
포스팅에 사용된 그림은 책에서 제공하는 그림들 입니다.
❓수백만 사용자를 지원하는 시스템을 만드려면 어떻게 설계해야 할까
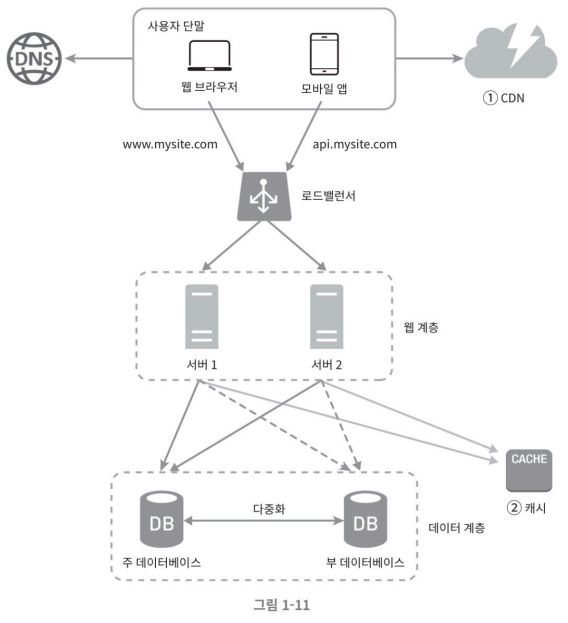
기본적인 단일 서버 예
웹, 앱, 데이터베이스, 캐시 등이 전부 서버 한 대에서 실행된다.
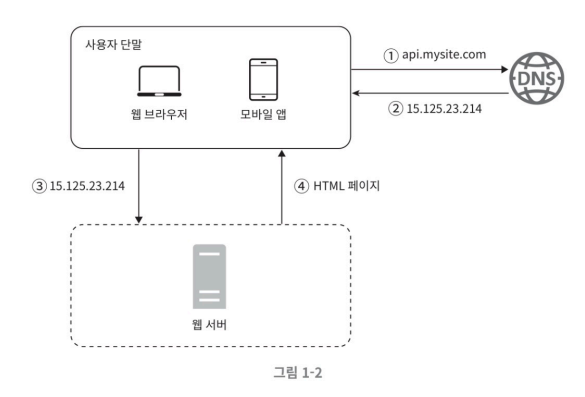
- 사용자는 웹 브라우저나 모바일 앱으로 api.mysite.com 도메인으로 접속을 한다
- api.mystie.com 도메인은 DNS서버에 의해 15.125.23.214로 번역된다.
- 15.125.23.214라는 IP를 가진 웹 서버로 전달이 된다.
- 웹서버는 사용자의 기기에 JSON OR HTML 페이지를 전달해 준다.
데이터베이스
사용자가 많으면 서버 하나로는 충분하지 않아 여러 서버를 두어야 한다.
하나는 웹/모바일 트래픽 처리 용도고 하나는 데이터 저장 용이다.
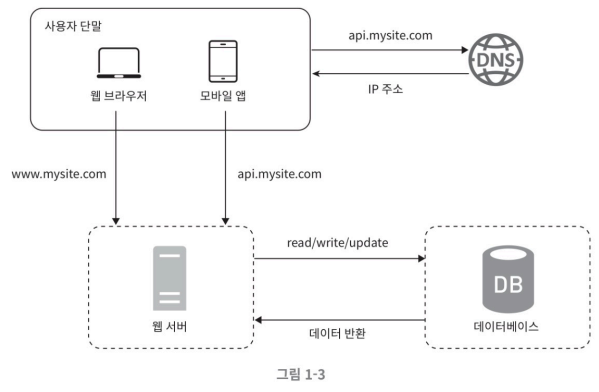
그림에서 보면 웹 서버는 트래픽 처리 용, 데이터베이스가 데이터베이스가 된다.
❓어떤 데이터베이스를 사용 해야 할까
관계형 데이터베이스 (RDBMS)와 비-관계형 데이터베이스 (NOSQL) 사이에서 고를 수 있다.
