Byte
- 대부분의 컴퓨터 시스템에서, 8 비트 길이를 가지는 정보의 기본 단위
- 영어와 숫자 그리고 특수문자(아스키 문자표에 있는) 등의 경우 1글자를 표현하는데 1byte, 한글이나 한자 등은 한 글자를 표현하는데 2byte
- 활용 목적에 따라(좀더 큰 단위로 사용될 필요가 있을 때)
- 비트 스트링(string of bits)을 유지할 수 있음
- 예를 들면, 이미지를 표현하는 프로그램을 위한 시각적 이미지를 구성하고 있는 연속된 비트들이 필요할 때
- 어떤 컴퓨터 시스템에서는 4byte를 1word로 구성함으로써, 프로세서가 보다 효율적으로 각 명령어를 읽고 처리할 수 있도록 설계되지만, 어떤 컴퓨터 프로세서들은 2byte 또는 1byte 명령어를 취급할 수 있음.
- 표기: Byte는 영문 대문자 "B", 소문자 "b"는 Bit
- 컴퓨터 저장장치는 그 크기를 보통 Byte 단위
- 예를 들어 850MB 하드디스크에는 통상 850,000,000 byte 정도의 정보를 담을 수 있음.
- 56 Kbps 모뎀은 1 초에 56,000 bit를 전송하는 속도로 동작
- 저장공간은 byte 단위로, 전송용량은 초당 bit 수로 산정
유니코드
- 유니코드 협회가 제정하는 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준.
- ISO 10646 문자 집합, 문자 인코딩, 문자 정보 데이터베이스, 문자를 다루기 위한 알고리즘 등을 포함하고 있음
인코딩
- 컴퓨터 과학 분야에서 효율적인 전송 혹은 저장을 위해 문자들을 특수포맷으로 표현하는 포괄적인 개념
- 어떤 문자나 기호를 컴퓨터가 이용할 수 있는 신호로 만드는 것
- 이 신호를 입력하는 인코딩과 문자흘 해독하는 디코딩을 하기위해선 미리 정해진 기준을 바탕으로 입력과 해독이 처리되어야 함
- charset: 인코딩과 디코딩의 기준. 이 문자셋의 국제 표준이 유니코드
- Bast64 인코딩
- Binary Data를 Text로 바꾸는 인코딩의 하나로써 Binary Data를 Character set에 영향을 받지 않는 공통 ASCII영역의 문자로만 이루어진 문자열로 바꾸는 인코딩 방법
- 뒤에 숫자 64는 64진법을 말함
- 64진법은 컴퓨터한테 특별한데 그 이유는 64가 2의 제곱 64=2^6이며 2의 제곱수에 기반한 진법 중 화면에 표시되는 ASCII 문자들로 표시할 수 있는 가장 큰 진법이기 때문(ASCII에는 제어문자가 다수 포함되어 있기 때문에 화면에 표시되는 ASCII문자는 128개가 되지 않는다)
- 핵심은 Base64 인코딩은 Binary Data를 Text로 변경하는 인코딩
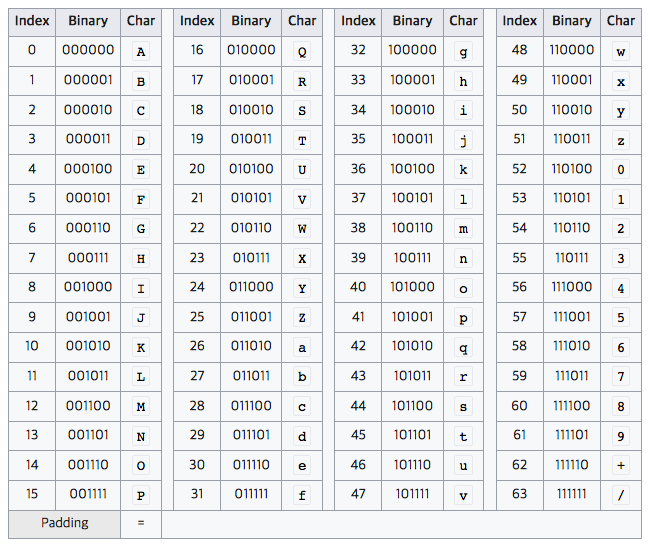
- 변경하는 방식을 간략하게 설명하면 Binary Data를 6bit씩 자른 뒤 6bit에 해당하는 문자를 아래 Base64 색인표에서 찾아 치환(실제로는 Padding을 더해주는 과정이 추가됨)
- Base64 Table
- JS에서 Base64인코딩
btoa('Hello world!'); // 'SGVsbG8gV29ybGQh' return atob('SGVsbG8gV29ybGQh'); // 'hello world' return- Base64인코딩을 사용하는 이유
- 인코딩을 하게되면 전송해야 데이터가 약 33%정도 늘어난다(6bit당 2bit의 오버헤드가 발생하기 때문)
- 그런데도 사용하는 이유는 문자를 전송하기 위해 설계된 미디어(이메일,html)를 이용해 플랫폼 독립적으로 Binary Data를 전송할 필요가 있을때, 동일하게 전송 또는 저장되는것ㄹ 보장하기 위해서 사용된다.
ASCII
- 영문 알파벳을 사용하는 대표적인 문자 인코딩으로 7bit로 모든 영어 알파벳으로 표현할 수 있음
- 52개의 영어 대소문자와, 10개의 숫자, 32개의 특수문자, 그리고 하나의 공백문자를 포함
- 유니코드는 아스키코드의 확장 형태
UTF-8, UTF-16
UTF-8
- 유니코드 한 문자를 나타나기 위해 1~4byte까지의 가변 길이를 가지는 인코딩 방식
- 네트워크로 전송되는 텍스트는 주로 이것.
- UTF-8은 아스키코드의 경우 1byte, 영어외 글자는 2,3byte, 보조글자(이모지 등) 4byte
- 원리
- '코'라는 문자의 유니코드는 U+CF54(16진수)
- 이진법으로 표시하면, 1100-1111-0101-0100
- 이것을 UTF-8로 인코딩하면,
1110xxxx 10xxxxxx 10xxxxxx
11101100 10111101 10010100 // 이렇게 표현됨let encoder = bew TextEncoder(); encoder.encode('코') // Uint8Array(3) [236,189,148] (236).toString(2) // 11101100 (189).toString(2) // 10111101 (148).toString(2) // 10010100
- 아스키코드는 7비트로 표현되고, UTF-8에선 1 byte로
UTF-16
- 유니코드 대부분을 16bit(2byte, U+0000부터 U+FFFF; BMP)로 표현
- UTF-8에서는 한글은 3 바이트, UTF-16에서는 2 바이트를 차지합니다.
차이점
- UTF-8은 UTF-16에 비해 바이트 순서를 따지지않고, 순서가 정해짐

'하루를 참고 인내하면 열흘을 벌 수 있고 사흘을 참고 견디면 30일을, 30일을 견디면 3년을 벌 수 있다.'