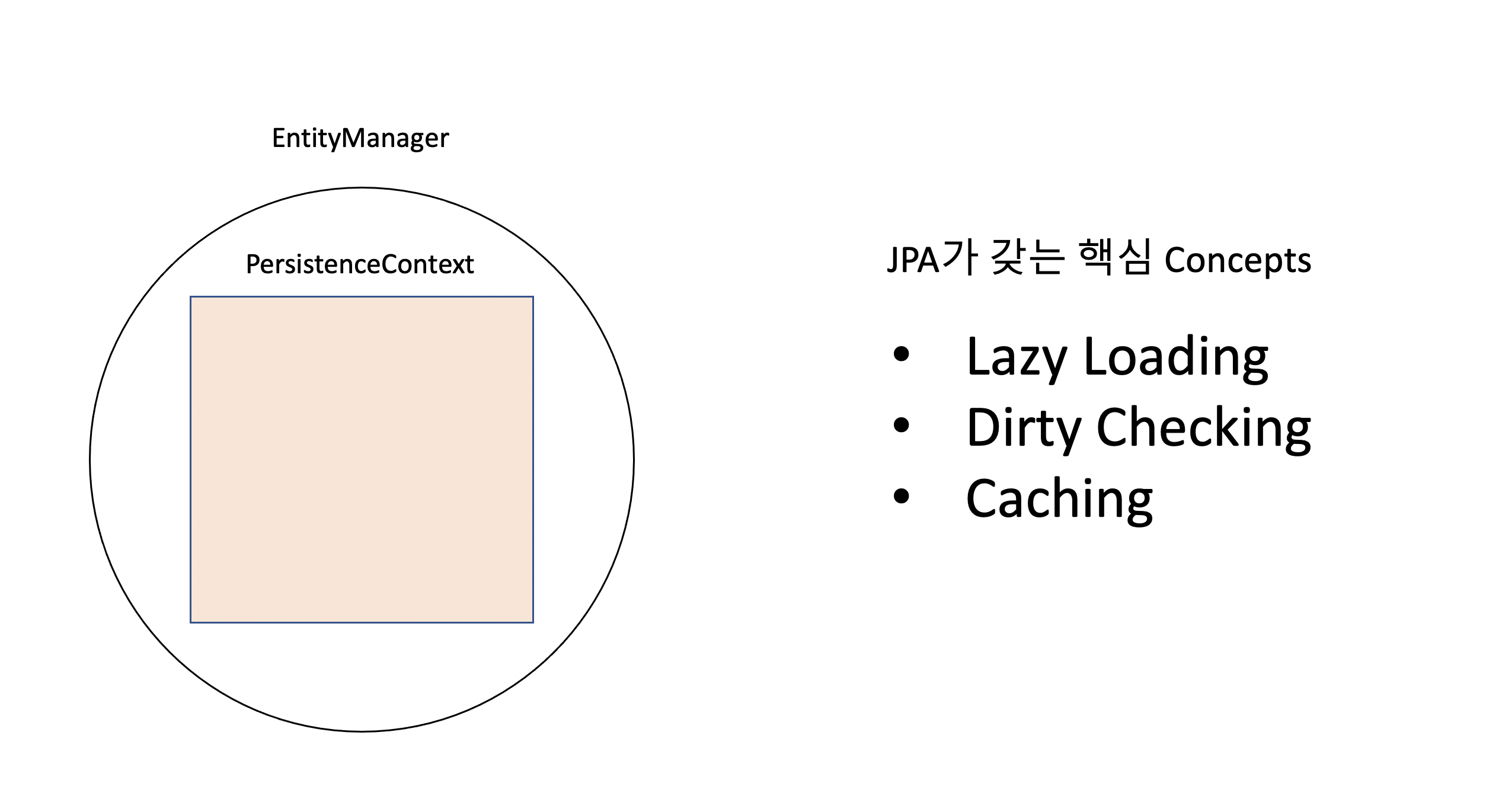
Lazy Loading: 사용 상황에 알맞게 Proxy 객체를 사용해 필요한 정보만 가져오기 위한 Concept
쉽게 말해서 객체의 데이터를 필요할 때만 로딩하는 것을 말하는데,
객체와 연관된 데이터가 많거나, 데이터가 큰 경우 객체를 로딩하는 시간과 메모리 사용을 줄이기 위함이다.