➡️ 대표적인 RDMBS
- MySQL, Orale, PostgresSQL
이들은 여러 테이블에 있는 관계를 join해서 사용한다.
➡️ 대표적인 비 관계형 데이터베이스 NoSQL
- CouchDB, Neo4j, Cassandra, HBase, Amazon DynamoDB, MongoDB 등이 있다. 이는 다시 4가지 부류로 나눌 수 있다.
- 키-값 저장소
- 그래프 저장소
- 칼럼 저장소
- 문서 저장소
💡 대부분의 개발자가 관계형 데이터베이스(RDBMS)를 사용하는 이유는 40년 이상 시장에서 살아남았기 때문이다.
비-관계형(NOSQL)을 사용하는 이유❓
- 아주 낮은 응답 지연시간(latency)이 요구됨
- 다루는 데이터가 비정형(unstructured)이라 관계형이 아님 join이 필요없다.
- 데이터(JSON, YAML, XML 등)을 직렬화 하거나 역직렬화 할 수 있기만 하면 됨
- 아주 많은 양의 데이터를 저장할 필요가 있음
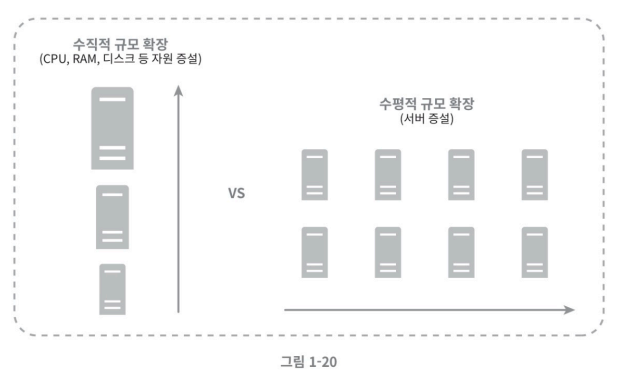
수직적 vs 수평적 규모 확장
수직적(스케일 업)
서버로 유입되는 트랙픽의 양이 적을 때는 수직적 확장이 좋은 선택이다 왜냐하면 단순하기 때문이다
하지만 아래와 같은 심각한 단점이 있다.
- 수직적 규모확장은 한계가 있다. 서버 한대에 무한대로 CPU와 같은 하드웨어를 무한대로 추가할 수 없기 때문
- 장애에 대한 자동복구나 다중화 방안을 제시하지 않는다. 장애가 생기면 웹사이트/앱은 완전히 중단된다.
수평적(스케일 아웃)
- 위 수직적 규모 확장의 단점들을 보완해 줄 수 있다.
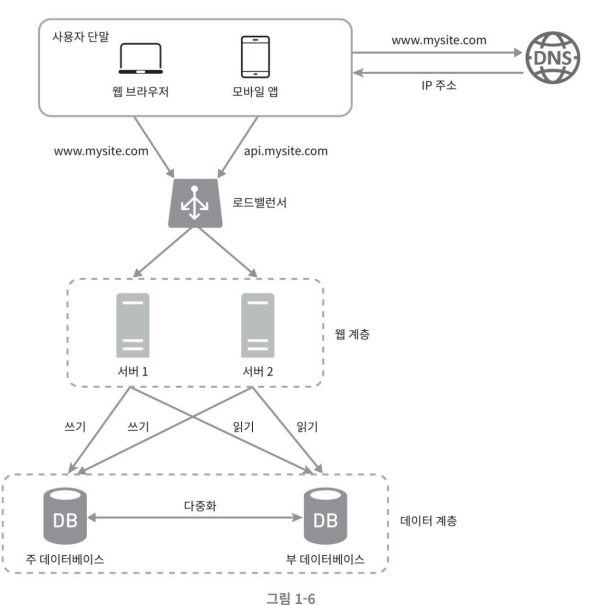
로드밸런서
로드밸런서는 웹 서버들에게 트래픽 부하를 고르게 분산하는 역할을 해준다.
