이 글은 생활코딩 Machine Learning 1 를 듣고 정리하고 싶은 내용을 적었습니다.
AI/ML에 입문하고 싶은 분들께 정말 추천드리는 강의입니다!
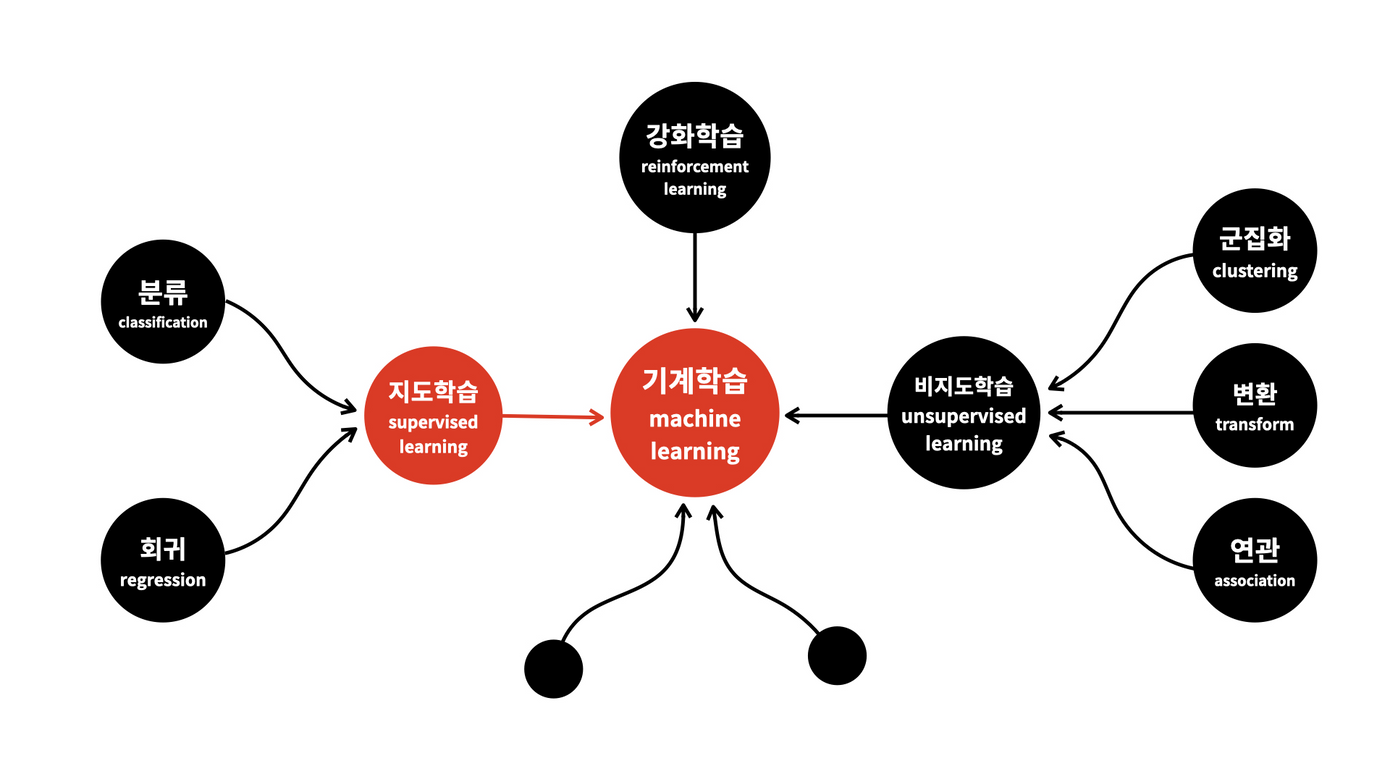
지도학습
지도학습은 역사와 비슷하다.
역사를 알면 어떤 사건이 일어났을 때 그 결과를 예측할 수 있는 것처럼,
과거의 데이터로부터 학습해서 결과를 예측하는데에 주로 사용된다.
독립변수 와 종속변수 를 컴퓨터에게 학습시키면 그 관계를 설명할 수 있는 공식 을 만들어 내는데, 이것을 머신러닝에서는 모델 이라고 한다.
