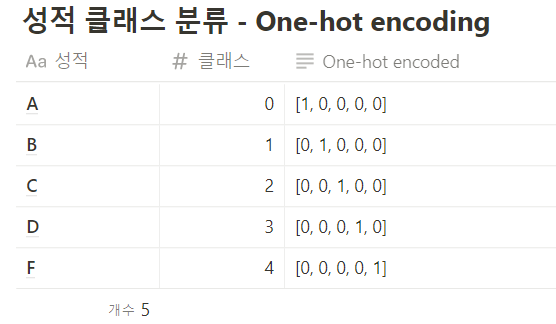
다항논리회귀(Multinomial logistic regression)
one-hot-encoding = 출력값을 컴퓨터가 인식하기 쉽게 하는 방법
여러 개의 항을 0과 1로만 표현
원핫 인코딩을 만드는 방법
- 클래스(라벨)의 개수만큼 배열을 0으로 채운다.
- 각 클래스의 인덱스 위치를 정한다.
- 각 클래스에 해당하는 인덱스에 1을 넣는다.
단항논리회귀의 sigmoid 대신 Softmax 사용
단항논리회귀 = sigmoid로 0이냐 1이냐만 구분 > CrossEntropy 사용 > 확률분포 그래프의 차이를 계산하여 최소화
CrossEntropy를 사용
다항논리회귀 = 다항을 Softmax를 사용 > CrossEntropy > 화귤ㄹ분포 그래프의 차이를 계산하여 최소화
클래스·라벨의 수, sigmoid냐 softmax냐 만 다름.
머신러닝 모델
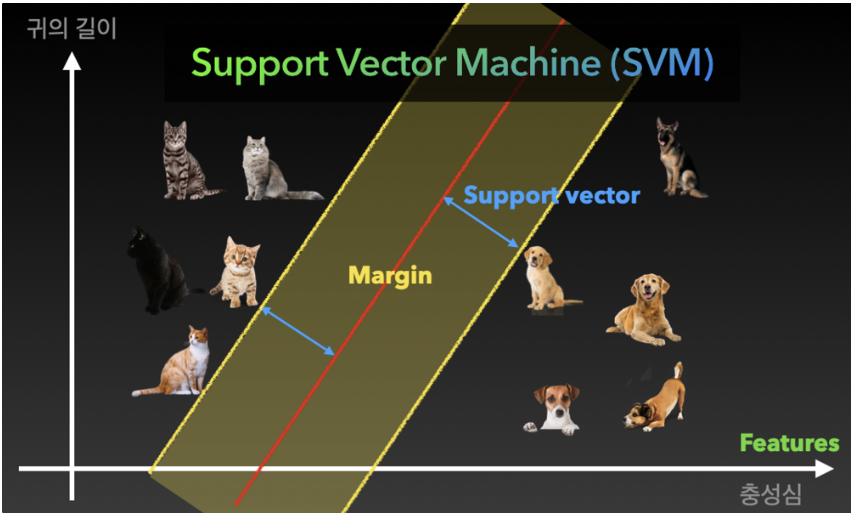
Support vector machine(SVM)
구분하는 문제를 푸는 것은 분류 문제(Classification problem)이고 분류 문제를 푸는 모델을 분류기(Classifier)라고 한다.
구분을 하기 위한 각 그래프의 축을 Feature
Feature에 따라 나누는 모델을 만들기 위해 그래프 상에서 한 개의 직선을 긋는다고 했을 때,
각각의 구분 값의 거리가 최대가 되는 선이 나누기 위한 최적의 모델.
그 선이 Support vector이고 이것의 거리가 Margin이다.
Margin이 넓어지도록(그래야 더 정확하게 분류하는 것 이니까) 모델을 학습시켜야 한다.
전처리(Preprocessing)
= 넓은 범위의 데이터 정제 작업.
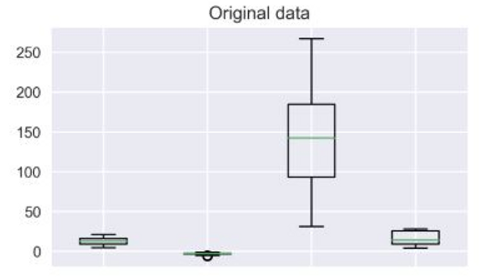
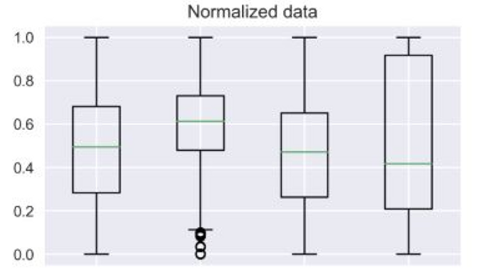
1. 정규화(Normalization)
데이터를 0과 1사이의 범위를 가지도록 만듬.
같은 특성의 데이터 중에서 가장 작은 값을 0으로 만들고, 가장 큰 값을 1로 만들어 정규화 시킴.
2.표준화(Standardization)
데이터의 분포를 정규분포로 바꿔줌.
즉 데이터의 평균이 0이 되도록하고 표준편차가 1이 되도록 한다.

가보자고