프로세스와 스레드가 무엇인가요?
프로세스의 개념
운영체제에서 프로세스는 일련의 작업 단위입니다. 프로그램은 파일이 저장장치에 저장되어 있지만 메모리에는 올라가 있지 않은 정적인 상태이며, 이러한 프로그램을 실행시켜 운영 체제로부터 CPU를 할당받고 실행되고 있는 상태를 바로 프로세스라고 합니다.
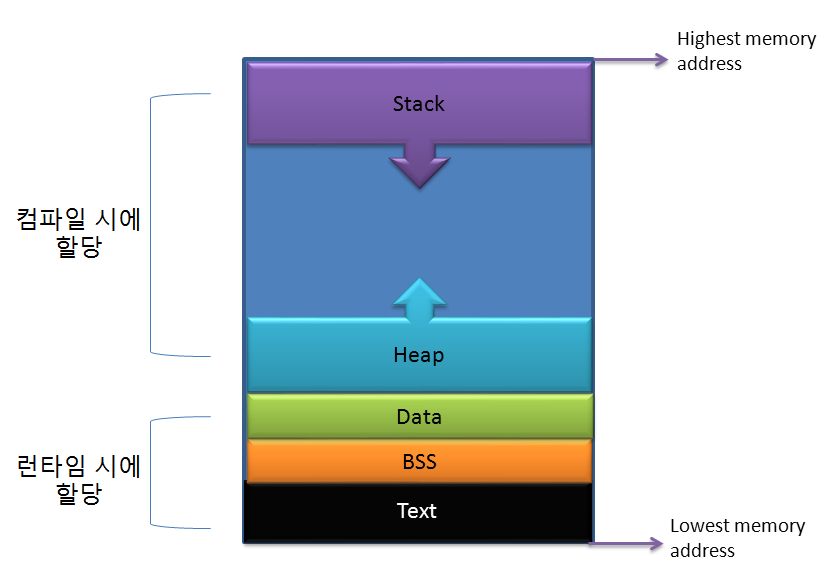
프로세스의 메모리 구조
프로세스의 메모리 구조는 일반적으로 다음과 같이 구성되어 있습니다:
1. 텍스트 영역 (Text Segment or Code Segment): 이 영역에는 프로세스가 실행하는 프로그램의 코드가 포함되어 있습니다. 이 코드는 일반적으로 읽기 전용으로, 실행 가능한 명령어들이 순서대로 저장됩니다.
2. 데이터 영역 (Data Segment): 이 영역에는 프로그램의 전역 변수와 정적 변수가 저장됩니다. 이들 변수는 프로그램 전체의 실행 동안 계속 존재하며, 특정 함수에 속하지 않는 변수입니다. 초기화된 데이터 영역과 초기화되지 않은 데이터 영역(BSS segment)으로 더 세분화될 수도 있습니다.
3. 힙 영역 (Heap Segment): 힙은 동적 메모리 할당이 이루어지는 곳입니다. 프로그램이 실행되는 동안 요구에 따라 메모리 공간이 할당되거나 해제될 수 있습니다. 힙은 메모리의 낮은 주소에서 높은 주소로 증가합니다. FIFO(First In First Out) 방식으로 동작합니다.
4. 스택 영역 (Stack Segment): 스택 영역은 함수 호출과 관련된 정보를 저장하는 곳입니다. 함수 호출시에 생성되는 각 로컬 변수와 반환 주소는 스택에 저장됩니다. 스택은 메모리의 높은 주소에서 낮은 주소로 감소합니다. LIFO(Last In First Out) 방식으로 동작합니다.
프로세스의 종류
프로세스는 그들의 특성에 따라 여러 가지로 분류될 수 있습니다. 다음은 프로세스의 일반적인 분류입니다:
1. Foreground (Interactive) Processes: 이 프로세스들은 일반적으로 사용자의 입력을 기다리는 상호 작용적인 작업에 사용됩니다. 예를 들어, 텍스트 편집기, 그래픽 사용자 인터페이스(GUI), 데이터베이스 관리 시스템(DBMS)과 같은 응용 프로그램이 이 분류에 속합니다.
2. Background (Batch or Non-interactive) Processes: 이 프로세스들은 사용자의 상호 작용 없이 실행되며, 일반적으로 일정한 시간에 실행되거나 특정 이벤트를 기다리는 작업에 사용됩니다. 예를 들어, 스케줄링된 백업 작업, 서버 프로세스, 이메일을 확인하는 데몬 등이 이 분류에 속합니다.
3. Parent and Child Processes: 운영 체제는 한 프로세스가 다른 프로세스를 생성할 수 있는 메커니즘을 제공합니다. 이러한 관계에서 생성한 프로세스를 '부모 프로세스(Parent Process)'라고 하고, 생성된 프로세스를 '자식 프로세스(Child Process)'라고 합니다. 이런 구조를 통해 프로세스 간에 계층적 관계를 형성할 수 있습니다.
4. Daemon Processes: 데몬 프로세스는 백그라운드에서 실행되는 특별한 유형의 프로세스로, 특정 서비스를 제공하거나 시스템 관리 작업을 수행합니다. 일반적으로 운영 체제가 시작될 때 자동으로 실행되며, 사용자의 입력 없이도 계속 실행됩니다.
