
6월 22일 학습 목표
optimitic ui
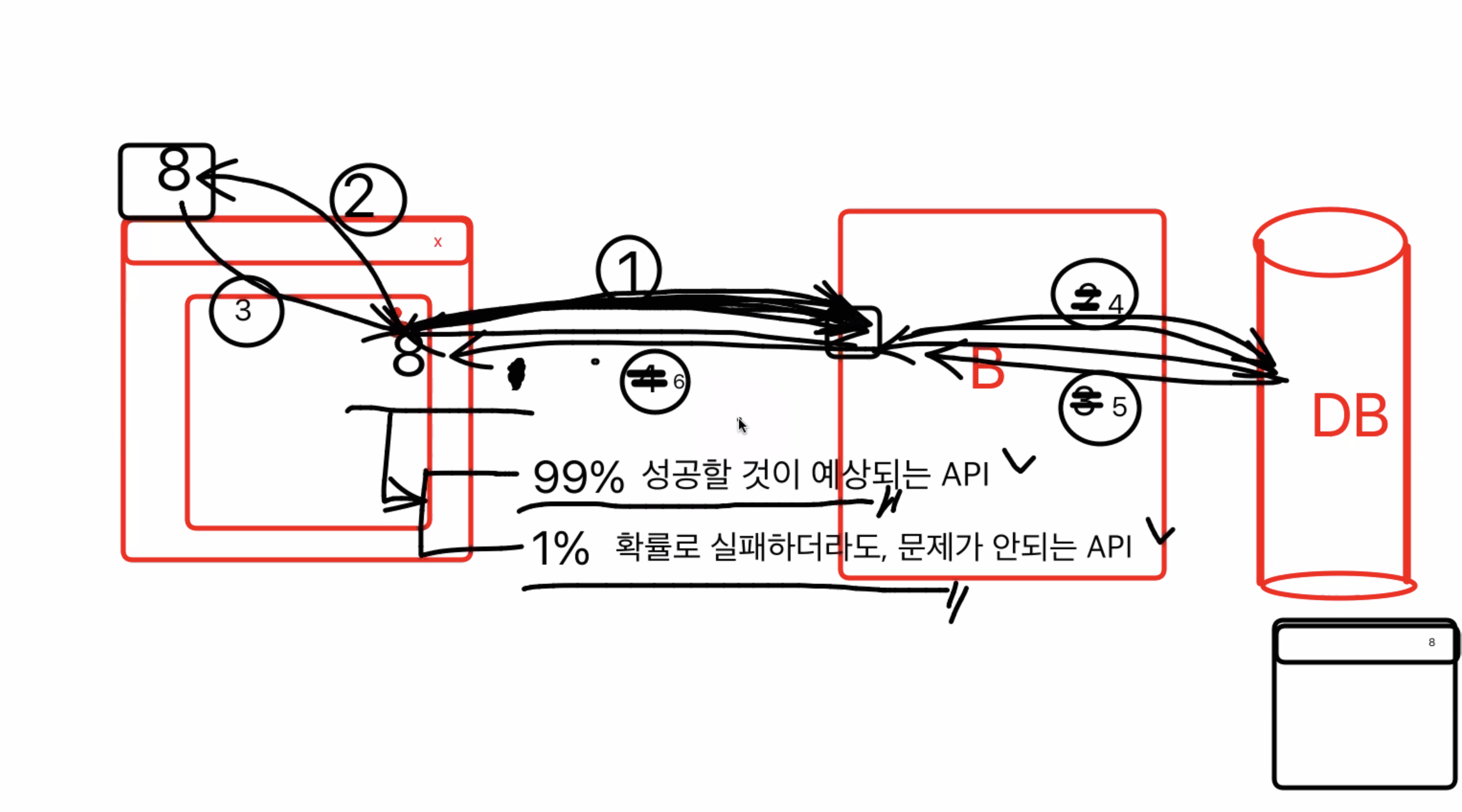
1 백엔드에 요청을 보내고(99% 성공할거라고예측한상태)
2 바로 캐시스테이트를 보내 업데이트함
3 api가 db에서 백엔드를 거쳐 왔을 때, 바뀐 캐시스테이트와 같으면 유지 / 만약 다르다면 백엔드에서 보내는 것으로바꾸기
