
*6차 세미나 과제로 제출했던 내용을 공유하면 좋을 것 같아 포스트합니다 :)
#Spring Security
Spring Security Structure
기본 로그인 폼으로 구현 시

- 서블릿 필터
- 이들로 구성된 필터 체인
- HttpRequest - 사용자가 로그인 정보와 함께 인증 요청
- AuthenticationFilter - 요청을 가로채고, 가로챈 정보를 통해 UsernamePasswordAuthenticationToken 객체 생성
*사용자가 입력한 데이터를 기반으로 (현 상태는 미검증 Authentication의 상태) - ProviderManager (AuthenticationManager 구현체)에게 UsernamePasswordAuthenticationToken 객체를 전달
- AuthenticationProvider에 UsernamePasswordAuthenticationToken 객체를 전달
- 실제 DB로부터 사용자 인증 정보를 가져오는 UserDetailService에 사용자 정보를 넘겨줌
- 넘겨받은 정보를 통해 DB에서 찾은 사용자 정보인 UserDetails 객체를 생성
- AuthenticationProvider는 UserDetails를 넘겨받고 사용자 정보와 비교
- 인증이 완료되면, 사용자 정보를 담은 Authentication 객체를 반환
- 최초의 AuthenticationProvider에 Authentication 객체가 반환됨
- Authentication 객체를 SecurityContext에 저장
스프링 시큐리티는 서블릿 필터의 집합이라고 할 수 있다. API가 실행될 때마다 사용자를 인증해주는 부분을 구현해야 하는데, 이는 스프링 시큐리티를 이용해서 토큰 인증을 위해 컨트롤러 메서드의 첫 부분마다 인증 코드를 작성하는 방식으로 쉽게 구현이 가능하다.
스프링 시큐리티는 인증과 인가를 위해 다양한 기능을 제공하지만, 구현에 필요한 부분인 서블릿 필터만 간단히 설명하자면 서블릿 필터는 서블릿 실행 전에 실행되는 클래스로 스프링이 구현하는 디스패처 서블릿이 실행되기 전에 항상 실행되는 것을 말한다. 개발자는 서블릿 필터를 구현하고 서블릿 필터를 서블릿 컨테이너가 실행하도록 설정만 해주면 된다. 서블릿 필터는 구현된 로직에 따라 원하지 않는 HTTP 요청을 걸러낼 수 있으며, 서블릿 필터가 전부 살아남은 HTTP 요청은 서블릿으로 넘어와 컨트롤러에서 실행된다.
⭐ UserDetailsService와 UserDetails
실질적인 인증 과정은 사용자가 입력한 데이터(ID,PW)와 UserDetailsService의 loadUserByUsername() 메서드가 반환하는 UserDetails 객체를 비교함으로써 동작한다. 따라서 UserDetailsService와 UserDetails 구현을 어떻게 하느냐에 따라 인증의 세부 과정이 달라진다.
