왜 Java 객체에 대해서 공부하고 싶었는지
JVM 의 GC 가 발생하는 원리를 알아보다가, 해시코드가 정확하게 객체의 어떤 부분에 저장되어 있는 값인지 알고 싶어졌다.
GC 에는 Mark 이라고 부르는, (쉽게 말해)GC 대상이 아닌 객체를 찾기 위해서 마킹(Marking) 하는 알고리즘 단계가 포함되어 있는데 이 때 참조하는 것이 객체의 메모리 주소 즉, 해시코드이다.
알아보다 보니, 이외에 많은 개념을 알게 되었고 Java 의 Lock 이라는 개념과 다형성이 어떻게 구현되고 있고 이루어져 있는지 조금 더 깊게 이해할 수 있게 된 것 같다.
Mark-And-Sweep
가비지 수집을 구현하기 위해서 사용하는 알고리즘이다. Mark 단계는 객체가 살아 있는지 검사하고 마킹(Marking) 라는 단계이고, Sweep 단계는 마킹한 객체를 메모리에 해제하는 단계이다.
자바의 객체는 어떻게 이루어져 있을까?
자바의 모든 객체는 OOP (Ordinary Object Pointer, 일반 객체 포인터) 라고 불리는 객체로 표현합니다. 쉽게 말하면 객체의 위치 정보나 메타정보를 담고 있는 단위 입니다.
OOP 는 C 에서 불리는 포인터와 유사합니다. (코드는 열어보니 C++ 로 작성되어 있었습니다)
class oopDesc {
friend class VMStructs;
friend class JVMCIVMStructs;
private:
volatile markWord _mark;
union _metadata {
Klass* _klass;
narrowKlass _compressed_klass;
} _metadata;
public:
inline markWord mark() const;
inline markWord mark_raw() const;
inline markWord* mark_addr_raw() const;
inline void set_mark(markWord m);
inline void set_mark_raw(markWord m);
static inline void set_mark_raw(HeapWord* mem, markWord m);
...
}인스턴스가 생성될 때 마다 인스턴스에 대한 정보를 담은 OOP 또한 같이 생성되어 메모리에 저장됩니다.
OOP를 사용하여 Java의 객체를 구현했을 때 성능상에 문제는 없을까?
C 를 공부한 사람은 malloc 이라는 메서드를 아시는 분이 계실 것 같습니다. 이는 메모리 할당을 할 때 공간을 확보하기 위해서 사용하는 메서드입니다. 이 함수를 호출하면 최종적으로 시스템콜이 호출되어 메모리가 프로세스에 할당됩니다.
그러나 Oop를 생성할 때는 JVM 이 확보한 메모리 영역 안에서 생성하기 때문에 새로운 메모리 할당을 위한 시스템 콜을 호출할 필요가 없습니다. 즉, 메모리 할당을 위한 "시스템콜"을 부르지 않기 때문에 Oop 라는 것을 이용하는게 성능상 문제가 되는 부분이 없다. (= 시스템콜 사용으로 인한 오버헤드는 없다.)
시스템콜을 호출하면 프로세스를 실행 중이던 CPU에 interrupt가 발생하게 되고, 이 후"사용자 모드"에서 "커널 모드"로 변경된다. 이 때 컨텍스트 스위칭이 일어나서 오버헤드가 발생하게 된다.
조금 더 깊게 파보자면 JVM 이 OOP 를 생성하는데 있어서, 메모리 주소에 직접 접근하지 않고 메모리 주소의 이정표 역할을 하는 "페이지 테이블"이라는 것을 보고 해당 위치에 OOP 를 생성하기 때문에 이미 시스템이 할당 받은 메모리 내에만 OOP 를 올리게 된다.
OOP 는 어떻게 이루어져 있을까?