=> 단순한 api일 경우에 사용하는 것이 좋다 / 1%의 확률로 실패하더라도, 문제가 되지 않는 api
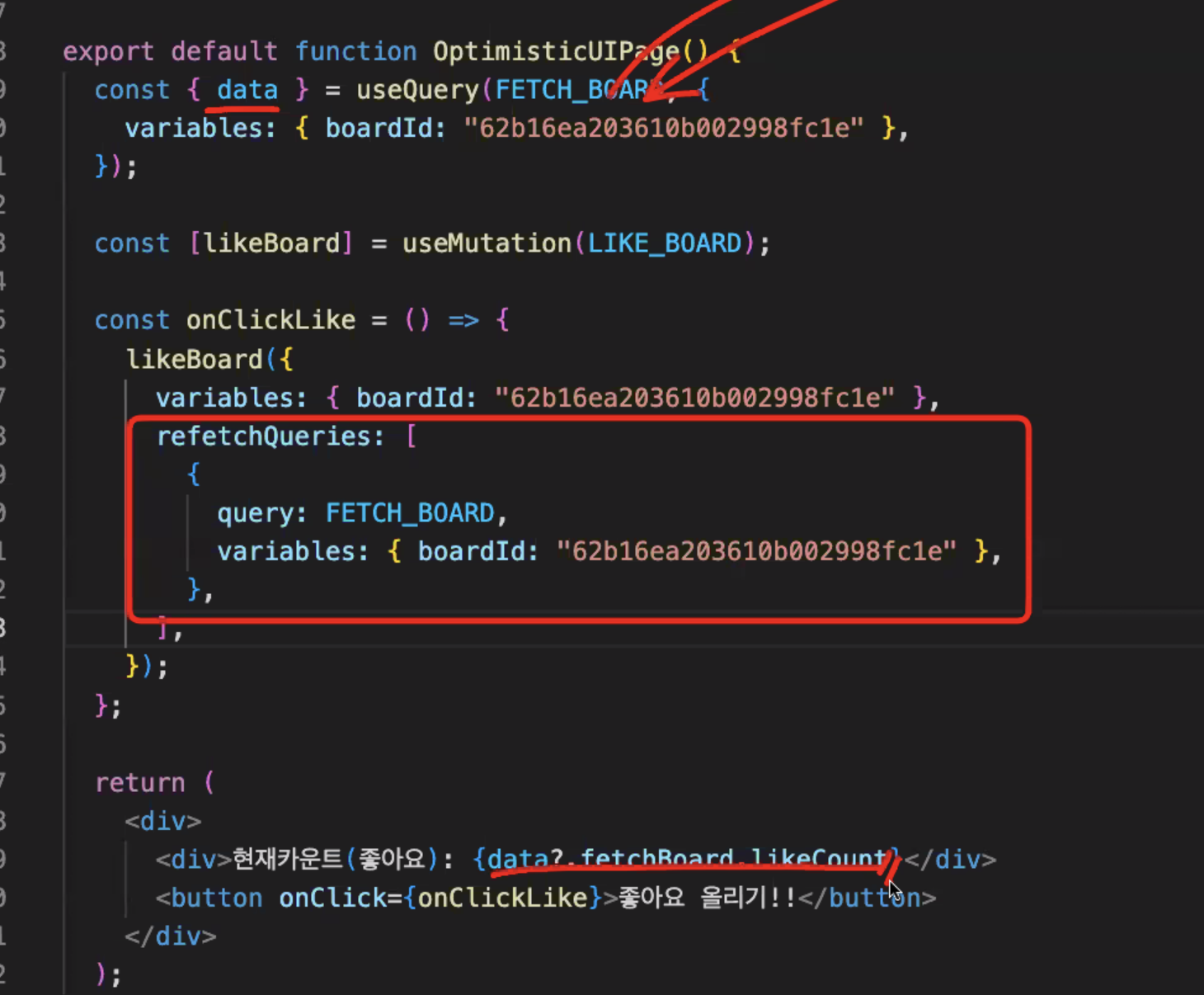
기존에 좋아요 후 리패치 했던 방식
속도도 느리고, 쿼리 요청을 다시 하는 것이기 때문에 비효율적이다
update cache 요청