지도학습은 크게 회귀 와 분류 로 나뉜다.
회귀
예측하고 싶은 것이 숫자일 때, 회귀라는 방법을 사용한다.
- 공부시간에 따른 시험점수 예측
- 온도에 따른 레모네이드 판매량 예측
- 역세권, 조망에 따른 집값 예측
- 온실, 기체량에 따른 기온 변화량 예측
- 자동차 속도에 따른 충돌 시 사망 확률 예측
- 나이에 따른 키 예측
- 등등..
분류
예측, 추측하고 싶은 결과가 이름 혹은 문자일 때 분류라는 방법을 사용한다.
- 공부시간에 따른 합격 여부 예측 (합격/불합격)
- X-ray 사진과 영상 속 종양의 크기, 두께에 따른 악성 종양 여부 (양성/음성)
- 품종, 산도, 당도, 지역, 연도에 따른 와인 등급 구분
- 키, 몸무게, 시력, 지병에 따라 현역, 공익, 면제 구분
- 메일 발신인, 제목, 본문내용을 바탕으로 스팸 메일 여부 구분
- 지방함량, 지방색, 성숙도, 육색으로 소고기 등급 측정
양적 데이터와 범주형 데이터
양적 데이터란 얼마나 큰지, 얼마나 많은지, 어느 '정도'인지를 의미하는 데이터
범주형 데이터는 이름!
종속변수가 양적 데이터라면 '회귀'를 사용
종속변수가 범주형 데이터라면 '분류'를 사용
나의 궁금증