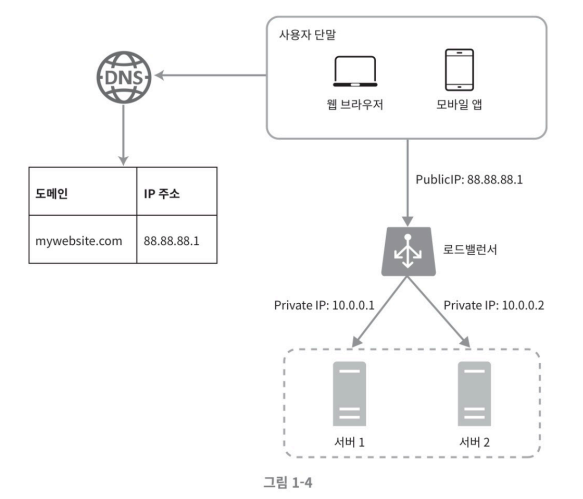
그림처럼 사용자의 단말기 들은 로드밸런서의 Public (공용 IP)로 접속하게 되고 로드밸런서는 트래픽을 적절히 분배하여 사설 IP(Private IP)를 사용하는 서버들로 사용자의 요청을 분배하게 된다.
💡 사설 IP는 같은 네트워크에 속한 서버 사이의 통신에만 사용할 수 있기에 보안이 향상됨
이렇게 부하 분산 집합에 웹 서버를 추가하고 나면 장애를 자동복구하지 못하는 문제(no failover)는 해소되고, 웹 계층의 가용성은 향상된다.
- 서버 1이 다운되면 부하 분산을 시켜주는 로드밸런서는 서버2 에게 모든 트래픽을 요청한다 따라서 웹사이트 전체가 다운되는 일이 방지 됨.
- 웹사이트로 유입되는 트래픽이 가파르게 증가하면 웹 서버 계층에 더 많은 서버를 추가하기만 하면 로드밸런서가 알아서 트래픽을 분산시켜 주기 때문에 확장이 쉽다.
데이터베이스 다중화
대부분의 데이터베이스 관리 시스템들은 다중화를 지원한다. 보통은 서버 사이에 주(master)-부(slave) 관계를 설정하고 데이터 원본은 주 서버에, 사본은 부 서버에 저장하는 방식이다.
쓰기(업데이트,삭제) 연산은 master서버에서만 지원하며 slave 데이터베이스는 master로부터 그 사본을 전달받으며 오직 read(읽기)연산 만을 지원한다. 대부분의 애플리케이션은 읽기 연산의 비중이 CUD(Create, Update, Delte)연산보다 비중이 훨씬 높기에 읽기만을 지원하는 slave 데이터베이스가 master 데이터베이스보다 더 많다.
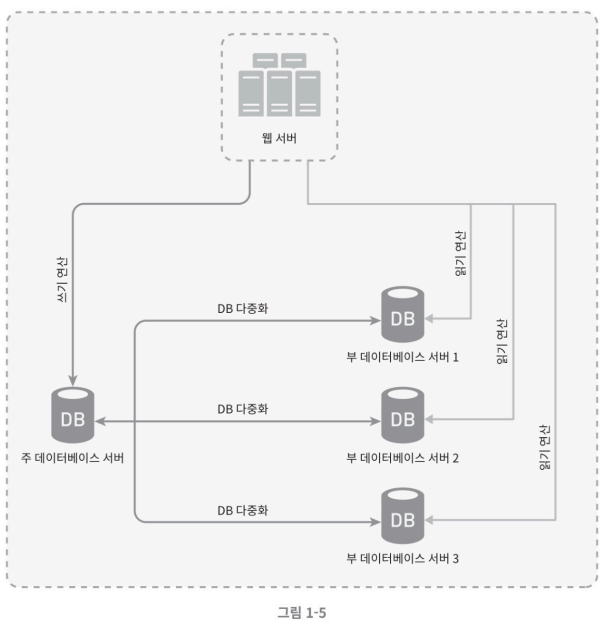
위 그림과 같이 slave db가 master db보다 더 많다.