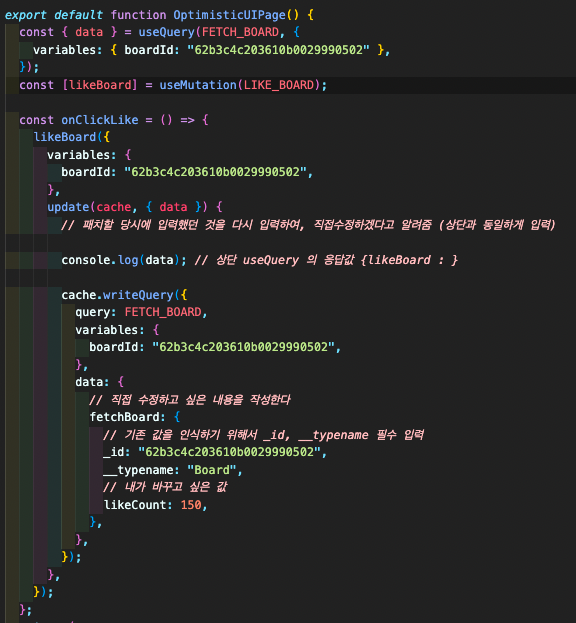
아직은 속도도 느리지만, 리패치를 하는 것보다는 요청이 1번만 가니까 낫다
optimistic UI
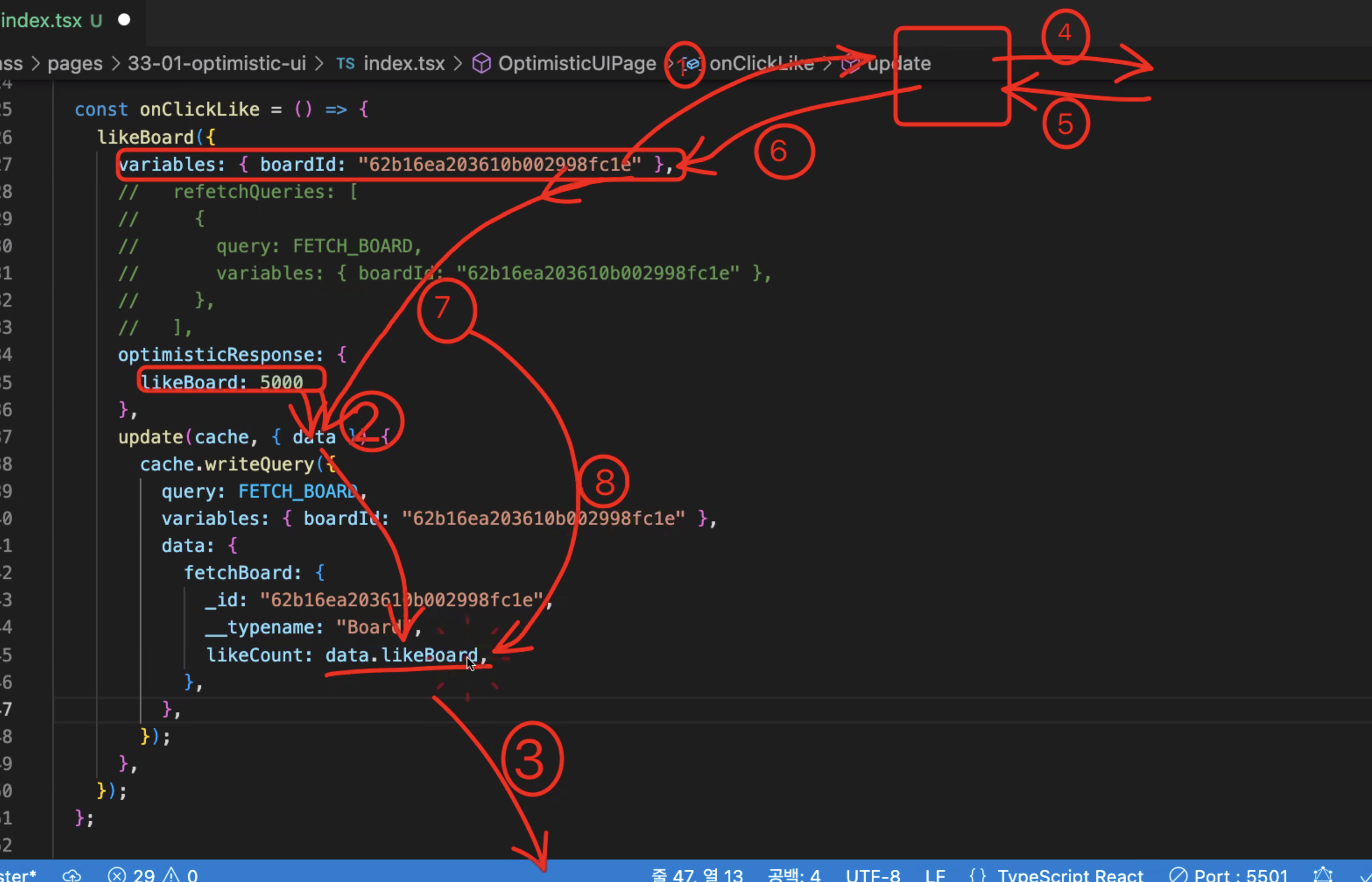
가짜 likeboardfmf 를 data에 넘겨서 , 그 데이터를 캐시데이터로 바꾼다.