Dirty Checking: 해당 객체의 변경 사항만 관리하는 Concept
객체의 상태가 변경되면 ORM 프레임워크는 변경 내역을 추적하고, 필요한 경우에 데이터베이스에 자동으로 저장한다.
Caching: DB의 Connection을 최소화해 효율적으로 사용할 수 있도록 가능하면 Cache를 사용하는 Concept
Spring Data JPA
- Spring Data 진영에서 만든 JPA
- Core Concpet로 Repository를 제안
EntityManager가 복잡하기 때문에 Spring에서 한번 더 추상화를 해 개발자가 보다 편리하게 이를 이용할 수 있도록 제공한다.
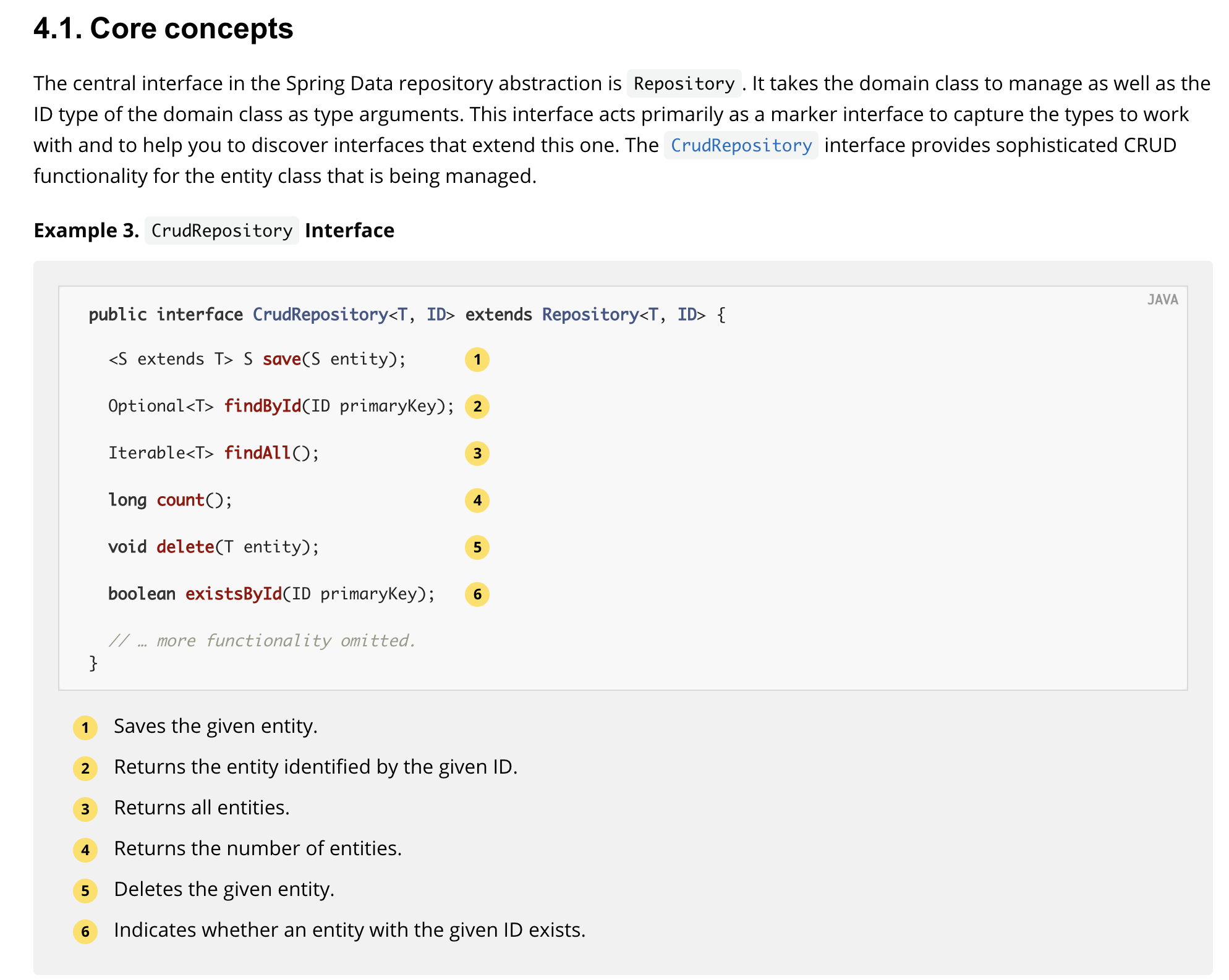
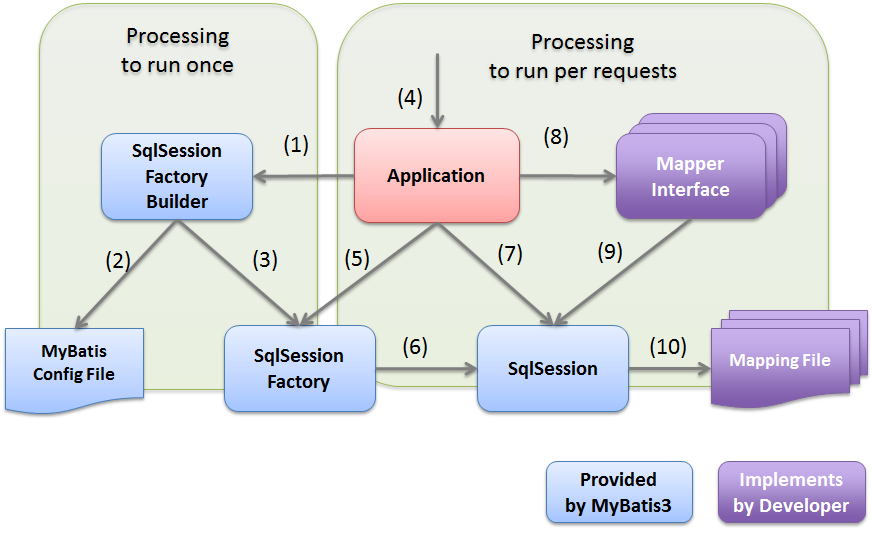
위 사진처럼 interface 형태로 Repository를 제공해 개발자는 이를 가져다 사용하는데, 이를 구현한 클래스 내부 구조를 살펴보면 아래와 같다.
package org.springframework.data.jpa.repository.support;
import ...
public class SimpleJpaRepository<T, ID> implements JpaRepositoryImplementation<T, ID>{
private final EntityManager em;
public Optional<T> findById(Id id){
Assert.notNull(id, ID_MUST_NOT_BE_NULL);
Class<T> domainType = getDomainClass();
if(metadata == null){
return Optional.ofNullable(em.find(domainType, id));
}
LockModeType type = metadata.getLockModeType();
Map<String, Object> hints = getQueryHints().withFetchGraphs(em).asMap();
return Optional.ofNullable(type == null? em.find(domainType, id, hints) : em.find(domainType, id, type, hints));
}
...실제로 JpaRepository 클래스들을 들어가보면 EntityManager를 멤버변수로 갖고 있음을 볼 수 있다. 개발자는 추상화된 인터페이스를 가지고 보다 편리하게 EntityManager를 운용할 수 있다.