데이터베이스 다중화의 장점
- 더 나은 성능: master-slave 모델에서 CUD연산은 master에서만 지원하고 수많은 slave db가 받으므로 성능이 좋아짐
- 안정성: 자연재해 등으로 db 서버 가운데 일부가 파괴되어도 데이터는 보존된다. 데이터를 지역적으로 멀리 떨어진 여러 장소에 다중화 시켜 놓을 수 있기 때문이다.
- 가용성: 데이터를 여러 지역에 복제해 둠으로써, 특정 서버가 다운되어도 다른 서버의 데이터를 가져다가 쓰면 되기 때문에 계속 서비스를 할 수 있다.
❗데이터베이스 서버 중 하나가 다운될 경우의 상황
- slave 서버가 한대 뿐인데 다운되면 일시적으로 모두 master가 읽기 연산도 포함하여 장애를 대처함
- master 서버가 다운될 경우 slave 서버 중 하나가 새로운 master 서버가 되어 장애를 대처 할 것이다.
- 실제 운영 환경에서 벌어지는 환경은 더 복잡하다, slave db의 데이터가 최신 상태가 아닐 수도 있기 때문이다. 없는 데이터는 복구 스크립트를 돌려서 추가 해야한다. 다중 마스터나 원형 마스터 방식을 도입하면 이런 상황을 대처하는 데 도움이 되지만 해당 구성들은 훨씬 복잡하다.
캐시
응답시간 개선에 사용
캐시는 값비싼 연산 결과 또는 자주 참조되는 데이터를 메모리 안에 두고, 뒤이은 요청이 보다 빨리 처리될 수 있는 저장소이다.
캐시 계층
캐시 계층은 데이터가 잠시 보관되는 곳으로 데이터베이스보다 훨씬 빠르다.
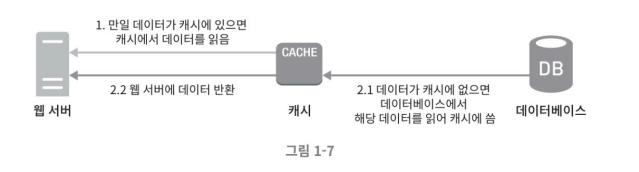
위 사진과 같이 계시 계층을 중간에 두면 데이터베이스의 부하를 줄일 수 있으며, 캐시 계층을 독립적으로 확장할 수 있다.
💡 **주도형 캐시 전략** 위 사진의 나와있는 1→2.1or2.2의 순서를 주도형 캐시 전략을 이라고 부른다.이것외에도 다양한 캐시 전략이 있는데, 캐시할 데이터 종류, 크기, 엑세스 패턴에 맞는 캐시 전략을 선택하면 된다.
❗캐시 사용 시 유의할 점
- 캐시는 어떤상황에 바람직한가? 데이터 갱신은 자주 일어나지 않지만 참조는 빈번하게 일어난다면 고려해볼만 하다.
- 어떤 데이터를 캐시에 두어야 하는가? 캐시는 데이터를 휘발성 메모리에 두므로, 영속적으로 보관할 데이터를 캐시에 두는 것은 바람직하지 않다. 예를 들어, 캐시 서버가 재시작 되면 캐시 내의 모든 데이터는 사라진다. 중요 데이터는 여전히 지속적 저장소에 두어야한다.
- 캐시에 보관된 데이터는 어떻게 만료(expire)되는가? 이에 대한 정책을 마련해 두는 것은 좋은 습관이다. 만료된 데이터는 캐시에서 삭제되어야 한다. 만료 정책이 없으면 데이터는 캐시에 계속 남아있기 떄문이다. 만료 기한은 너무 짧으면 곤란한데, 데이터베이스를 너무 자주 읽게 될 것이기 때문이다. 너무 길어도 곤란한데, 원본과 차이가 날 가능성이 높기 때문이다.
- 일관성은 어떻게 유지되는가? 일관성은 데이터 저장소의 원본과 캐시 내의 사본이 같은지 여부다. 저장소의 원본을 갱신하는 연산과 캐시를 갱신하는 연산이 단일 트랜잭션으로 처리되지 않는 경우 이 일관성은 깨질 수 있다. 여러 지역에 걸쳐 시스템을 확장해 가는 경우 캐시와 저장소 사이의 일관성을 유지하는 것은 어려운 문제가 된다.