분류도 회귀로 풀 수 있는 경우가 있지 않나? 예를 들어 공부시간에 따른 합격을 1, 불합격을 0으로 숫자화시킬 수 있지 않을까? 와인 등급, 현역 공익 면제도 마찬가지로 숫자를 부여하면 되지 않을까? 회귀에서 '숫자'란 '연속적인 수'를 의미하는 것일까??
- 예측으로 '정도'를 나타낼 수 있는지를 기준으로 회귀, 분류를 나눈다면 '정도'를 표현할 수 있는 것이 회귀, 그렇지 않은 것이 분류라고 볼 수 있을 것 같다.
비지도학습
비지도학습에는 군집화, 연관규칙학습 등이 있다.
군집화
군집화란?
비슷한 것들을 찾아 그룹을 만드는 것
분류와는 어떻게 다를까?
⇒ 비슷한 것들을 모아 그룹을 만드는 것이 군집화, 어떤 대상이 어떤 그룹에 속하는지를 판단하는 것이 분류
연관규칙학습
장바구니분석 이라고도 불린다.
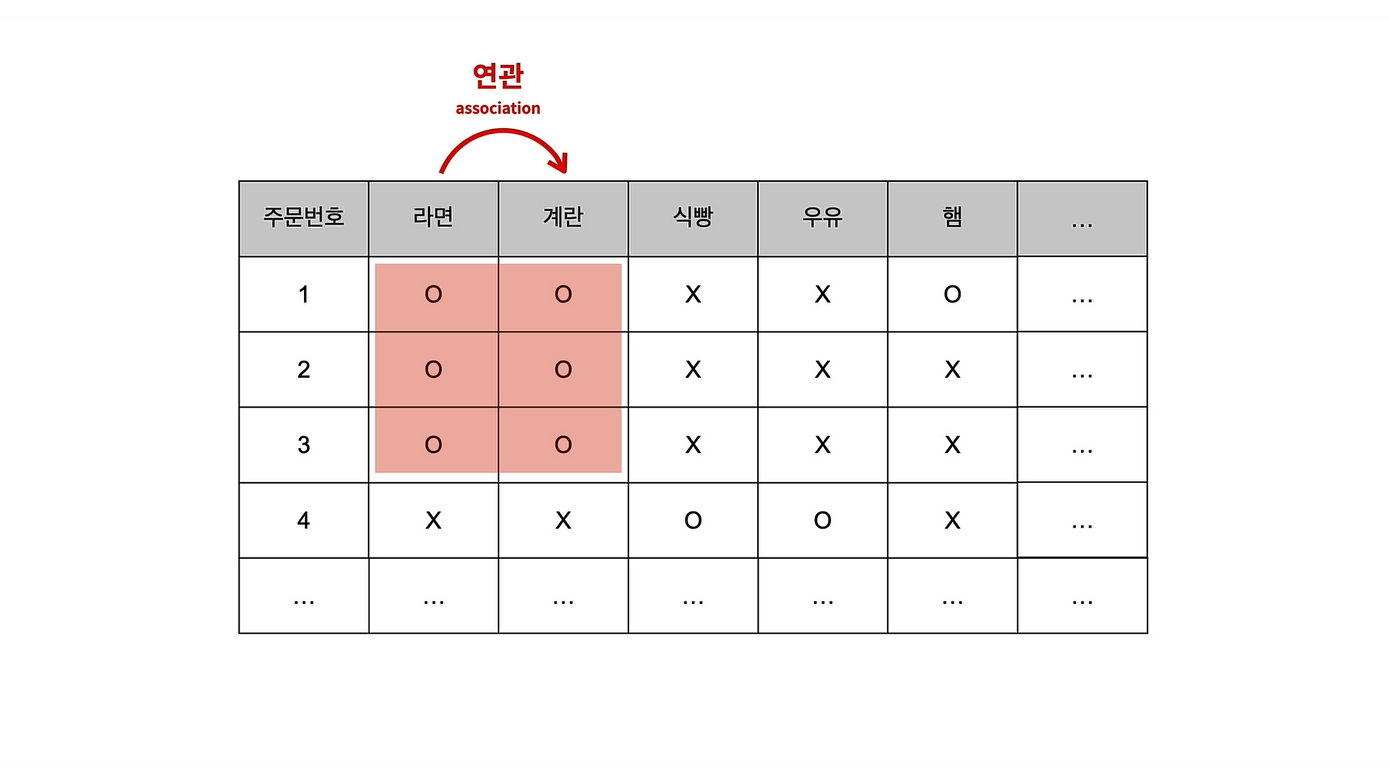
이 표에서 라면을 구입한 사람은 계란도 함께 구입한다는 것을 알 수 있다.
즉, 라면과 계란은 서로 연관성이 높다!
연관성을 파악할 수 있다면 라면만 구입한 고객에게 계란을 추천하거나, 계란만 구입한 고객에게 라면을 추천할 수 있다.
'추천' ⇒ 과거에는 대부분 연관규칙학습으로 구현했다!
연관규칙은 서로 관련있는 특성(열)을 찾아 주는 머신러닝 기법이라고 할 수 있다.
연관규칙분석의 대표적인 알고리즘으로는
- Apriori algorithm