OOP 에는 instanceOOP 와 Klass OOP 가 있습니다. 이름에서 알 수 있듯 instanceOOP 는 인스턴스와 관련이 있는 OOP 이고 Klass OOP 는 클래스 메타 정보와 관련이 있는 OOP 입니다.
instanceOOP 는 Mark Word 와 Klass Word 라고 부르는 두가지 헤더 + 실제 데이터로 구성됩니다. (물리적인 단위가 아니라 논리적인 단위로 생각됩니다)
instanceOOP
Mark Word
인스턴스의 메타데이터를 가리키는 포인터 입니다. 해시코드를 포함하고 있습니다. 32 비트 JVM 에서 다음과 같은 정보로 이루어져 있습니다.
- 25 비트 : 해시코드
- 4 비트 : age (GC 에서 몇번 살아 남았는지에 대한 정보)
- 1 비트 : biased_lock
- 2 비트 : lock
JDK 8 버전 Mark 의 소스를 보고 싶다면 여기
JDK 15 버전 Mark 의 소스를 보고 싶다면 여기
Klass Word
클래스의 메타 데이터를 가리키는 포인터. 즉, 클래스의 메타 정보에 대한 참조를 저장해둔 데이터 단위이고 C++ (기계어)로 작성된 포인터입니다.

instance oop 의 Mark Word 와 Klass Word 두 헤더 다음에 실제 데이터가 위치합니다. 이 데이터는 primitive 타입, reference 타입으로 참조할 수 있는 실제 데이터를 의미합니다.
예제
예를 들어서 Entry 인스턴스를 생성한다고 가정하고 위 두가지 헤더를 고려해서 OOP 의 크기를 계산해볼 예정입니다. 이 인스턴스가 총 사용하는 메모리 크기를 계산할 것입니다. 이 때 기준이 되는 것은 32-bit JVM 입니다.
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
// methods...
}Mark word 와 Klass word 는 각각 4바이트 짜리 기계어 입니다. (64-bit JVM 에서는 8바이트) 따라서 헤더의 크기는 8 바이트입니다. 전체 크기는 다음과 같습니다.
2개의 기계어 + 모든 인스턴스 필드의 크기
즉, 크기를 계산하면
2 개의 header word (8바이트) + 1 개의 int word (hash 필드 4바이트) + 3 개의 pointer word (나머지 필드 12바이트)
24 바이트가 됩니다.
Klass OOP
모든 Java 인스턴스가 메소드의 세부사항을 저장하고 있는 것은 매우 비효율 적입니다. 메서드는 정적인 자원, 즉 해당 코드가 변한다거나 하지 않기 때문에 모든 인스턴스의 메서드는 동일합니다. 즉, 인스턴스가 호출할 수 있는 메서드는 모두 동일하게 동작하기 때문에 공통된 장소에 메소드를 올려두고(공유) 이를 참조하는 것이 좋은 방법입니다.
klass word 는 Virtual Method Table (일명 vtable, 메서드에 대한 참조 값을 저장해둔 배열) 이라고 불리는 자료를 내부적으로 가지고 있습니다.
vtable 은 메서드에 대한 참조정보를 가지고 있는 자료구조입니다. 이를 통해서 메서드를 호출할 수 있게 됩니다.
Klass OOP 와 Class 객체와 다르다는 것을 주의!
- Class 객체 : 예를 들어 getClass()로 얻을 수 있는 인스턴스가 있다. 이는 자바의 객체이다. 다른 Java 인스턴스와 동일하게 instanceOops 로 취급되고 동일한 동작을 가지며 Java 변수로 참조할 수도 있습니다.
- KlassOOP 는 JVM이 클래스 메타데이터를 표현(저장)하기 위해서 사용하는 개념. vtable 이라는 구조를 이용해서 클래스의 메소드 정보를 참조합니다.
가상디스패치
디스패치란 런타임 중에 호출될 메서드를 결정하는 과정이다. 이는 다형성과 관련이 깊은 개념이다.
다형성
다형성은 쉽게 말하면 여러 타입의 인스턴스를 하나의 요소(여기서는 변수)에 집어 넣을 수 있는 성질
변수가 여러 타입의 인스턴스를 참조할 수 있기 때문에 변수의 타입만 보고는 해당 인스턴스가 실제로 가진 메서드가 어떤 것인지 정확하게 할 수 없다. 특히 부모 클래스의 메서드를 오버라이드 한 경우 그렇다. 따라서 실제 어떤 메서드를 호출할 것인지 결정하는 디스패치라는 개념이 필요하다.