- 장애에는 어떻게 대처할 것인가? 캐시 서버를 한 대만 두는 경우 해당 서버는 단일 장애 지점(SPOF)이 되어버릴 가능성이 있다.
SPOF(단일 장애 지점)를 피하려면 여러 지역에 걸쳐 캐시 서버를 분산시켜야한다.
- 캐시 메모리는 얼마나 크게 잡을 것인가?
- 데이터 방출 정책은 무엇인가? 대표적으로 널리 쓰이는
- LRU(Leaset Recently Used -마지막으로 사용된 지점이 가장 오래된 데이터를 내보내는 정책)이다.
- LFU(Lease Frequently Used -사용된 빈도가 가장 낮은 데이터를 내보내는 정책)
- FIFO(First In First Out - 가장 먼저 캐시에 들어온 데이터를 가장 먼저 내보내는 정책) 같은 것들이 있다.
콘텐츠 전송 네트워크(CDN)
CDN은 정적 콘텐츠를 전송할 때 쓰이는 분산 네트워크다. HTML, 이미지, 비디오, CSS, JS 파일등을 캐시할 수 있다.
💡 CDN은 정적 콘텐츠를 캐시한다. 동적 콘텐츠 캐싱은 어떻게 할까?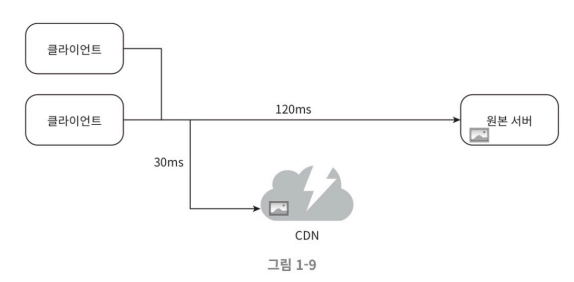
CDN 이 대충 어떻게 동작하는 가에 대한 사진이다. 당연히 거리가 멀면 멀수록 웹사이트는 천천히 로드된다.
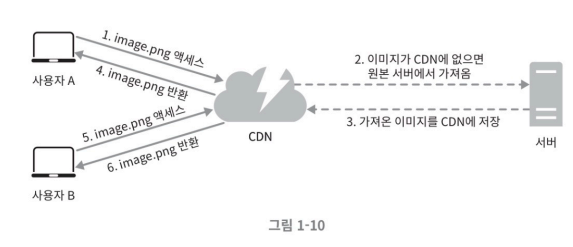
CDN이 어떻게 동작되는가에 대해 자세히 알아보자.
- 사용자는 이미지 URL을 이용해 image.png에 접근한다
- CDN 서버의 캐시에 이미지가 없는 경우 원본서버에 접근하여 이미지를 요청한다
- CDN 서버는 요청한 파일을 서버 캐시에 저장한다. 응답의 HTTP 헤더에는 파일이 얼마나 오래되었는지에 대한 TTL(Time-To_Live) 값이 들어있다.
- CDN 서버는 파일을 캐시하고 사용자에게 반환한다. 이미지는 TIL에 명시된 시간이 끝날 떄 까지 캐시된다.
- 다른 사용자가 같은 이미지에 요청을 하면
- CDN은 캐시에 저장되어있는 이미지를 바로 반환 해준다.
CDN 사용 시 고려해야할 상황
- 비용: CDN은 보통 제 3 사업자에의해 운영되며, 데이터 전송 양에 따라 요금을 내게된다. 자주 사용되지 않는 파일을 캐싱하는것은 이득이 크지 않으므로 CDN에서 빼는것을 고려해야한다.
- 적절한 만료 시한 설정: 시의성이 중요한(time-sensitive) 콘텐츠의 경우 만료 시점을 잘 정해야 한다. 길면 콘텐츠의 신서도가 떨어질 것이고, 너무 짧으면 서버에 빈번히 접속하게 되어 좋지않다.