그 후에 백엔드에서 받아오는 진짜 최종 데이터를 다시 캐시데이터에 넣어 최종 결과를 나타낸다

현재 좋아요 + 1(다음 좋아요)
스크래핑
미리보기 = openGraph

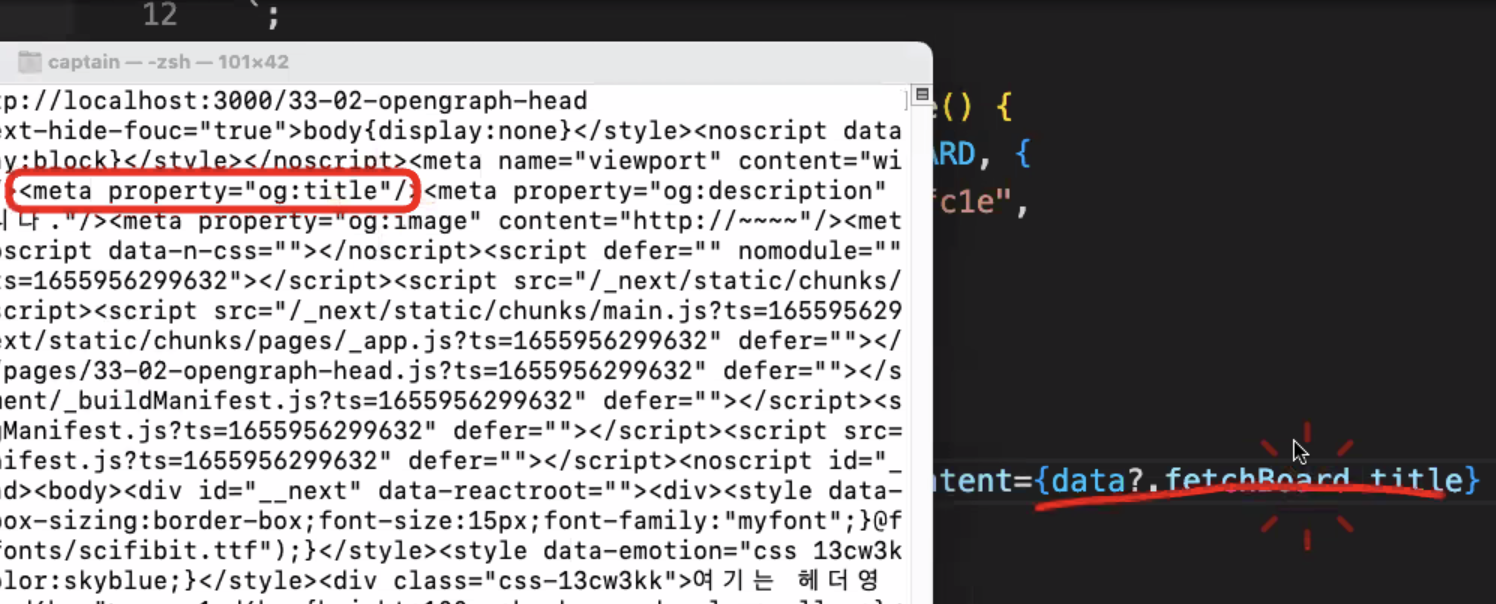
스크래핑 : meta OG태그의 정보를 긁어 뽑아온다
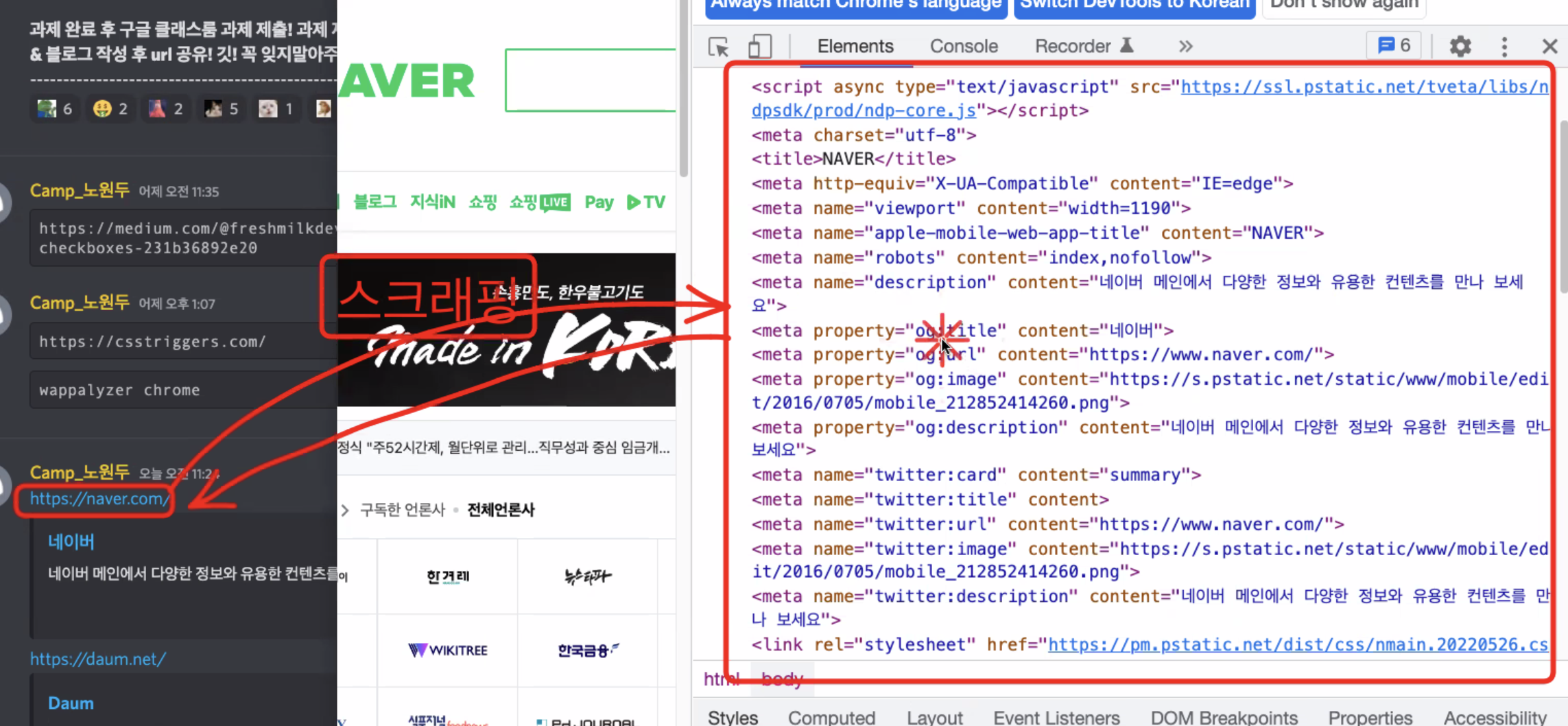