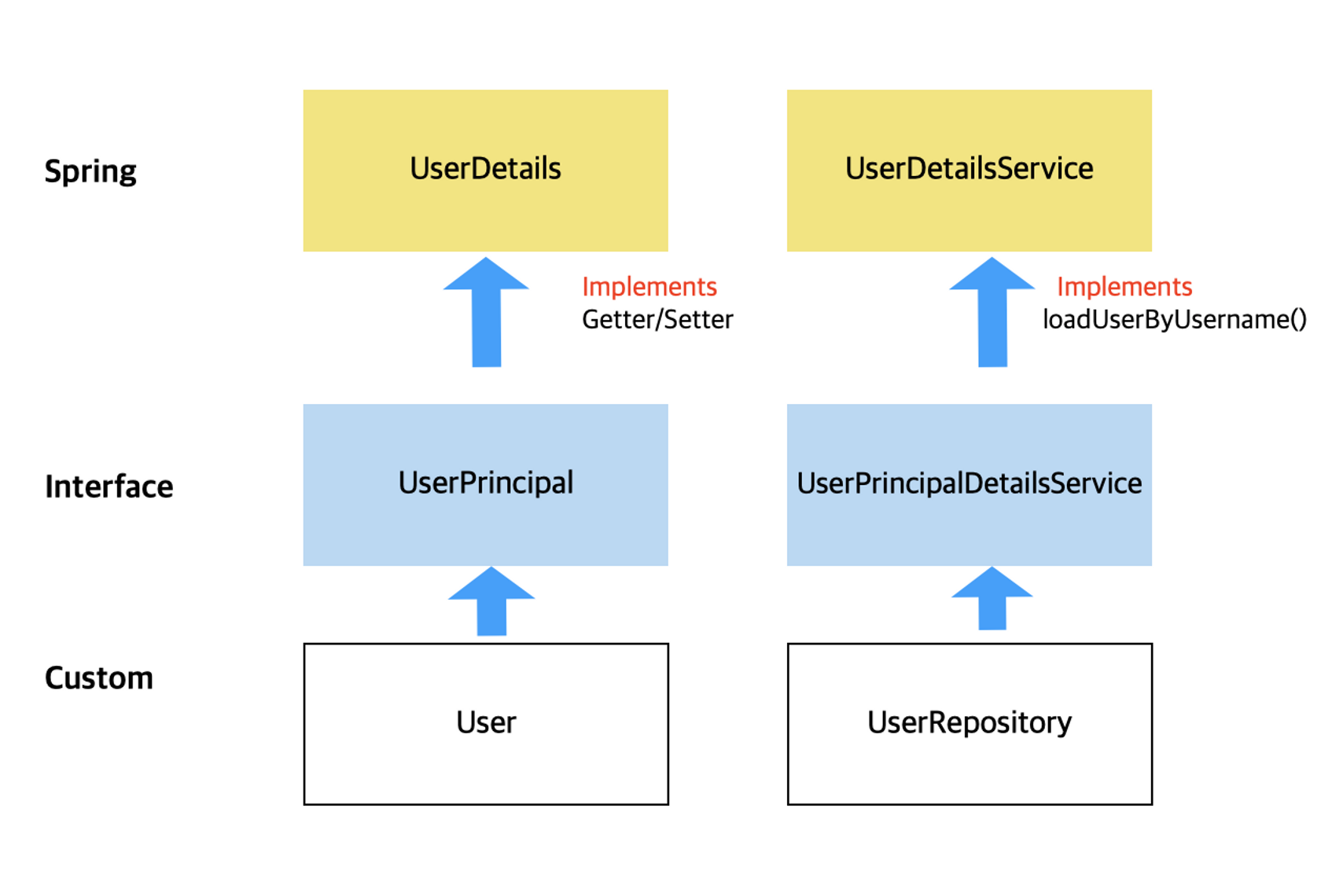
User Entity → UserDetails 구현
UserService → UserDetailsService 구현
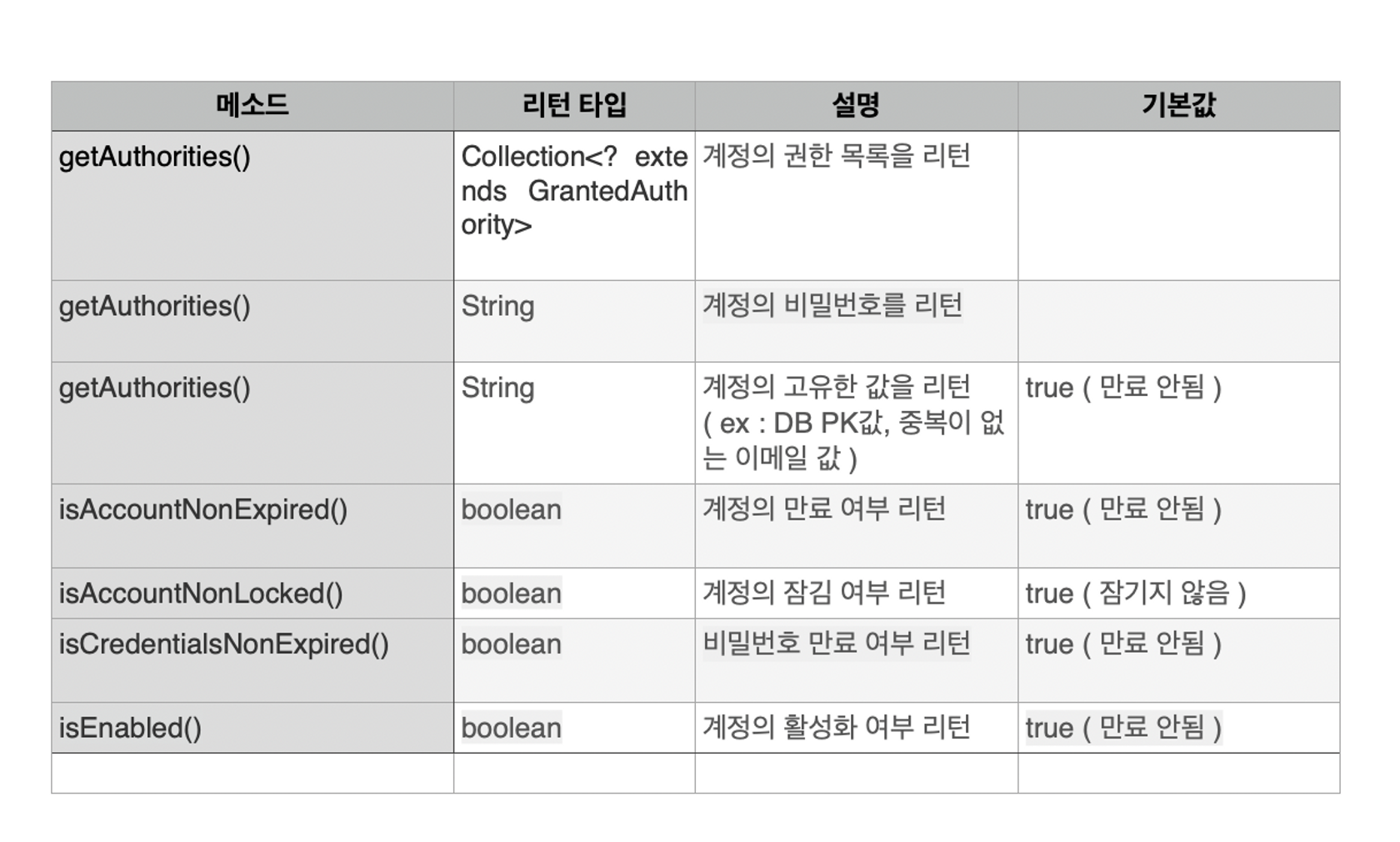
UserDetails
Spring Security에서 User Entity 역할을 하며, 사용자의 정보를 담는 인터페이스
UserDetailsService
Spring Security에서 UserRepository 역할을 하며, 사용자의 정보를 가져오는 인터페이스
- 메소드 : loadUserByUsername
UserRepository를 생성자로 주입받아, User 정보를 DB에서 가져온다. DB에서 가져온 User 정보는 UserDetails를 구현한 User Entity에서 Spring Security로 전달되며, Spring Security의 기능들을 사용할 수 있게 된다.
Spring Security에서 동작하는 기본 필터


두 필터의 상위 클래스는 AbstractAuthenticationProcessingFilter이다. 스프링 시큐리티는 AbstractAuthenticationProcessingFilter를 호출하고, 로그인 방식에 따라 구현체인 UsernamePasswordAuthenticationFilter와 OAuth2LoginAuthenticationFilter가 동작하는 방식이다.
소셜 로그인을 구현하기 위해 OAuth 2.0 로그인을 사용한다면, OAuth2LoginAuthenticationFilter가 호출된다. (기본 로그인 시에는 UsernamePasswordAuthenticationFilter)
주요 키워드
- AuthenticationSuccessHandler
- AuthenticationFailureHandler
- UserDetailsService
- UserDetails
- AuthenticationEntryPoint
- AccessDeniedHandler
SecurityConfig
HttpSecurity : 시큐리티 설정을 위한 오브젝트 → 빌더를 제공하는 이 오브젝트는 빌더를 이용해 cors, csrf, httpBasic, session, authorizeRequests 등 다양한 설정을 할 수 있다. web.xml 대신 HttpSecurity로 시큐리티 관련 설정을 하는 것이다.
*인증, 인가에 관한 추가 학습 내용
OAuth 2.0
OAuth(OpenID Authentication) : 타사의 사이트에 대한 접근 권한을 얻고 그 권한을 이용하여 개발할 수 있도록 도와주는 프레임워크로, 인터넷 사용자들이 비밀번호를 제공하지 않고 다른 웹사이트 상의 자신들의 정보에 대해 웹 사이트나 애플리케이션의 접근 권한을 부여할 수 있는 공통적인 수단으로서 사용되는, 접근 위임을 위한 개방형 표준이다.