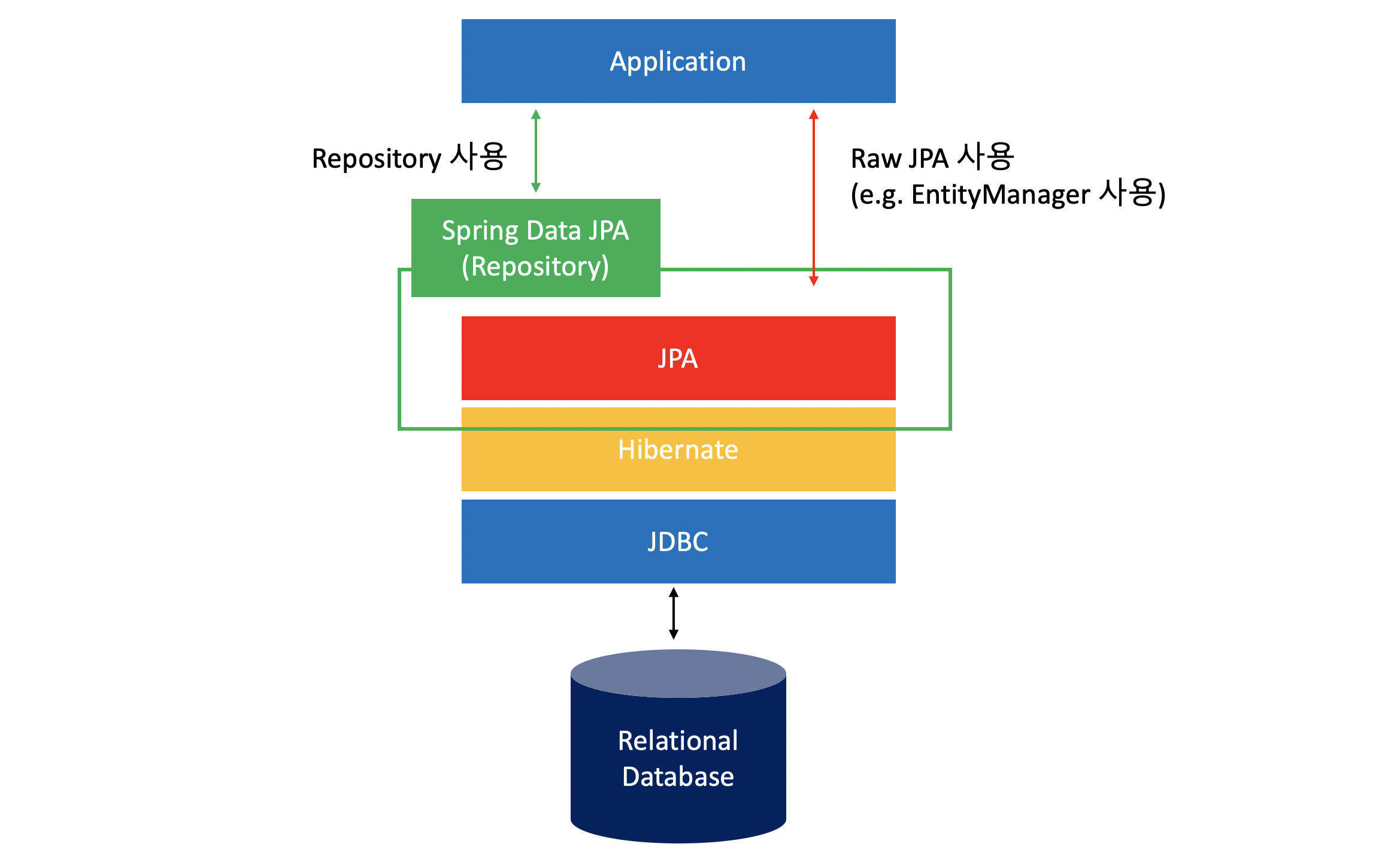
개발자가 Spring Data JPA를 이용한다면 위와 같은 구조로 DB에 접근하는 것이다.
Spring Data JDBC
- Core Concept: Simple
객체지향으로 설계된 프로그램에서 DB에 접근하다보니 너무 많은 기술(EntityManger, Lazy Loading 등) 들이 사용됐다. 이에 DDD 구조로 한꺼번에 Entity를 주고 받는 방식으로 DB에 접근하는 방법을 고안해 냈다.
DDD(Domain-Driven Design) : 프트웨어 개발 방법론 중 하나로, 소프트웨어를 개발할 때 도메인에 집중하여 설계하는 방법
ORM이라고 하기에 살짝 애매한데, 이들은 이렇게 표현을 한다고한다.