각각 페이지에 접속하면 페이지 정보를 response 할 수 있다(백은 json으로 - 예전에는 xml(jsx))
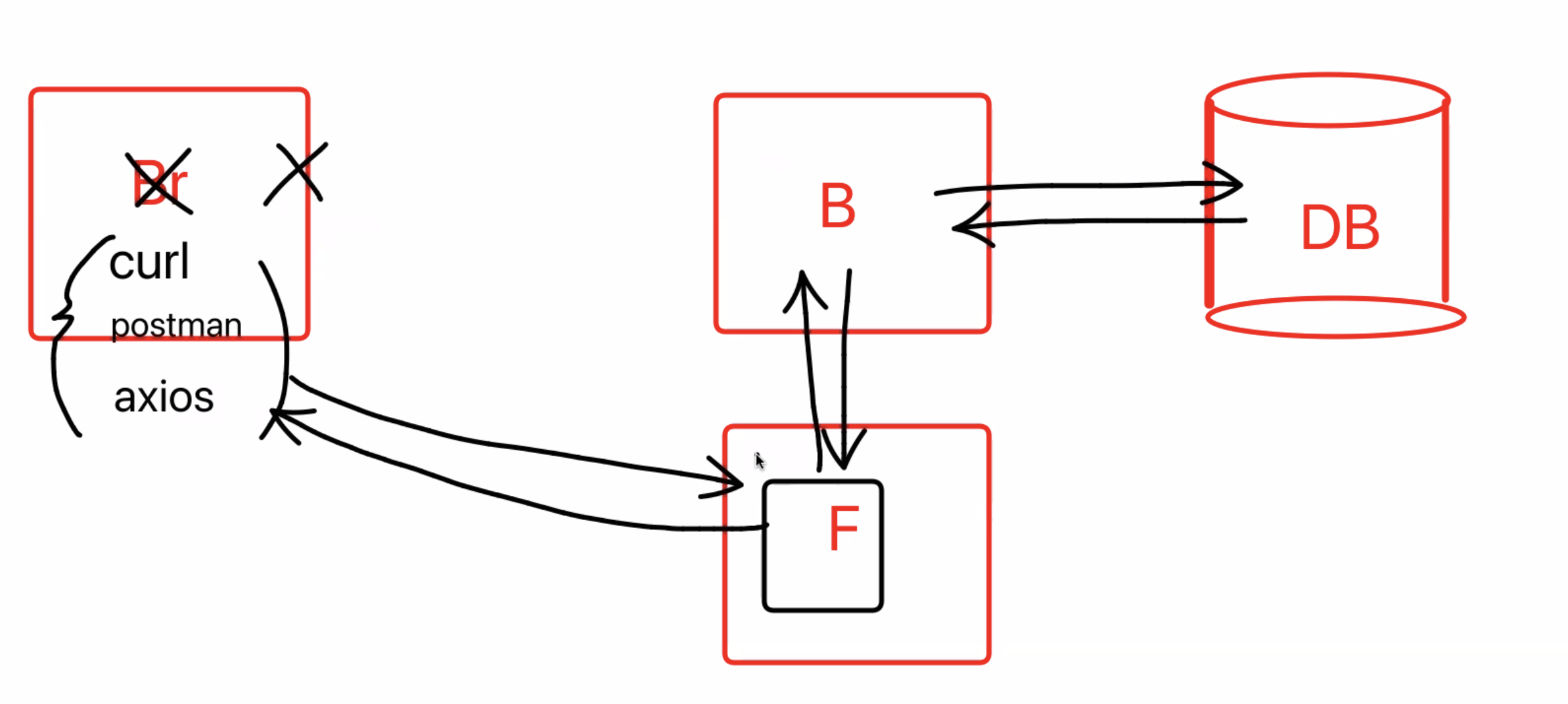
포스트맨
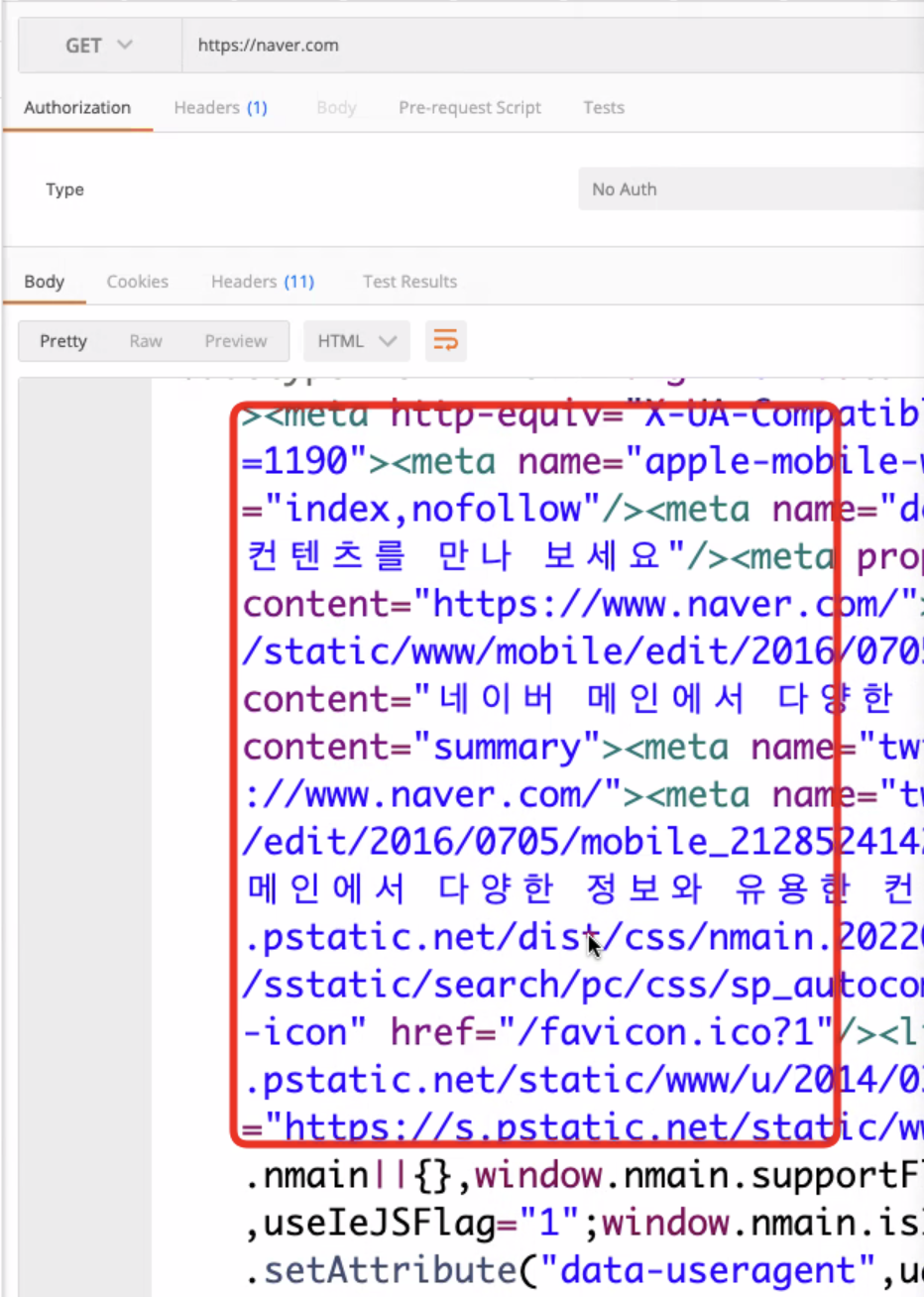
터미널에서 'cul'사용하면 http요청을 보낼 수 있다.
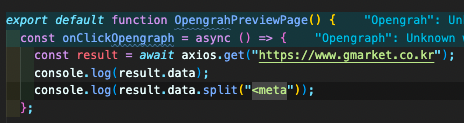
사용할 라이브러리