- FP-growth algorithm
- DHP algorithm
추천 시스템 입문하기!
[토크ON세미나] 추천시스템 분석 입문하기 1강 - 추천시스템의 이해 (연관분석, Apriori, FP-Growth) | T아카데미
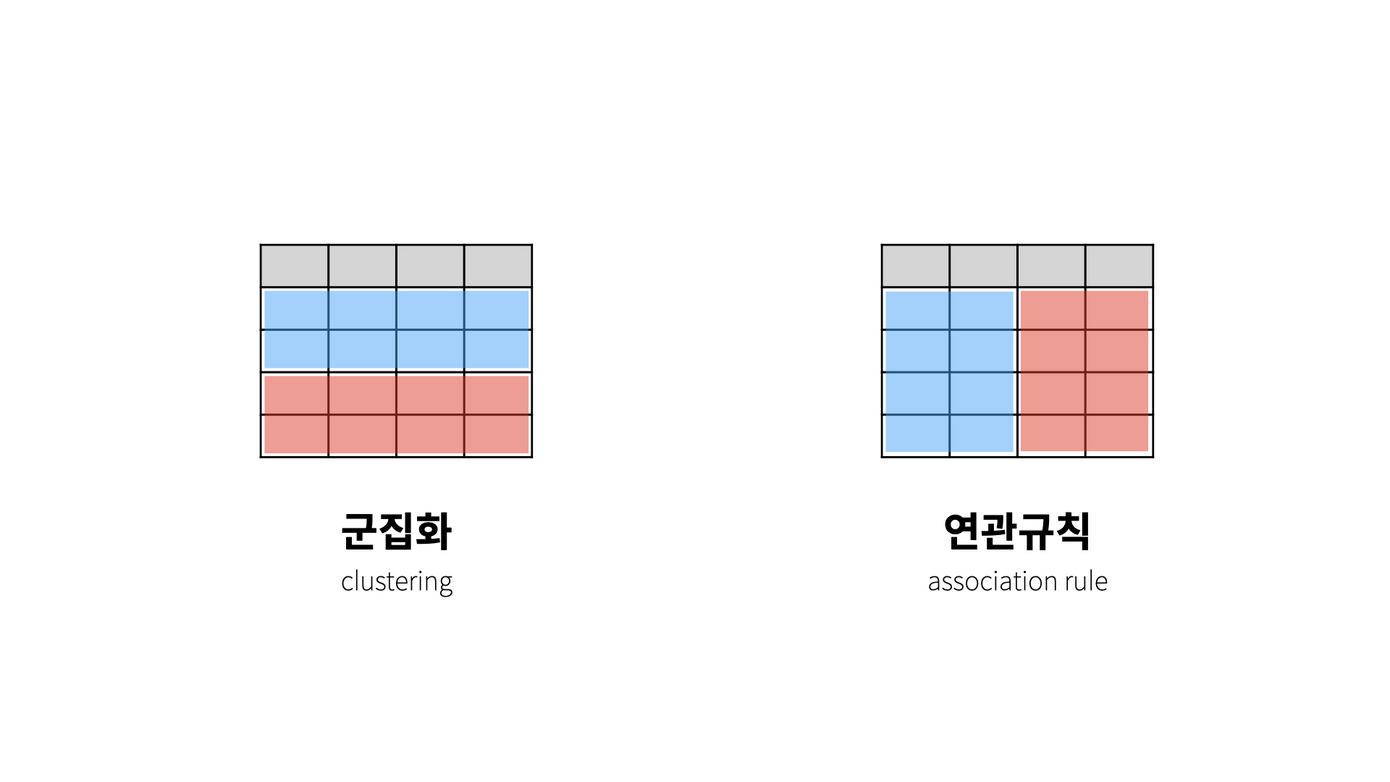
비지도학습과 지도학습
비지도학습은 탐험적이다.
데이터들의 성격을 파악하는 것이 목적이다.
독립변수, 종속변수의 구분이 중요하지 않다.
지도학습은 역사적이다.
과거의 인과관계를 바탕으로 어떤 사건이 발생했을 때 어떤 결과가 초래될지 추축하는 것이 목적이다.
독립변수, 종속변수의 구분이 꼭 필요하다.
강화학습
일단 해보면서 경험을 통해 실력을 키워가는 것
행동의 결과가 자신에게 유리한 것이면 상을 받고, 불리한 것이면 벌을 받음
이 과정을 매우 많이 반복함으로써 더 많은 보상을 받을 수 있는 답을 찾아내는 것!
게임 실력을 키울 때, 강아지를 훈련시킬때와 비슷하다.
게임에 대한 정보가 아무것도 없다면, 게이머는 현재 상태를 관찰하면서 여러 가지 행동을 하고, 그에 따른 보상을 받아들일 것이다. 게이머는 보상 체계를 통해 어떤 행동을 해야 더 큰 보상이 주어지는지 판단할 수 있다.
이것이 게임의 실력자가 되는 과정이다.