"Spring Data JDBC a SImple, Limited Opinionated ORM" - Spring Data JDBC Officials
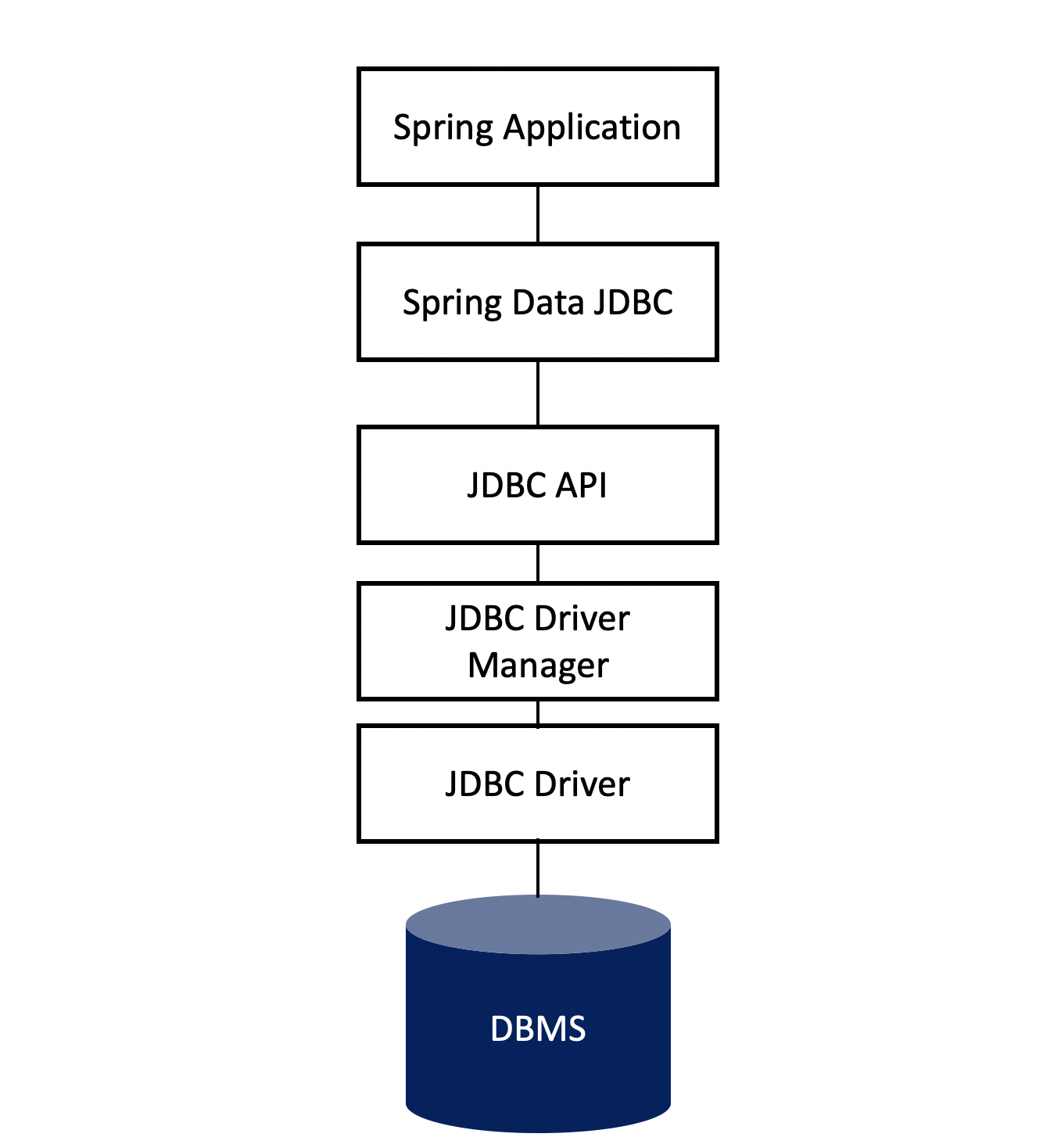
위사진 처럼 Hibernate 와 같은 기술을 사용하지 않고 JDBC API를 직접 구현해서 사용하는 방식으로 동작된다. Spring data이므로 Respository 개념은 가지고 있다.
참고