스크래핑은 연습할 수 있지만 웹 프론트엔드 개발자가 하기는 어렵다 (CORS 문제때문에)
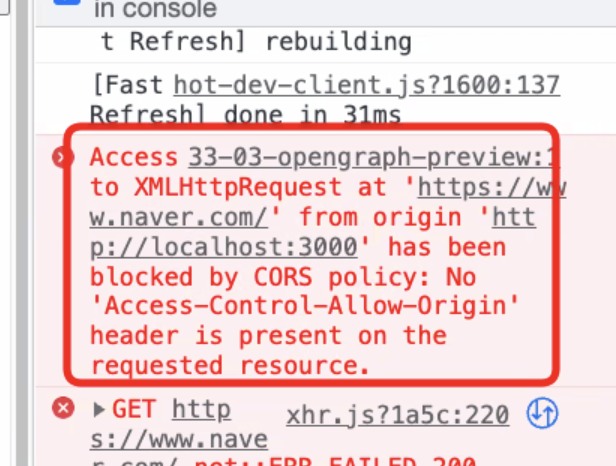
백엔드에서 스크래핑 후, 최종 결과를 받아 화면에 그려주게 될 것이다 그래도 모바일의 경우는 프론트엔드에서도 가능하다
g마켓 스크래핑

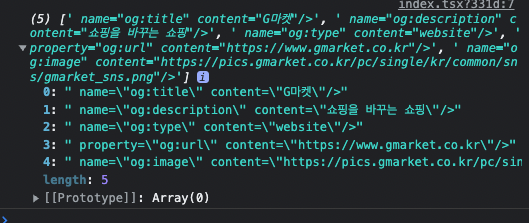
다양한 알고리즘을 사용하여 내가 원하는 정보를 가져올 수 있다.