Java 메서드를 호출할 때 점연산자 (offset 연산자)를 사용합니다.
public static void main(String[] args) {
TestClass testClass = new TestClass();
testClass.run(); // offset 연산자를 통해 run 이라는 메서드 호출
}offset 연산자 (점연산자, .)를 이용해 메서드를 호출하면 변수와 관계 없이 실제 인스턴스가 가진 메서드가 호출이 되는 방식으로 동작하는데 이는 메서드 이게 디스패치가 일어나는 방식이다.
vtable
KlassOop 에는 vtable 이라는 배열 공간을 가지고 있다. 여기에는 해당 객체가 실제로 바라보는 메서드에 대한 참조 정보가 들어있습니다. vtable 구조는 Java 의 메소드 디스패치 및 단일 상속과 직접적인 관련이 있는데 이에 대해서 설명해보려고 합니다.
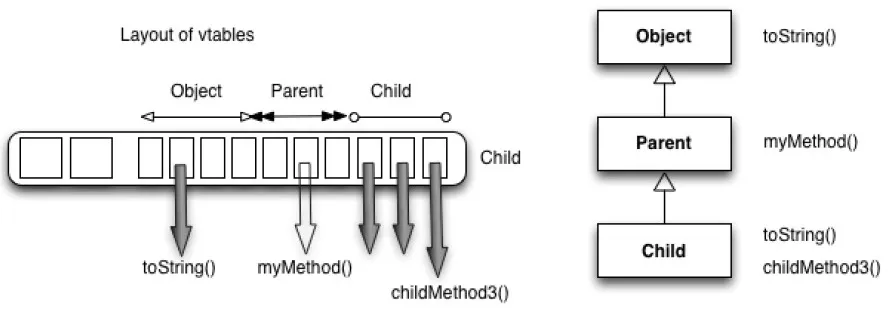
JVM 은 메모리에 올라간 메서드에 대한 참조정보를 vtable 의 특정 offset (=인덱스) 에 저장합니다. 예를 들어서 4번 offset (배열의 인덱스)에 toString() 이라는 메서드에 대한 참조정보를 저장할 수 있습니다.
한편, 메서드는 오버라이드 될 수 있습니다. 앞서 언급한 toString() 메서드로 예시를 들어보겠습니다. 모든 클래스는 Object 를 상속 받습니다. 부모 클래스의 toString() 메서드를 A 참조라고 부르고 자식 클래스의 toString() 메서드를 B 참조라고 부르겠습니다.
Object의 인스턴스가 4번 인덱스에 A 참조를 저장해두었다고 가정하면 부모 클래스의 인스턴스와, 자식 클래스의 인스턴스 모두 4번 인덱스에 참조(A,B)를 저장합니다. 이렇게 같은 인덱스에 오버라이드 된 메서드 정보를 저장하기 때문에 자바의 "상속" 계층 구조를 쉽게 구현할 수 있는 것입니다. 즉, 인스턴스가 바라볼 하나의 정보만 저장하기 때문에 자식 클래스의 인스턴스 입장에서 A 참조와 B 참조 중 어떤 것을 실제로 호출할지 고민할 필요가 없어집니다.
한편, 오버라이드 된 메서드는 이렇게 하나의 배열공간에 같은 offset 에 저장되기 때문에 단일 상속밖에 지원할 수가 없습니다. 참조인 인덱스를 vtable에 덮어쓰기 하는 방법으로 상속을 구현했기 때문입니다.
그리고 이 구조는 JIT 컴파일이 동작할 때 매우 강력한 최적화가 가능하게 합니다. (위 그림에서 Object 의 toString 메서드와 Child 의 toString 메서드 중 어떤 것을 호출하는지 알기 때문에 정확하게 counting 할 수 있고, 이런 counting 정보는 성능최적화의 일종인 JIT 컴파일을 하기 위한 참고 자료로 사용되는데 counting 정보가 정확할수록 성능최적화에 유리할 것이기 때문으로 추측)
.jpeg)