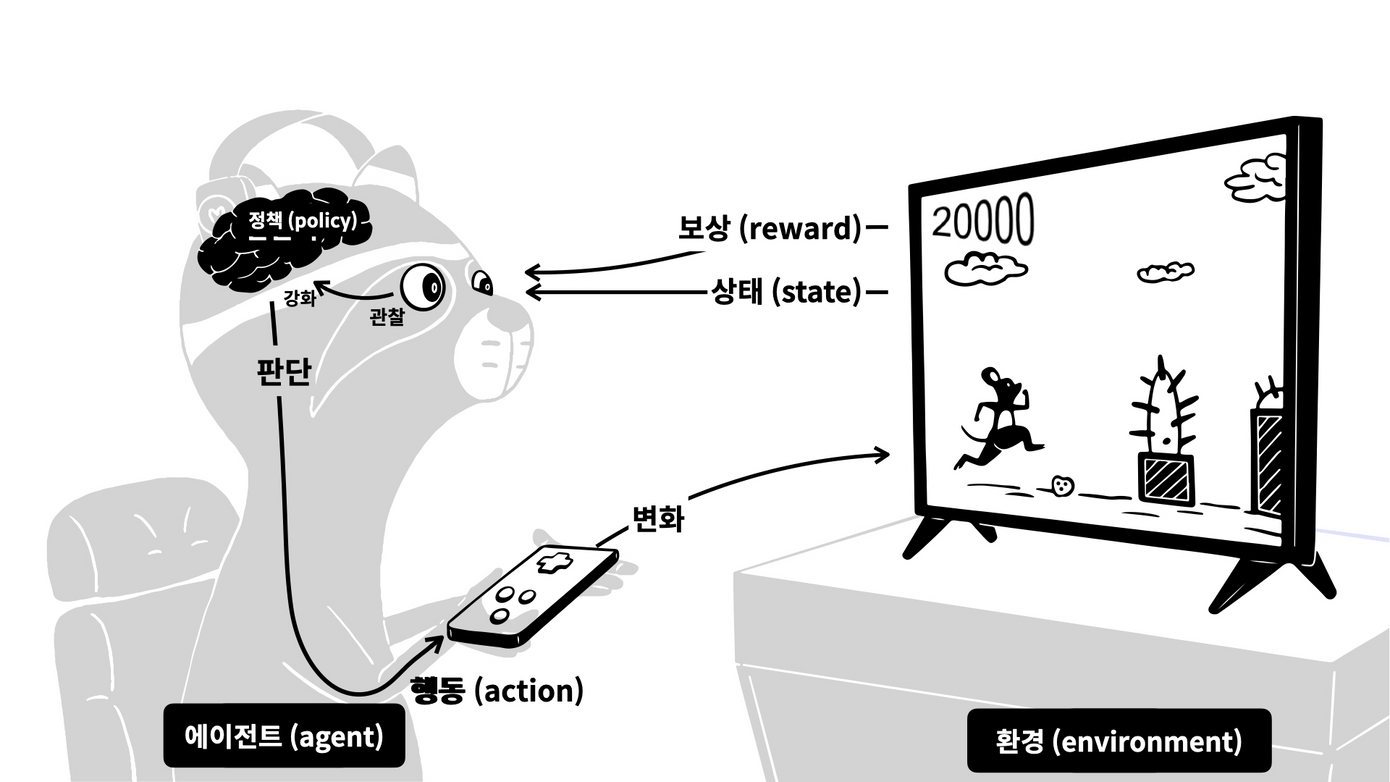
- 게임 → 환경
- 게이머 → 에이전트
- 게임화면 → 상태
- 게이머의 조작 → 행동
- 상과 벌 → 보상
- 게이머의 판단력 → 정책
더 많은 보상을 받을 수 있는 정책을 만드는 것이 핵심!
스스로 수련을 통해 더 좋은 선택을 하는 기능이 필요하다면 강화학습을 공부해보자.