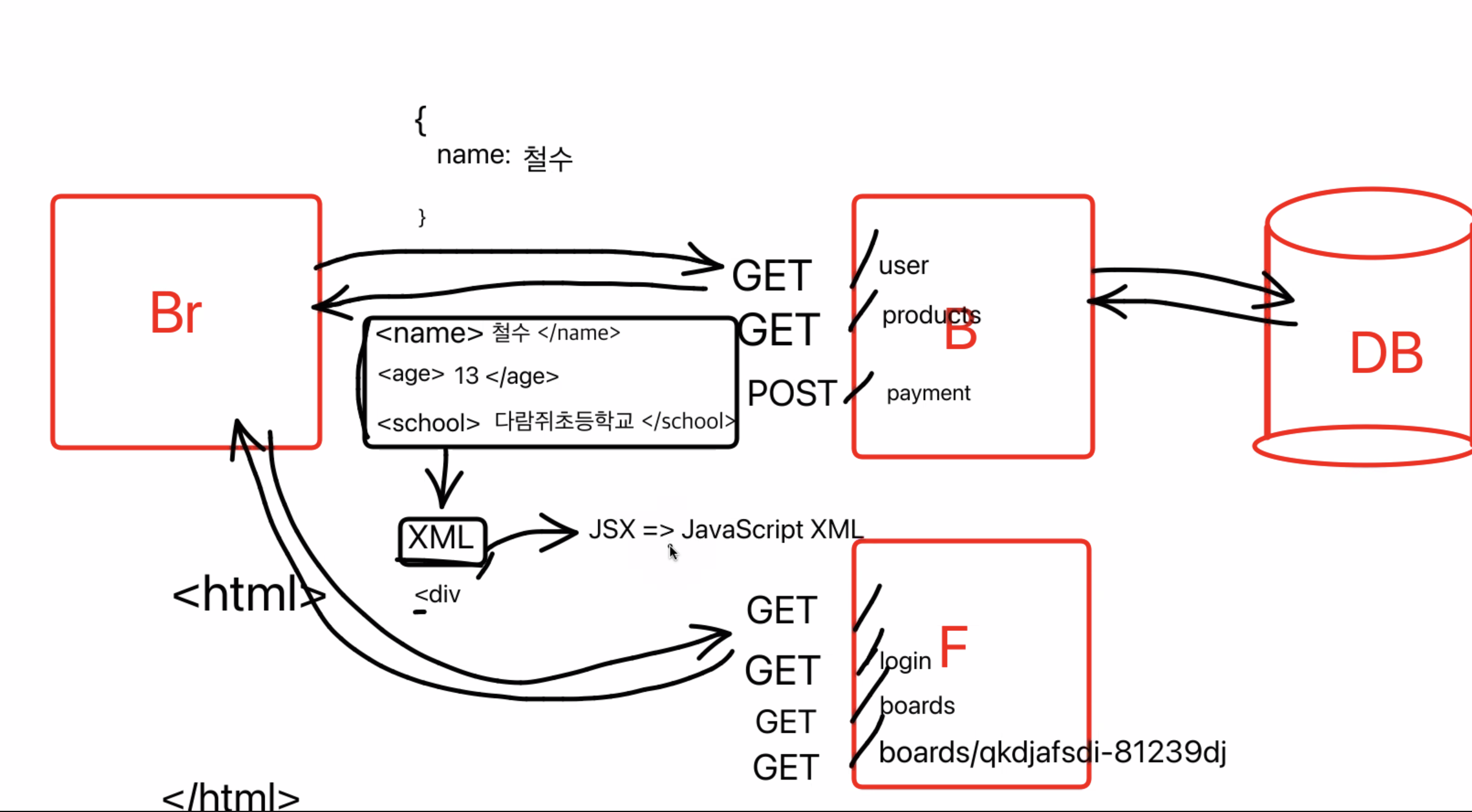
SSR
useQuery를 통해 받아온 data는 스크래핑으로 바로 확인 할 수 없다 => 초기 렌더링에서는 useQuery하지 않음. 따라서 정적인 데이터만 이용이 가능함
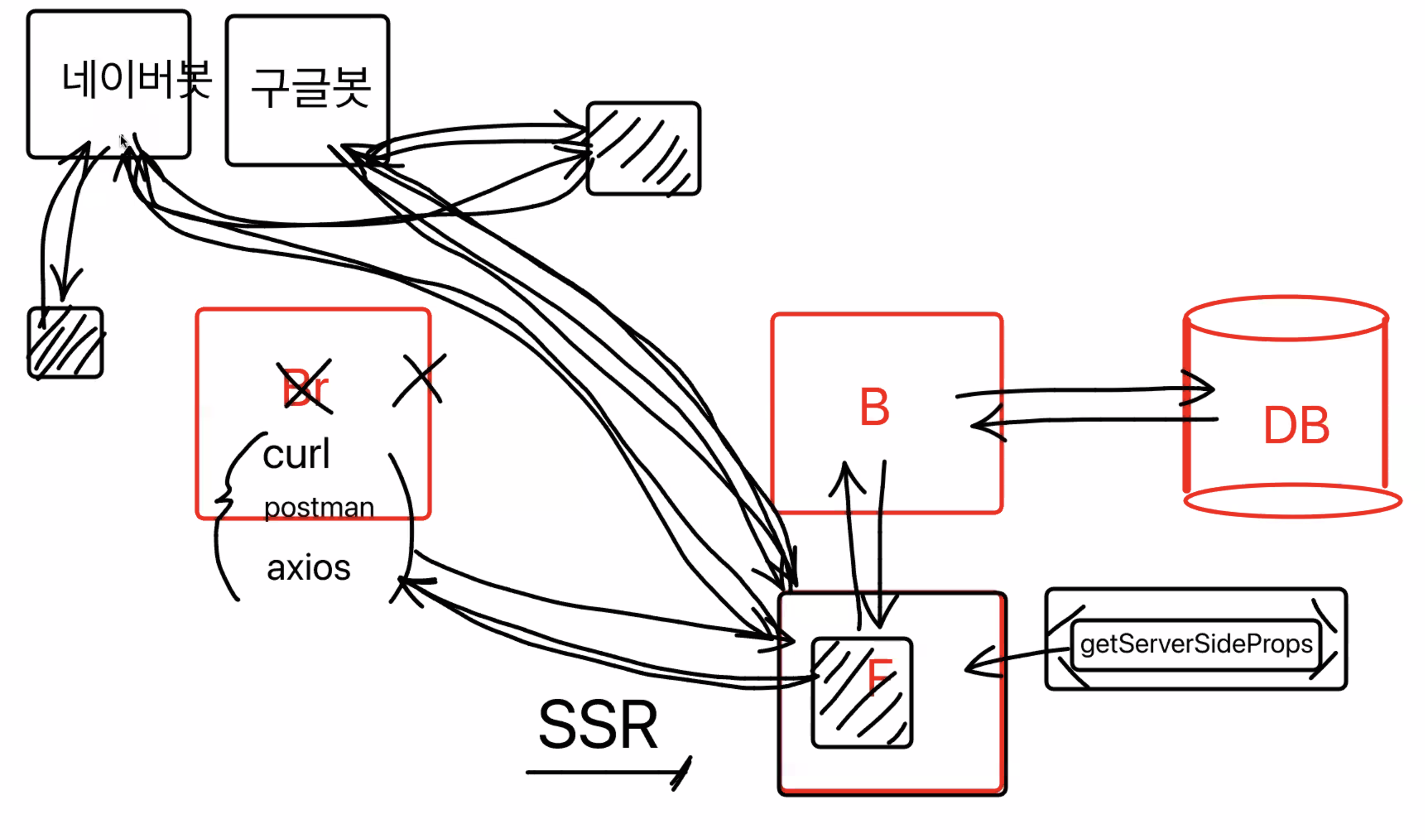
SSR
서버사이드에서 최종적으로 그린 후에 결과를 돌려주자
=> meta태그에 데이터가 채워져있는 채로 받아, 미리보기가 가능하다
next에서 제공하는 getServerSideProps
모든 경우에 서버사이드 렌더링을 사용하는 것은 아니고, 필요에 따라..
SEO(Search Engine Optimization)_검색 엔진 최적화
서버사이드렌더링을 하지 않았다면?
네이버, 구글등의 검색엔진에서 검색봇이 웹사이트를 스크롤링 하려고 할 때 useQuery를 통한 핵심 데이터가 빠져있게 된다. 검색점수가 낮게 되거나, 검색이 안될 가능성이 높다 => 상품 상세, 게시글 상세페이지
서버사이드 렌더링을 하게되면 html,css,js 받아올 때 이미 데이터를 모두 완벽히 받아와 보여주기 때문에 검색봇이 해당 사이트가 무슨 사이트인지 검색엔진에서 바로 파악할 수 있다
SSR : 서버에서 만들어서
SSG : 정적파일 만들기