→ 구글, 카카오, 네이버 등의 사이트에서 로그인을 하면 직접 구현한 사이트에서도 로그인 인증을 받을 수 있도록 되는 구조이다.
ex. 구글에서 로그인 시, 개발한 웹 사이트에 구글 ID, PW를 그대로 전달해주는 게 아니라 Access Token을 발급 받고 그 토큰을 기반으로 원하는 기능을 구현하는 방식이다.

Access Token은 로그인을 하지 않고 인증을 할 수 있도록 해주는 인증 토큰 정도의 개념으로, 유저가 직접 개발한 웹 사이트에서 Access Token을 통해 구글 앱에 접근하고 사용할 수 있게 되는 것이다. 이때 Access Token을 발급 받기 위한 일련의 과정들을 인터페이스로 정의해둔 것이 바로 OAuth이다. OAuth에서 중요한 용어는 다음과 같다.
- Resource Owner : 개인정보의 소유자 → 웹 사이트 유저 *resource = 개인정보
- Client : 제3의 서비스로부터 인증을 받고자 하는 서버 → 직접 개발한 웹 사이트
*클라이언트라는 이름은 client가 Resource Server에게 필요한 자원을 요청하고 응답하는 관계라서 그렇다. - Resource Server : 사용자의 개인정보를 저장하고 있는 서버 → 구글, 페이스북, 카카오 등의 회사 서버. Client는 Token을 이 서버로 넘겨 개인정보를 응답 받을 수 있다.
타사의 서비스를 이용하기 위한 신청 방식은 구글, 카카오, 네이버, 페이스북 등 각각의 방식이 조금씩 다르지만, 공통적으로 ID, PW, 본인 인증 방법은 포함하고 있다. 각 사이트의 개발자 문서를 참고하여 쉽게 등록하고 발급받을 수 있다.
- Client ID : Resource Server에서 발급해주는 ID → 웹 사이트에 구글이 할당한 ID를 알려주는 것
- Client Secret : Resource Server에서 발급해주는 PW → 웹 사이트에 구글이 할당한 PW를 알려주는 것
- Authorized Redirect URI : Client 측에서 등록하는 URL로, Resource Server만 갖는 정보. client에 권한을 부여하는 과정에서 나중에 Authorized Code를 전달하는 통로이다. 만약 이 URI로부터 인증을 요구하는 것이 아니라면, Resource Server은 해당 요청을 무시한다.
- Authorization Server : 권한을 부여(인증에 사용할 아이템을 제공)해주는 서버
- 사용자는 이 서버로 ID, PW를 넘겨 Authorization Code를 발급 받을 수 있다.
- Client는 이 서버로 Authorization Code를 넘겨 Token을 발급 받을 수 있다.
- Access Token : 자원에 대한 접근 권한을 Resource Owner가 인가하였음을 나타내는 자격증명
- Refresh Token : Client는 Authorization Server로부터 Access Token(비교적 짧은 만료기간을 가짐)과 Refresh Token(비교적 긴 만료기간을 가짐)을 함께 부여 받는다.
-
Access Token은 보안상 만료기간이 짧기 때문에 얼마 지나지 않아 만료되면 사용자는 로그인을 다시 시도해야 한다.
-
Refresh Token이 있다면, Access Token이 만료될 때 Refresh Token을 통해 Access Token을 재발급 받아 재 로그인 할 필요가 없게끔 한다.
Refresh Token의 발급 여부와 방법 및 갱신 주기 등은 OAuth를 제공하는 Resource Server마다 상이하다. Access Token은 만료 기간이 있으며, 만료된 Access Token으로 API를 요청하면 401 에러가 발생한다. Access Token이 만료되어 재발급받을 때마다 서비스 이용자가 재 로그인하는 것은 다소 번거롭기 때문에, 보통 Resource Server는 Access Token을 발급할 때 Refresh Token을 함께 발급한다. client는 두 Token을 모두 저장해두고, Resource Server의 API를 호출할 때는 Access Token을 사용한다. Access Token이 만료되어 401에러가 발생하면, Client는 보관중이던 Refresh Token을 보내 새로운 Access Token을 발급받게 되어 로그인 인증을 유지할 수 있게 된다.
-
- scope : Resource Server에서 사전에 사용가능하도록 미리 정의한 기능 → 페이스북, 구글 등 로그인 이후 그 서비스에서 사용할 수 있는 모든 기능
인증 종류
-
Authorization Code Grant : 권한 코드 승인 방식
서버 사이드에서 인증을 처리할 때 이용하는 방식으로, Resource Owner로부터
-
Implicit Grant : 암시적 승인 방식
-
Password Credentials Grant : 비밀번호 자격 증명 방식
-
Client Credentials Grant : 클라이언트 자격 증명 방식
예시 동작
Client (직접 개발한 웹 사이트)가 Resource Server에 등록이 완료되었다면, 이제 Access Token을 발급받을 수 있는 상태이다. 구글을 예시로, 유저 A가 웹 사이트에서 특정 기능을 이용하기 위해 로그인이 요구되고, 구글 인증 Access Token을 받기 위해 구글 로그인 링크로 연결된다.
예시 링크 - https://accounts.google.com/?client_id=123&scope=profile,email&redirect_uri=http://localhost
위 링크의 쿼리 스트링을 보면, Client ID는 123, scope은 profile과 email, Redirect URI는 http://localhost임을 알 수 있다.
유저 A가 구글 로그인을 정상적으로 했다면, 구글은 이전에 등록되었던 client_id=123인 서버의 redirect_uri와 동일한지 확인한다. 일치하는 경우에 유저 A에게 scope=profile, email 기능을 넘겨줄 것인지에 대한 승인 여부를 물어보고, 동의한다면 구글은 이에 해당하는 authorization_code라는 임시 PW를 발급한다.
이후 http://localhost/?authorization_code=2으로 리다이렉트되며, 웹 사이트의 서버는 authorization_code를 가지고 구글에게 Access Token을 요청한다. 그리고 유저 A의 인증이 필요할 때마다 Access Token을 이용하여 접근한다.
인증 방식 종류
OAuth 2.0 로그인을 할 때 JWT를 사용하는 방식을 이용하는데, 우선 로그인에서 사용되는 인증 처리 방식을 공부해보자.
*️⃣ Basic 인증
상태가 없는 웹 애플리케이션에서 인증을 구현하는 가장 간단한 방법은 모든 HTTP 요청에 아이디와 비밀번호를 같이 보내는 것이다. 이를 Basic 인증이라고 하는데, 최초 로그인 후 HTTP 요청 헤더의 Authorization: 부분에 ‘Basic :’처럼 아이디와 비밀번호를 콜론으로 이어붙인 후, Base64로 인코딩한 문자열을 함께 보낸다.