- CDN 장애에 대한 대처 방안: CDN 자체가 죽었을 경우 웹사이트/애플리케이션이 어떻게 동작해야 하는지 고려해야 한다. CDN서버에 장애가 발생해도 클라이언트 단에선 장애를 인지하고 원본서버에서 직접 콘텐츠를 가져오도록 구성해야 한다.
- 콘텐츠 무효화 방법: 아직 만료되지 않은 콘텐츠라 하더라도 아래 방법 중 하나를 쓰면 CDN에서 제거할 수 있다.
- CDN 서비스 사업자가 제공하는 API를 이용하여 콘텐츠 무효화
- 콘텐츠의 다른 버전을 서비스하도록 오브젝트 버저닝이용. 콘텐츠의 새로운 버전을 지정하기 위해서는 URL 마지막 버전 번호를 인자로 주면 된다.
변화된 부분은
- 정적 콘텐츠는 더 이상 웹서버를 통해 서비스하지 않으며 CDN을 통해 더 나은 성능을 보장
- 캐시가 DB 부하를 줄여줌
무상태 웹 계층
이젠 웹 계층을 수평적으로 확장하는 방법을 고민해보자. 이를 위해서는 상태 정보(사용자 세션 데이터와 같은)를 웹 계층에서 제거해야 한다. 바람직한 전략은 상태 정보를 관계형 DB나 NoSQL같은 지속성 저장소에 저장하고, 필요할 때 가져오도록 해야 한다. 이렇게 상태 정보가 없는 웹 계층을 무 상태 웹 계층이라고 표현한다.
상태 정보 의존적인 아키텍처
상태 정보를 보관하는 서버와 그렇지 않은 서버 사이에는 몇 가지 중요한 차이가 있다. 상태 정보를 보관하는 서버는 클라이언트 정보, 즉 상태를 유지하여 요청들 사이에 공유되도록 해야한다.
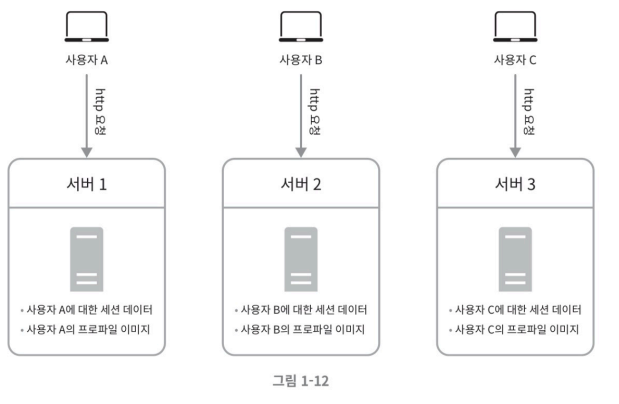
상태 정보 의존적인 아키텍처 사진
이렇게 되면 A는 무조건 서버 1에서 요청을 해줘야 하고, B는 서버2, C는 서버 3에서만 응답을 해주어야 된다. 로드밸런서는 트래픽 부하를 줄이기 위해 사용하는 것인데, 이미 세션이 물려있으면 같은 서버에서만 계속 응답을 해주어야 한다. 이를 위해 로드밸런서는 고정 세션이라는 기능을 제공하지만, 이는 로드밸런서에 부담을 주게된다. 또한, 로드밸런서 뒷단에 서버를 추가하거나 제거하기도 까다로워진다.
무상태 아키텍처
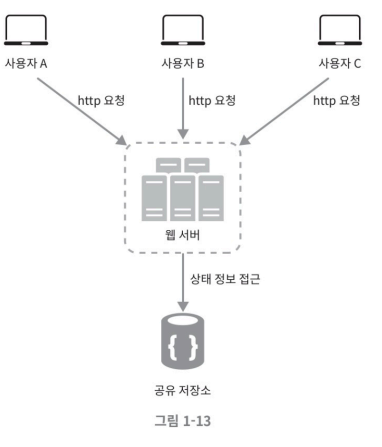
반면, 무상태 아키텍처에서는 어떤 사용자든 어떤 서버로도 응답이 가능해진다. 웹 서버는 상태 정보가 필요할 경우 공유저장소(데이터베이스)로 부터 데이터를 가져오면 되기 때문이다.
