
원문
브라우저의 주요 기능
브라우저의 기능은 선택한 웹 리소스를 서버에서 요청하여 브라우저 창에 표시하는 것 이다.
리소스는 보통 HTML문서 이지만, PDF, 이미지 등 일수도 있다. 이러한 리소스 위치는 사용자가 URI(Uniform Resource Identifier)를 사용하여 지정한다.
브라우저가 HTML을 해석 및 표시하는 방법은 웹 표준 기구인 W3C가 관리하는 HTML 및 CSS 사양에 지정되어 있다. 이 기구가 있기전엔 여러 브라우저들은 각각 사양의 일부만 준수하고 자체 확장을 개발했다. 그로 인해 호환성문제가 항상 발생했다.
브라우저의 공통적 인터페이스
- URI를 삽입하기 위한 주소 표시줄
- 뒤로 및 앞으로 버튼
- 북마크 옵션
- 새로고침, 새로고침 중지 단추
- 홈 버튼
위의 공통적 인터페이스는 W3C에서도, 공식 사양에도 명시 되지 않았지만 규칙이 통일되기 이전부터 공통적으로 사용되었다. 이처럼 개발자들의 다년간의 경험과 서로의 모방을 통해 만들어지기도 한다.
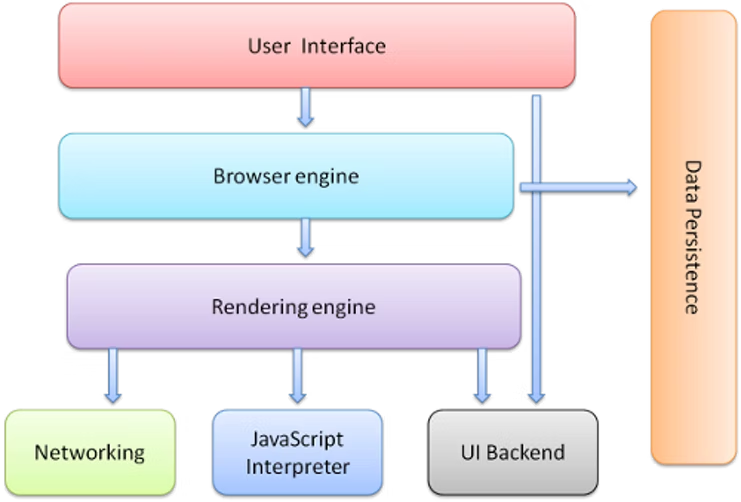
브라우저의 주요 구성요소
-
사용자 인터페이스
- 주소 표시줄, 앞/뒤 버튼, 북마크 메뉴 등
- 요청된 페이지를 볼 수 있는 창을 제외한 브라우저의 모든 부분 표시
-
브라우저 엔진
- UI와 렌더링 엔진 간의 작업 수행
-
렌더링 엔진
- 요청된 콘텐츠 표시
- 요청 콘텐츠가 HTML인 경우 이 엔진은 HTML 및 CSS를 해석하고 해석된 콘텐츠를 화면에 표시
-
네트워킹
- HTTP requests의 경우 플랫폼마다 다른 구현을 시켜준다.
-
UI 백엔드
- 창과 같은 기본 위젯을 그리는데 사용
- 범용 인터페이스를 제공.
- UI백엔드 뒤에는 운영체제 유저 인터페이스 메소드를 사용
-
자바스크립트 인터프리터
- 자바스크립트 코드 해석 및 실행
-
데이터 스토리지
- 지속성 레이어 (persistanch layer)
- 이로 인해 쿠키와 같은 모든 종류의 데이터를 로컬로 저장할 수 있다.
렌더링 엔진
브라우저 화면에 요청된 콘텐츠를 표시하는 역할을 한다.
렌더링 엔진은 HTML이 아니더라도 XML,PDF등 여러 데이터를 표시할 수 있지만, 여기서는 주로 CSS를 사용하여 포맷된 HTML 및 이미지 표시에 초첨을 맞춘다.
브라우저 별 렌더링 엔진
- Firefox: Gecko
- Safari: WebKit
- Chrome,Opera: Blink(Webkit)
이 중 주요하게 쓰이는 Webkit은 Linux플랫폼 엔진으로 시작되어 Mac과 Window를 지원하도록 애플에서 수정한 오픈 소스 렌더링 엔진이다. webkit.org
렌더링 엔진의 주요 개념
렌더링 엔진은 네트워크 계층에서 요청된 문서(8kb의 청크)의 내용을 가져온다.
그 후 렌더링 엔진의 기본 흐름은

이렇다고 한다.
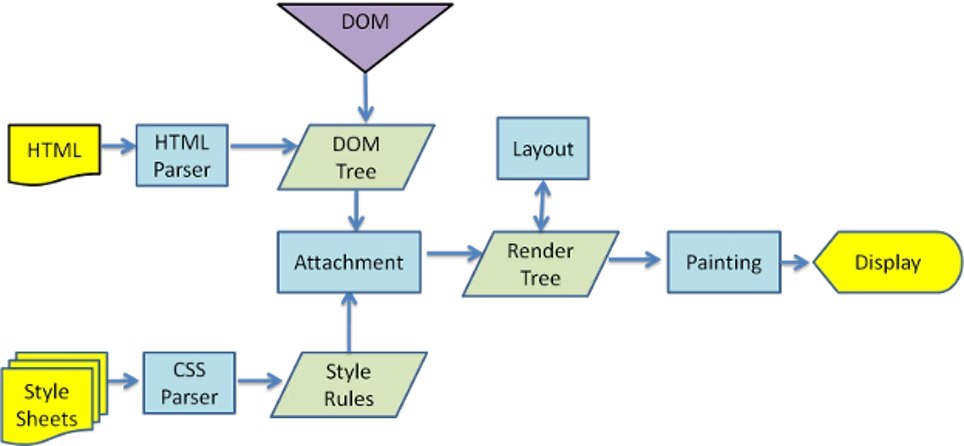
렌더링 엔진 동작 순서
- HTML문서를 구문 분석
- HTML요소를 DOM트리 로 변환
- CSS 및 스타일 요소 데이터 해석
- 렌더 트리 생성
- 렌더트리의 화면 좌표를 읽어 레이아웃 생성
- 만들어 둔 렌더트리 통과
- DOM tree에 속한 DOM 노드들을 UI백엔드 레이어를 통해 화면에 그려냄
=> 렌더트리: 색상 및 치수와 같은 시각적 속성이 있는 직사각형
(아래는 DOM트리와 Style, 좌표가 결합된 Render Tree의 예)
(Webkit의 동작 흐름)
파싱
문서를 파싱(해석)한다는 것은 코드를 사용할 수 있는 구조로 변환하는 것을 의미한다. 파싱 결과는 일반적으로 문서 구조를 나타내는 노드의 트리이다. 이를 parse tree혹은 syntax tree라고 한다.
Parser - Lexer 조합
파싱은 어휘적 분석과 부문 분석 두 가지 하위 프로세스로 나뉜다.
어휘 분석은 입력을 토큰(작은 조각)으로 나누는 과정 이며 여기서 토큰은 우리가 사전을 볼때 나오는 단어 들과 같은 개념이다.
문법 분석은 들여쓰기, 띄어쓰기 등 구문적인 규칙을 적용하는 것이다.
정리하면, Parser는
Lexer: 입력을 유효한 토큰으로 분할
Syntax Parser: 문법 분석 트리 구성
로 두가지 작업으로 나뉜다.
(내용 추가 예정)