이 HTTP 요청을 수신한 서버는 인코딩된 문자열을 디코딩해 아이디와 비밀번호를 찾아낸 후, 사용자 정보가 저장된 데이터베이스 또는 인증 서버의 레코드와 비교한다. 데이터베이스의 레코드는 아이디와 비밀번호의 일치여부에 따라 요청받은 일을 수행하거나 거부할 수 있다. 하지만 이 방식은 인코딩 자체가 보안의 목적이 아니므로, 아이디와 비밀번호가 노출된다. 따라서 HTTP와 사용하기엔 취약한 방법이다. (반드시 HTTPS 와 함께 사용해야 한다.)
1️⃣ Cookie 인증
쿠키는 Key-Value 형식의 문자열 덩어리이다. 클라이언트가 어떠한 웹 사이트를 방문할 경우, 그 사이트가 사용하고 있는 서버를 통해 클라이언트의 브라우저에 설치되는 작은 기록 정보 파일이다.
각 사용마다의 브라우저에 정보를 저장함으로써 고유 정보 식별이 가능한 것이다.
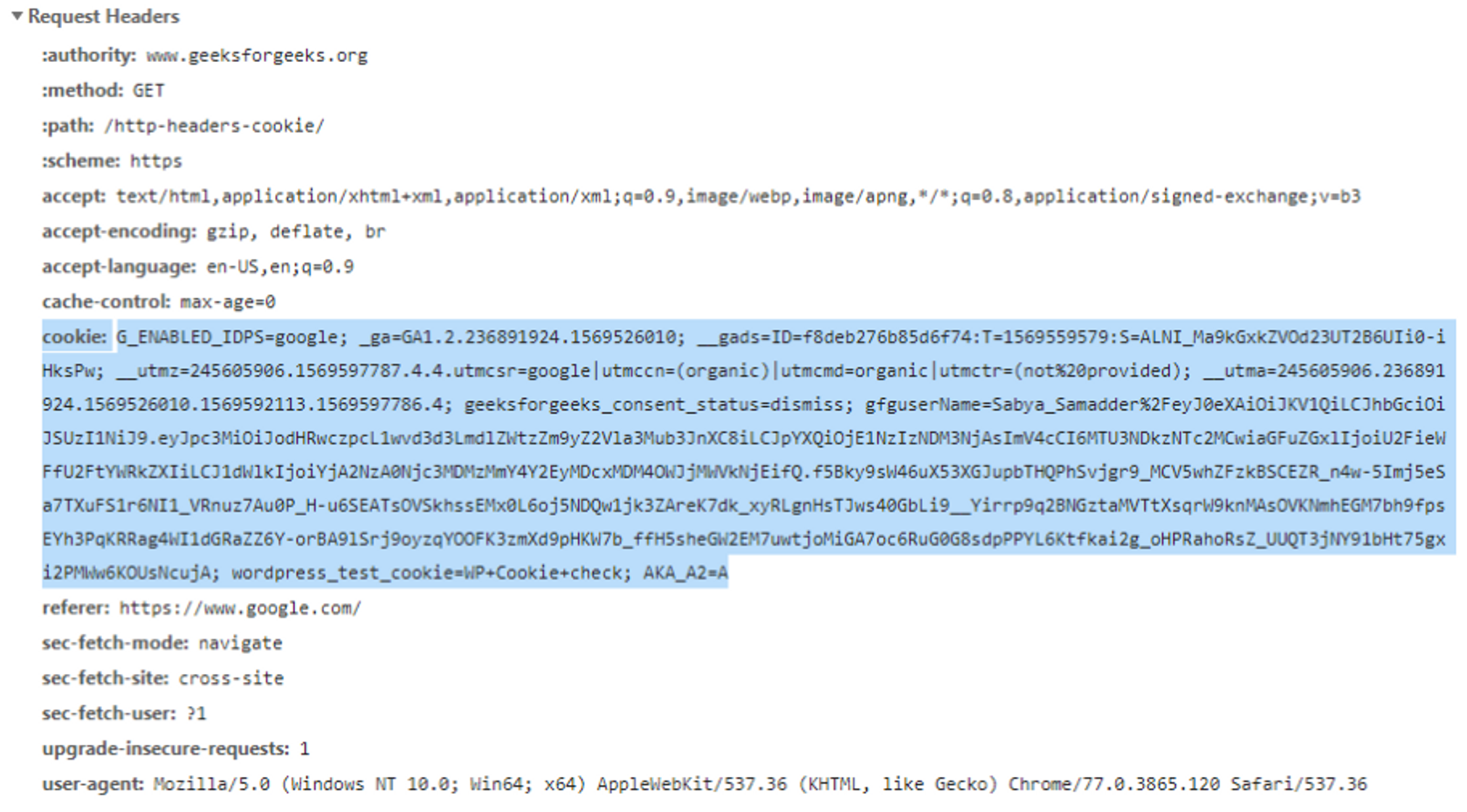

- 브라우저(클라이언트)가 서버에 요청(접속)을 보낸다.
- 서버는 클라이언트의 요청에 대한 응답을 작성할 때, 클라이언트 측에 저장하고 싶은 정보를 응답 헤더의 Set-Cookie에 담는다.
- 이후 해당 클라이언트는 요청을 보낼 때마다 매번 저장된 쿠키를 요청 헤더의 Cookie에 담아 보낸다. 서버는 쿠키에 담긴 정보를 바탕으로 해당 요청의 클라이언트가 누군지 식별하거나 정보를 바탕으로 추천 광고를 띄우거나 한다.
👎 단점
- 보안에 취약함 → 요청 시 쿠키의 값을 그대로 보내기 때문에 유출 및 조작 당할 위험이 존재한다.
- 쿠키에는 용량 제한이 있어 많은 정보를 담을 수 없다.
- 웹 브라우저마다 쿠키에 대한 지원 형태가 다르기 때문에 브라우저 간 공유가 불가능하다.
- 쿠키의 사이즈가 커질수록 네트워크에 부하가 심해진다.
2️⃣ Session 인증
쿠키의 보안적인 이슈를 보완하고자, 세션은 비밀번호 등 클라이언트의 민감한 인증 정보를 브라우저가 아닌 서버 측에 저장하고 관리한다.