이 외에도, 실시간 프로세스, 멀티스레드 프로세스, 분산 시스템의 분산 프로세스 등 다양한 유형의 프로세스가 존재할 수 있습니다.
스레드의 개념
스레드는 프로세스 내에서 실행되는 개별적인 실행 흐름 또는 실행 단위를 의미합니다. 각 스레드는 프로세스의 리소스(메모리 공간, 파일 핸들, 등)를 공유하면서 동시에 실행될 수 있습니다. 따라서 스레드를 사용하면 한 프로세스 내에서 여러 작업을 동시에 수행할 수 있으며, 이를 통해 프로그램의 성능을 향상시킬 수 있습니다.
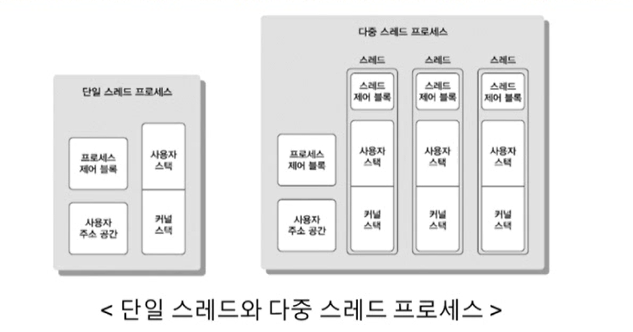
스레드의 특징
1. 자원 공유: 스레드는 동일한 프로세스의 다른 스레드와 코드, 데이터 및 힙 영역 등의 메모리를 공유합니다. 이것은 스레드 간의 통신을 용이하게 하며, 스레드 생성과 제거의 비용을 줄입니다.
2. 독립적인 실행: 각 스레드는 자신만의 스택을 가지며, 스택 내의 데이터와 CPU 레지스터는 다른 스레드와 공유되지 않습니다. 따라서 각 스레드는 독립적으로 실행되며, 한 스레드의 실행 상태가 다른 스레드에 직접적인 영향을 미치지 않습니다.
3. 효율적인 커뮤니케이션: 스레드는 동일한 프로세스 내에서 메모리를 공유하므로, 스레드 간의 통신은 프로세스 간의 통신보다 훨씬 빠르고 효율적입니다.
4. 병렬성: 멀티프로세서와 멀티코어 시스템에서, 여러 스레드는 동시에 병렬적으로 실행될 수 있습니다. 이로 인해 복잡한 작업을 빠르게 수행할 수 있으며, 프로그램의 전반적인 성능을 향상시킬 수 있습니다.
5. 경량: 스레드는 프로세스에 비해 생성과 제거에 드는 오버헤드가 작습니다. 이는 스레드가 메모리와 자원을 공유하므로, 스레드를 생성하거나 제거하는 것이 프로세스를 생성하거나 제거하는 것보다 더 경제적이라는 것을 의미합니다.
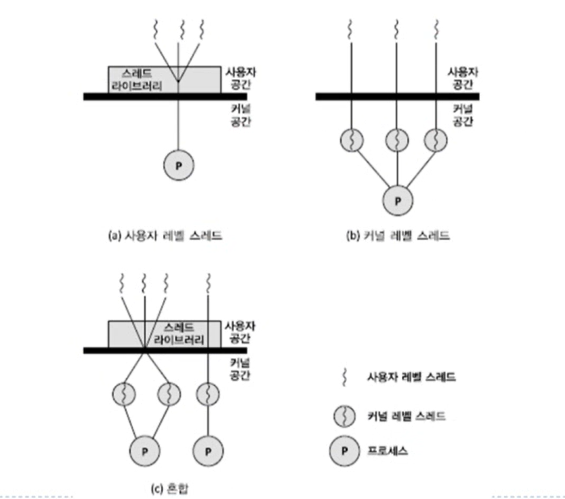
스레드의 종류
스레드는 일반적으로 두 가지 기본 유형으로 분류될 수 있습니다: 사용자 수준 스레드(User-Level Threads, ULT)와 커널 수준 스레드(Kernel-Level Threads, KLT).
1. 사용자 수준 스레드 (User-Level Threads, ULT): 이 유형의 스레드는 커널이 아닌 사용자 수준의 스레드 라이브러리에 의해 관리됩니다. ULT는 커널의 지원을 받지 않으며, 커널은 ULT의 존재를 알지 못합니다. 따라서 스케줄링이나 스레드 관리가 사용자 수준에서 수행되며, 이로 인해 성능 향상을 얻을 수 있습니다. 그러나 한 스레드가 시스템 호출을 통해 블록되면, 동일한 프로세스 내의 다른 모든 스레드도 블록될 수 있는 문제가 있습니다.
2. 커널 수준 스레드 (Kernel-Level Threads, KLT): KLT는 직접 커널에 의해 관리되며, 각각이 커널의 개별 스케줄링 단위로 간주됩니다. 이런 유형의 스레드는 커널이 직접 지원하므로, 한 스레드가 블록되더라도 동일한 프로세스의 다른 스레드가 실행될 수 있습니다. 그러나 커널 수준의 스레드는 생성, 제거, 스케줄링 등의 연산이 비교적 무거운 작업이므로, 사용자 수준 스레드에 비해 비용이 더 들 수 있습니다.
어떤 경우에는 이 두 유형의 스레드를 혼합하여 사용하는 하이브리드 접근법도 사용될 수 있습니다.