강화학습의 예로는
- 알파고
- 자율주행 기능
- 게임능력 향상
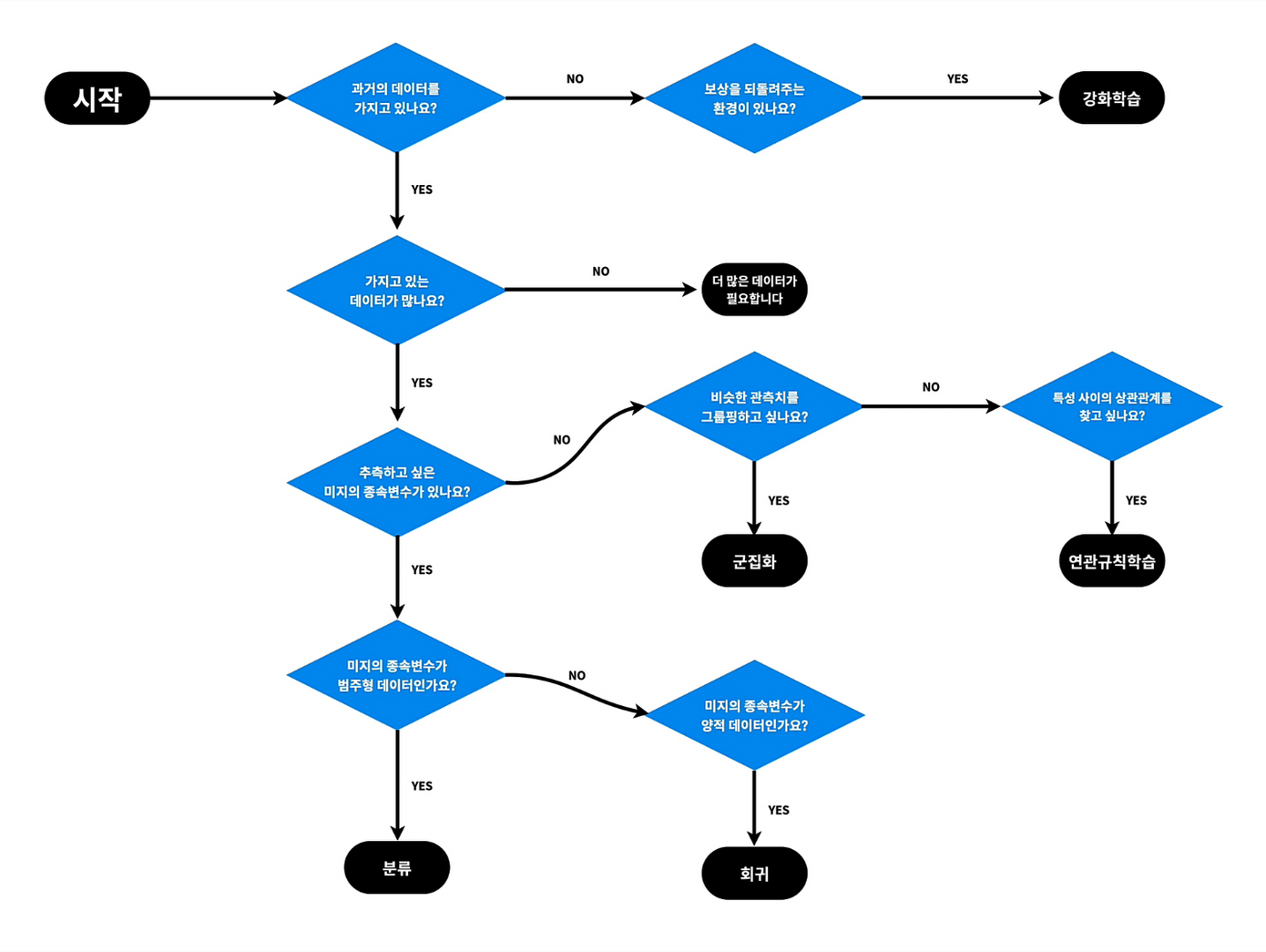
나에게 필요한 머신러닝을 찾아내는 방법 - 머신러닝 지도
수업을 마치며
생산자가 되자!
지금까지 소비라고 생각해 왔던 행동들도 사실은 '생산'이었다.
생산은 아무나 할 수 없는 것이라고 지레 짐작하지 말자!!
머신러닝이라는 부품을 결합해 쓸모있는 완제품을 만들 수 있는 생산자, 엔지니어가 되자!
Next Level
- TensorFlow 를 공부해 보고 싶다. 파이썬부터 공부해 보고, JS 문법 강의를 복습한 다음 TensorFlow.js도 공부해 보고 싶다.
Tensorflow (JavaScript) - 생활코딩
- 다음 단계로는 TensorFlow 이미지 분류, Teachable machine & WEB을 공부해 봐야겠다!
Teachable machine & WEB - 생활코딩
- 추천 시스템을 만들기 위해 연관규칙학습에 사용하는 알고리즘, 구현방법도 공부해 봐야겠다!