서버의 메모리에 저장하기도 하고, 서버의 로컬 파일이나 데이터베이스에 저장하기도 한다. 핵심 골자는 민감한 정보는 클라이언트에 보내지 않고 서버에서 모두 관리한다는 점이다.

세션 객체는 Key에 해당하는 SESSION ID와 이에 대응하는 Value로 구성되어 있다. Value에는 세션 생성 시간, 마지막 접근 시간 및 User가 저장한 속성 등이 Map의 형태로 저장된다.
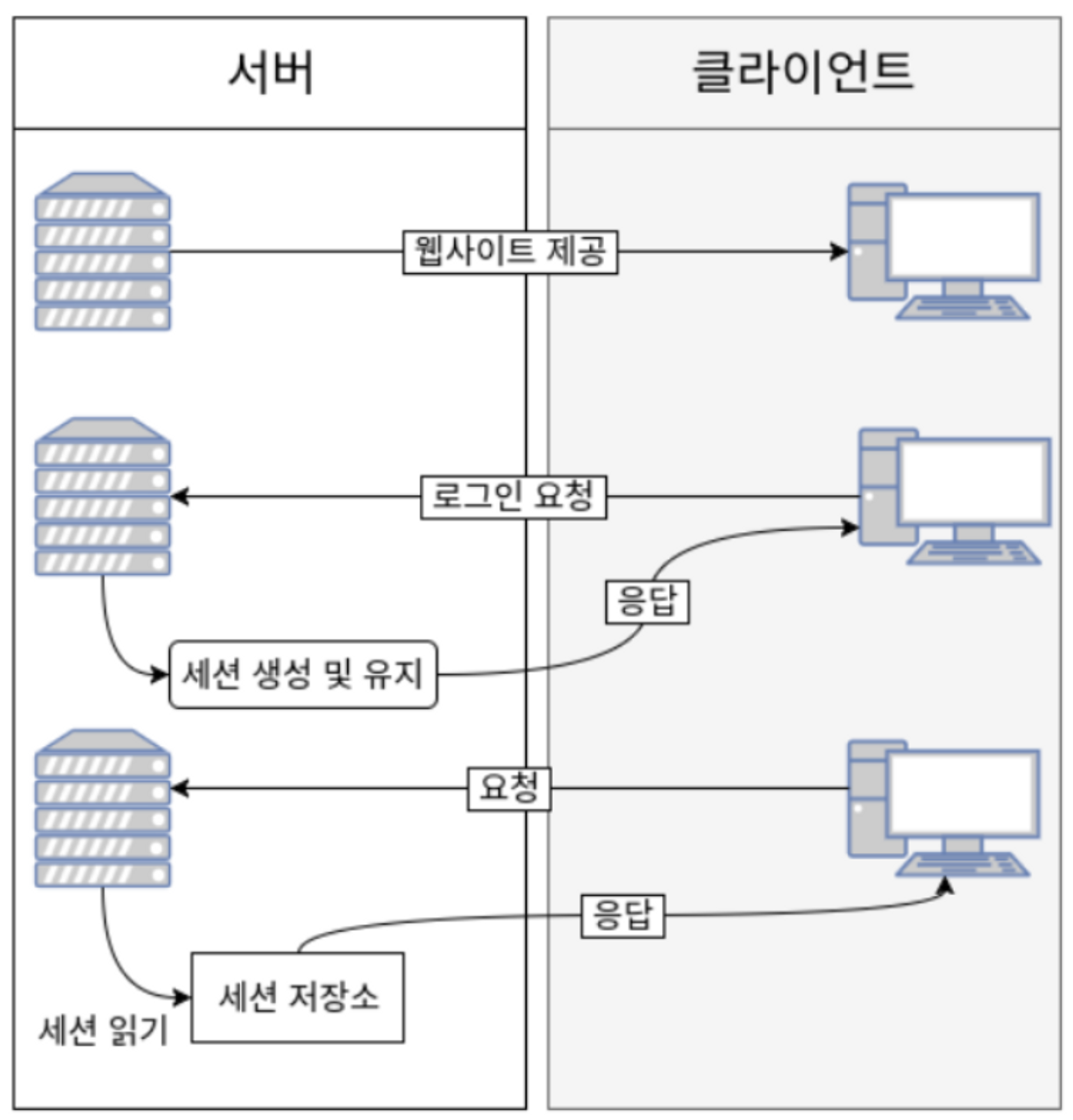
- 유저가 웹 사이트에서 로그인하면 세션이 서버 메모리 (or DB)에 저장된다. 이때 세션을 식별하기 위한 Session ID를 기준으로 정보를 저장한다.
- 서버에서 브라우저에 쿠키에다가 Session Id를 저장한다.
- 쿠키에 정보가 담겨있기 때문에 브라우저는 해당 사이트에 대한 모든 Request에 Session ID를 쿠키에 담아 전송한다.
- 서버는 클라이언트가 보낸 Session Id와 서버 메모리로 관리하고 있는 Session Id를 비교하여 인증을 수행한다.
👎 단점
- 쿠키를 포함한 요청이 외부에 노출되더라도 세션 ID 자체는 유의미한 개인정보를 담고 있지 않는다. BUT 해커가 세션 ID 자체를 탈취하여 클라이언트인 척 위장할 수 있다는 한계가 존재한다. *이는 서버에서 IP 특정을 통해 해결할 수 있는 방안이 있긴 하다.
- 서버에서 세션 저장소를 사용하므로 요청이 많아지면 서버에 부하가 심해진다.
3️⃣ Token 인증
토큰 기반 인증 시스템은 클라이언트가 서버에 접속을 하면 서버에서 해당 클라이언트에게 인증되었다는 의미로 토큰을 부여한다. 이 토큰은 유일하며, 토큰을 발급받은 클라이언트는 또 다시 서버에 요청을 보낼 때 요청 헤더에 토큰을 심어서 보낸다. (최초 로그인 시, 서버에서 발급)
그러면 서버에서는 클라이언트로부터 받은 토큰을 서버에서 제공한 토큰과의 일치 여부를 체크하여 인증 과정을 처리하게 된다.
기존의 세션 기반 인증은 서버가 파일이나 데이터베이스에 세션 정보를 가지고 있어야 하고, 이를 조회하는 과정이 필요하기 때문에 많은 오버헤드가 발생한다.
하지만 토큰은 세션과 달리 서버가 아닌 클라이언트에 저장되기 때문에 메모리나 스토리지 등을 통해 세션을 관리했던 서버의 부담을 덜 수 있다. 토큰 자체에 데이터가 들어있기 때문에 클라이언트에서 받아 위조되었는지 판별만 하면 되기 때문이다.
