이 글은 개발 공부하는 "학생"의 글입니다. 참고용으로만 활용해주시길 바랍니다. 혹시 오류를 찾으셨다면 답글달아주시면 정말 감사드리겠습니다:)
공부한 곳 : 김영한 스프링 DB 핵심강의1
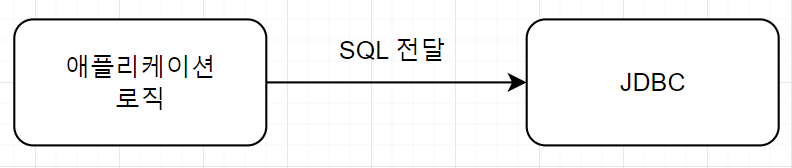
이전 글에서 언급했듯이, JDBC는 한계점을 지녔다.
- 데이터베이스마다 SQL이 달라서 SQL부분을 바꿔줘야 했다.
- 추가로, 1997년에 출시된 오래된 기술로서, 사용법이 복잡하다
=> 이러한 바탕에서 나온 것이 SQL Mapper와 ORM기술이다.
JDBC만 직접 사용
SQL Mapper
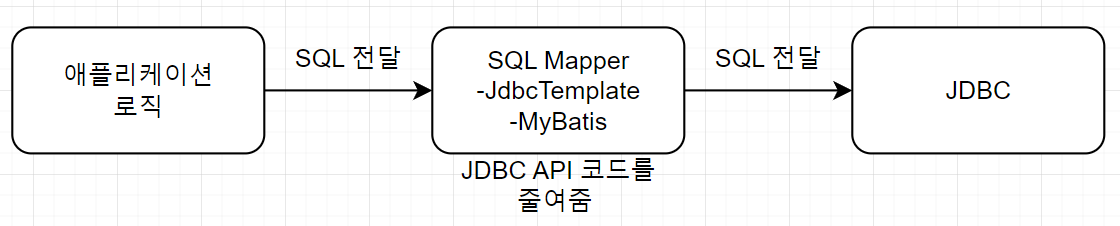
- 객체와 RDBMS의 데이터를 개발자가 작성한 SQL로 매핑시켜주는 프레임워크
- 개발자는 SQL을 직접 작성하고, SQL Mapper는 SQL문을 실행하여 얻은 데이터를 객체로 매핑시켜줌
- JDBC API 사용코드를 많이 줄일 수 있음
- MyBatis, JdbcTemplate
장점
- SQL을 안다면, 금방 프로젝트에 적용할 수 있음
- SQL의 세부사항들을 변경하기 편함
단점
- 여전히 SQL을 써야함(CRUD)
- DBMS에 종속적임
- DBMS 변경시 SQL문의 재사용이 어려움
- 2개 이상의 DBMS 지원시 유지 보수가 어려움
ORM(Object-Relation Mapping)
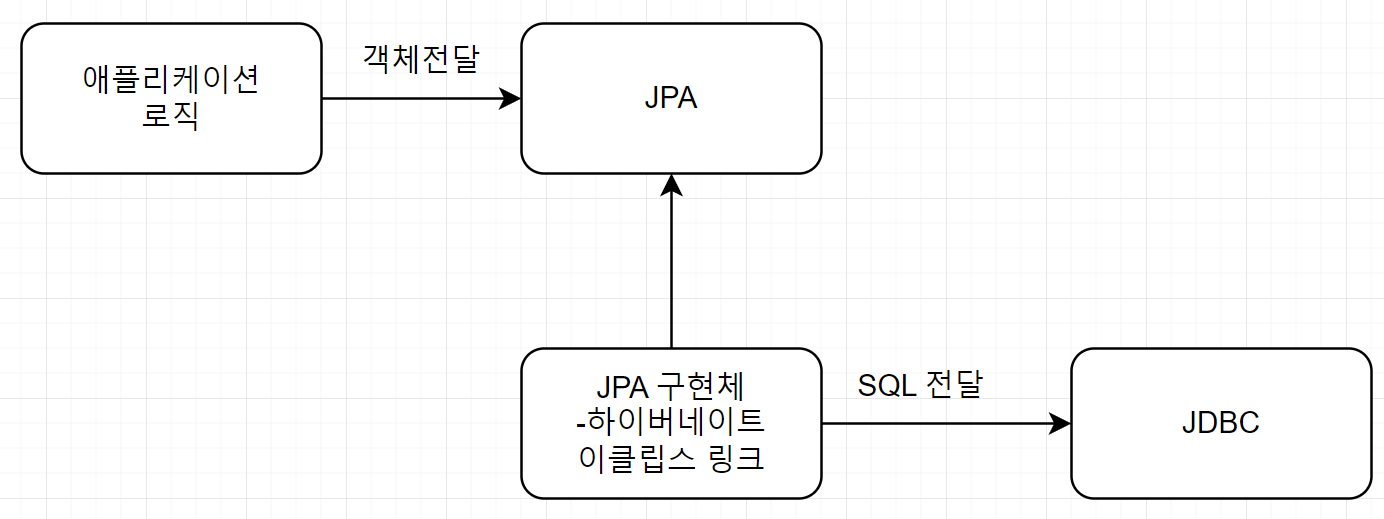
- 객체를 관계형 데이터베이스의 테이블과 자동으로 매핑시켜주는 프레임워크
- 설정된 객체 간의 관계를 바탕으로 자동으로 SQL을 생성시켜주고, 실행함
=> 따라서 SQL을 직접 작성할 필요가 없다. - JPA, 하이버네이트, 이클립스링크
장점
- 반복적인 CRUD SQL을 알아서 처리해줌
- 객체 모델링과 관계형 DB 사이의 차이점을 해결해줌
- 객체 중심의 개발 -> 생산성, 유지보수 good
- SQL을 사용하지 않다보니, DB에 독립적이다.
-> DB가 바뀌어도 코드가 바뀌지 않는다!
단점
- 높은 러닝커브
- 잘못 적용시 속도저하 문제
- 복잡한 SQL은 사용하지 못할 수도 있다.
-> 이 점은 네이티브 SQL로 해결됨
위의 모든 기술 아래에 JDBC가 존재한다.
JDBC의 기본 동작 원리를 알아두자!
cf) JPA의 높은 러닝커브에 대한 추가 내용
- JPA를 활용하는 것 자체는 배우는데에 러닝커브가 크진 않다.
- 하지만 영속성 등 깊은 내용을 익히는데에는 러닝커브가 있다.
- 문제 상황에서는 결국 깊은 내용을 알아야 하기에 러닝커브가 존재.
- 물론 여러 DB의 SQL을 배워야하는 러닝커브를 줄여준다는 장점은 존재한다.

배우는 게 너무 즐거운 개발자