*웹에는 쿠키와 세션이 있지만, 앱에는 토큰밖에 없기 때문에 앱과 서버가 통신 및 인증할 때 토큰이 가장 많이 사용된다.
⚡ 서버 기반 vs 토큰 기반
-
서버(세션) 기반 인증 시스템
서버의 세션을 사용해 사용자 인증을 하는 방법으로 서버측(서버 램 or 데이터베이스)에서 사용자의 인증정보를 관리하는 것을 의미한다.
그러다 보니, 클라이언서트로부터 요청을 받으면 클라이언트의 상태를 계속에서 유지해놓고 사용한다.
(Stateful) 이는 사용자가 증가함에 따라 성능의 문제를 일으킬 수 있으며 확장성이 어렵다는 단점을 지닌다.*만약 마이크로 서비스 개발을 진행하거나 서버를 확장하게 된다면, 모든 서버에게 세션의 정보를 공유해야 하므로 이를 위한 별도의 중앙 세션 관리 서버를 두곤 한다.
-
토큰 기반 인증 시스템
이러한 단점을 극복하기 위해서 "토큰 기반 인증 시스템"이 나타났다.
인증받은 사용자에게 토큰을 발급하고, 로그인이 필요한 작업일 경우 헤더에 토큰을 함께 보내 인증받은 사용자인지 확인한다.
이는 서버 기반 인증 시스템과 달리 상태를 유지하지 않으므로 Stateless 한 특징을 가지고 있다.
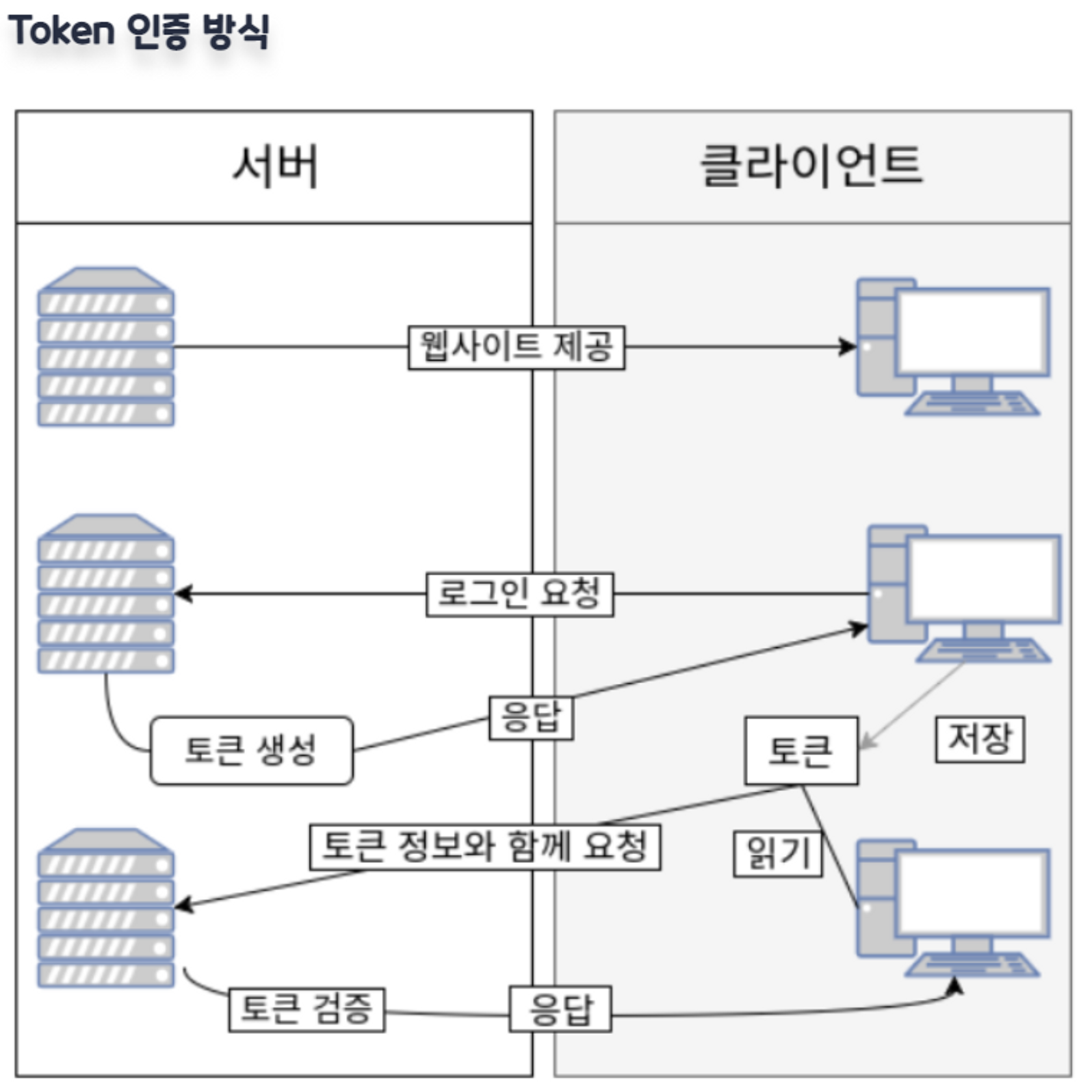
- 사용자가 아이디와 비밀번호로 로그인을 한다.
- 서버 측에서 사용자(클라이언트)에게 유일한 토큰을 발급한다.
- 클라이언트는 서버 측에서 전달받은 토큰을 쿠키나 스토리지에 저장해두고, 서버에 요청을 할 때마다 해당 토큰을 HTTP 요청 헤더에 포함시켜 전달한다.
- 서버는 전달받은 토큰을 검증하고 요청에 응답한다. 토큰에는 요청한 사람의 정보가 담겨있기에 서버는 DB를 조회하지 않고 누가 요청하는지 알 수 있다.
👎 단점
- 쿠키/세션과 달리 토큰 자체의 데이터가 길어, 인증 요청이 많아질수록 네트워크 부하가 심해질 수 있다.
- Payload 자체는 암호화되지 않기 때문에 유저의 중요한 정보는 담을 수 없다.
- 토큰을 탈취당하면 대처하기 어렵다. (따라서 사용 기간 제한을 설정하는 식으로 극복한다. )
JWT 토큰 인증 방식
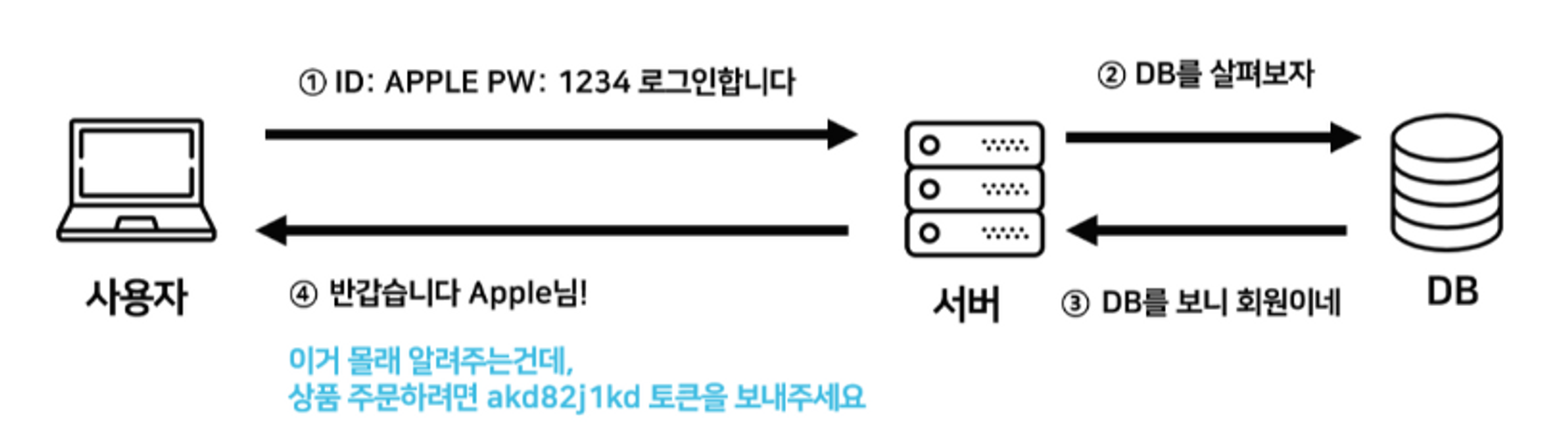
JWT (JSON Web Token)란 인증에 필요한 정보들을 암호화시킨 JSON 토큰을 의미한다.
그리고 JWT 기반 인증은 JWT 토큰 (Access Token)을 HTTP 헤더에 실어 서버가 클라이언트를 식별하는 방식이다.
JWT는 Claim 기반 방식을 사용하며, JSON 데이터를 Base64 URL-safe Encode를 통해 인코딩하여 직렬화한 것으로 토큰 내부에 위변조 방지를 위해 개인키를 통한 전자서명이 들어있다. 즉, 사용자의 상태를 포함하는 의미있는 토큰으로 구성되어 있기 때문에, Auth Server에 검증 요청을 보내야만 했던 과정을 생략하고 각 서버에서 수행할 수 있게 되어 비용 절감 및 Stateless 아키텍처를 구성할 수 있다. 따라서 사용자가 JWT를 서버로 전송하면 서버는 서명을 검증하는 과정을 거치게 되며 검증이 완료되면 요청한 응답을 돌려준다.
→ 전자서명에는 비대칭 암호화 알고리즘을 사용하므로 암호화를 위한 키와 복호화를 위한 키가 다르다. 암호화(전자서명)에는 개인키를, 복호화(검증)에는 공개키를 사용한다.
Claim : 사용자에 대한 속성 값
Base64 URL-safe Encode : 일반적인 Base64 Encode 에서 URL 에서 오류없이 사용하도록 '+', '/' 를 각각 '-', '_' 로 표현한 것
JWT 구조
JWT Token 형식
{ // Header
"typ": "JWT", // 토큰의 타입
"alg": "HS512" // 토큰의 서명을 발행하는 데 사용된 해시 알고리즘 종류
}.
{ // Payload
"sub": "402889021380912i23", // 토큰의 주인(유일한 식별자 = 사용자)
"iss": "demo app", // 토큰의 발행 주체 (= cakeN 서비스)
"iat": 15892032, // 토큰 발행 시간/날짜 (issued at)
"exp": 15963293 // 토큰 만료 시간 (expiration)
}.
{ // Signature - SECRET_KEY를 이용해 서명한 부분
NDJDSDsadjaslkdjasldjlkasjdlka
}

- Header : JWT에서 사용할 타입과 해시 알고리즘의 종류
{ "alg" : "HS256", -> 서명 암호화 알고리즘 (ex. HMAC, SHA256, RSA) "typ" : "JWT" -> 토큰 유형 } - Payload : 서버에서 첨부한 사용자 권한 정보와 데이터 토큰에서 사용할 정보의 조각들인 Claim이 담겨있다. ⇒ 실제 JWT를 통해서 알 수 있는 데이터. 즉 서버와 클라이언트가 주고받는 시스템에서 실제로 사용될 정보에 대한 내용을 담고 있는 섹션이다.
따로 정해진 데이터 타입은 없지만, 대표적으로 Registered Claim, Public Claim, Private Claim 이렇게 세 가지로 나뉜다.{ "sub" : "1234567890", // Registered Claim "name" : "Jun Park", // Private Claim "iat" : 1516239022, // Registered Claim "https://localhost.8080" // Public Claim }- Registed claims : 미리 정의된 클레임.
- iss(issuer; 발행자),
- exp(expireation time; 만료 시간),
- sub(subject; 제목),
- iat(issued At; 발행 시간),
- jti(JWI ID)
- Public claims : 사용자가 정의할 수 있는 클레임 공개용 정보 전달을 위해 사용.
- Private claims : 해당하는 당사자들 간에 정보를 공유하기 위해 만들어진 사용자 지정 클레임. 외부에 공개되도 상관없지만 해당 유저를 특정할 수 있는 정보들을 담는다
- Registed claims : 미리 정의된 클레임.
- Signature : Header, Payload를 Base64 URL-safe Encode를 한 이후 Header에 명시된 해시함수를 적용하고, 개인키(Private Key)로 서명한 전자서명이 담겨있다.
HMACSHA256(
base64UrlEncode(header) + "." + base64UrlEncode(payload), your-256-bit-secret
) 
JWT 생성 및 반환
사용자 정보를 바탕으로 {Header}.{Payload}를 작성하고 전자 서명한 후, 토큰을 리턴한다.
오늘 사용한 모든 Annotation
아래는 스프링 빈으로 등록하기 위한 어노테이션으로, @Component를 구체화하여 분리한 형태이다. 스프링에서는 CGLIB라는 바이트코드 조작 라이브러리를 사용하여 등록한 스프링 빈이 임의의 클래스를 통해 싱글톤이 유지되도록 지원해준다.
어노테이션 스캔 과정을 통해 정의한 클래스를 루트 서블릿용 컨테이너에 빈 객체로 생성하게 되는데, 활용 목적에 따라 아래와 같이 구분할 수 있다.
| 어노테이션 | 기능 |
|---|---|
| @Configuration | 설정 파일 |
| @Repository | 외부 I/O 처리 |
| @Service | 로직 처리 |
| @Controller | 컨트롤러 |
예외 처리 관련
@RestControllerAdvice
@ControllerAdvice+@ResponseBody→ Response Body로 값을 리턴!
*@Component 어노테이션을 가지고 있어 마찬가지로 컴포넌트 스캔을 통한 스프링 빈 등록이 가능하다.
💡 `@ControllerAdvice`모든 컨트롤러에 대해 전역적으로 발생할 수 있는 예외를 잡아서 처리하도록 하는 AOP 기반의 핸들러
→ @ExceptionHandler, @ModelAttribute, @InitBinder가 적용된 메서드들에 AOP를 적용해 Controller 단에 적용하기 위해 고안되었다.
@ExceptionHandler
@Controller, @RestController가 적용된 Bean 내에서 발생한 예외를 받아서 처리하도록 하는 어노테이션
@ModelAttribute
HTTP 요청을 받을 때, 필요한 파라미터 정보를 @RequestParam으로 전달받으면 일일이 요청 파라미터를 매핑해줘야 한다. 이때 검색 조건에 대한 변경사항이 발생하면 코드를 일일이 수정해줘야 하는 번거로움이 있는데, @ModelAttribute를 사용하면 이러한 문제점을 해결하여 한번에 매핑하는 것이 가능해지고 변경 시에도 따로 수정할 필요가 없다.
public BaseResponse getPage(@RequestParam int id,
@RequestParam String name,
@RequestParam String email) { ... }
public BaseResponse getPage(@ModelAttribute SearchForm searchForm) { ... }@InitBinder
Spring Validator를 사용 시 @Valid 어노테이션으로 검증이 필요한 객체를 가져오기 전에 수행할 메소드를 지정해주는 어노테이션이다. → 데이터 검증을 위해 Validator 인터페이스의 구현체를 따로 만들어 validate() 메소드를 직접 호출하여 사용하지 않아고, 스프링 프레임워크에서 호출이 가능하다.
왜! 이 어노테이션을 사용해야 하는가
예외 클래스를 사용하는 방식은 크게 두 가지로 나눠서 볼 수 있다.
💡 Checked Exception VS Unchecked Exception최근 예외 클래스 사용의 트렌드는 Unchecked Exception을 사용하는 것이다 !
-
Checked Exception : try-catch를 사용하여 예외를 처리하도록 강제하는 방식
→ 아는 try-catch를 남발하게 되며, 의미없는 catch 구문을 쓰게 되고 불필요한 코드가 많아진다는 단점이 있다.
-
Unchecked Exception : try-catch를 강제하지 않는 방식
🤔 그렇다면, 예외를 catch한 이후에는?
로그를 남겨줍시다! → 발생한 문제에 대해 예외 종류에 따라 로깅 레벨을 지정해준 후, 로그 메시지로 원인을 파악할 수 있도록 함과 동시에, stack race를 남겨서 해결할 수 있도록 해야 한다
| 레벨 | 설명 |
|---|---|
| DEBUG | 개발 단계에서 프로세스의 흐름을 체크하는 경우 등에 사용 |
| INFO | 디버깅 정보 외에 필요한 정보(설정 정보 등)를 기록할 떄 사용 |
| WARN | 오류 상황은 아니지만, 추후 확인이 필요한 정보 등을 남길 때 사용 |
| ERROR | 가장 우선순위로 처리해야 하는 예외 상황에 사용 |
| FATAL | 매우 심각한 상황에 사용 (개발자가 사용할 일은 거의 無 |
*log4j를 사용하면, 따로 처리해주지 않고 마지막에 Exception 객체만 넘겨줘도 stack race를 남길 수 있다.
*참고 자료 - https://velog.io/@midas/Exception-처리-방법
커스텀 어노테이션 생성
@Retention
해당 어노테이션이 선언된 대상(
@Target의 속성값)의 메모리를 언제까지 유지할 것인지 결정하는 어노테이션
RetentionPolicy라는 ENUM 타입값을 인자로 받아 메모리 유지타임을 결정한다.
| 종류 | 기능 | 설명 |
|---|---|---|
| RetentionPolicy.SOURCE | 실제 동작할 때 영향 X | 자바 컴파일러가 자바 코드를 컴파일할 때 해당 어노테이션의 메모리를 버린다. (→ 사실상 주석의 기능에 그친다) |
| RetentionPolicy.CLASS | 어플리케이션 동작 시에 영향 X | 컴파일러가 해당 어노테이션의 메모리를 유지하여 컴파일하지만, 실질적으로 JVM이 바이트코드를 해석해서 동작하는 런타임 단계에서 해당 메모리를 버린다. |
| RetentionPolicy.RUNTIME | 어플리케이션 동작하는 동안 항상 영향 O | JVM이 실제 클래스의 자바 바이트코드를 해서하여 동작하는 런타임 단계에서 메모리가 유지되고, 런타임이 종료되면 메모리도 사라진다. |
@Target
커스텀 어노테이션의 적용될 대상을 지정하는 어노테이션
| 종류 | 기능 |
|---|---|
| TYPE | 클래스, 인터페이스에 선언 |
| FIELD | enum, 상수 포함 객체 필드에 선언 |
| METHOD | 메소드에 선언 |
| PARAMETER | 일반적인 파라미터에 선언 |
| CONSTRUCTOR | 생성자에 선언 |
| LOCAL_VARIABLE | 지역변수에 선언 |
| ANNOTATION_TYPE | 어노테이션에 선언 |
| PACKAGE | 패키지에 선언 |
| TYPE_PARAMETER | 매개변수의 타입에 선언 |
| TYPE_USE | 매개변수 사용 시 선언 |
*실습에서 Spring Security로 인증된 유저에 대한 로직을 어노테이션으로 구현할 때, PARAMETER로 지정해줌