이러한 구조는 단순하고, 안정적이며, 규모 확장이 쉽다.
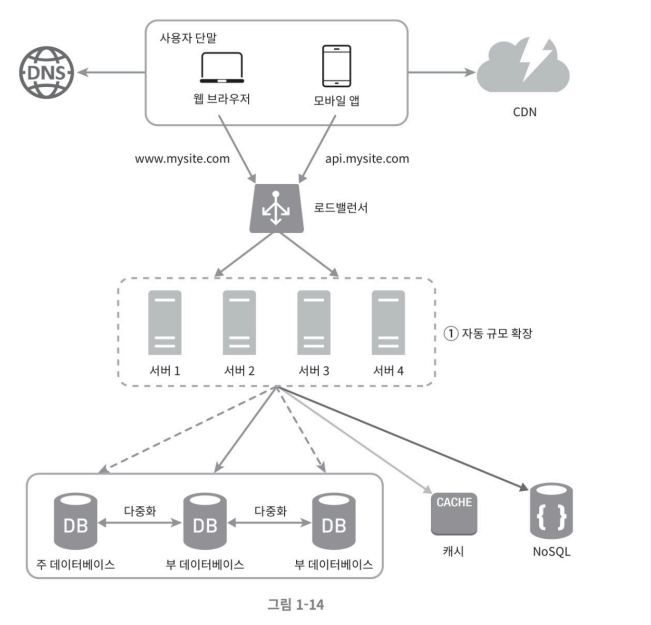
이 공우저장소는 RDBMS 일 수도 있고 NoSQL일 수도 있다. 위 사진은 NoSQL을 선택한 것을 볼 수있는데, 규모 확장이 편해서이다. 1 자동 규모 확장(auto scaling)은 트래픽 양에 따라 웹 서버를 넣거나 빼기만 하면 자동으로 규모를 확장할 수 있게 되었따.
만약, 자신이 만든 서비스가 전세계에서 많이 사용되는 서비스라면 쾌적한 환경을 위해 여러 데이터센터를 지원하는 것이 필수다.
데이터 센터
아래 그림은 두 개의 데이터 센터를 이용하는 사례다. 장애가 없는 상황에서 사용자는 가장 가까운 데이터 센터로 안내되는데, 이를 지리적 라우팅(geoDNS-routing 또는 geo-routing)이라고 부른다. 지리적 라우팅에서의 geoDNS는 사용자의 위치에 따라 도메인 이름을 어떤 IP주소로 변환할지 결정할 수 있도록 해 주는 DNS 서비스다.
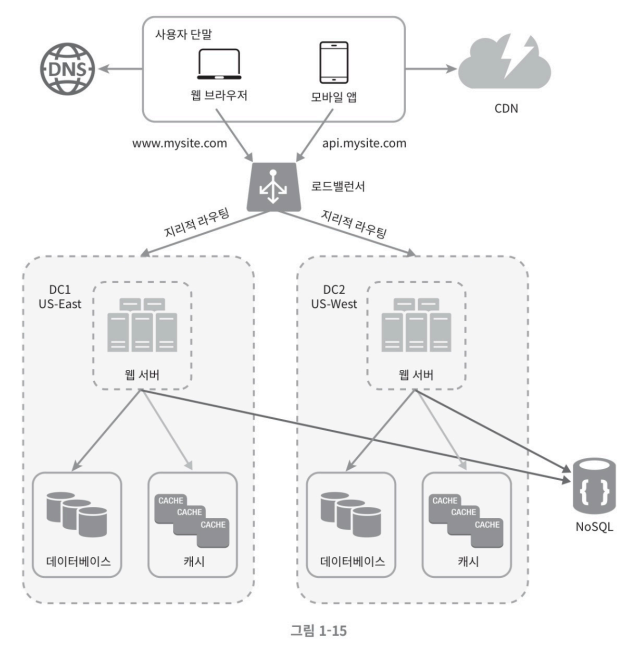
이들 데이터 센터 중 하나에 심각한 장애가 발생하면 모든 트래픽은 장애가 없는 데이터 센터로 전송된다.
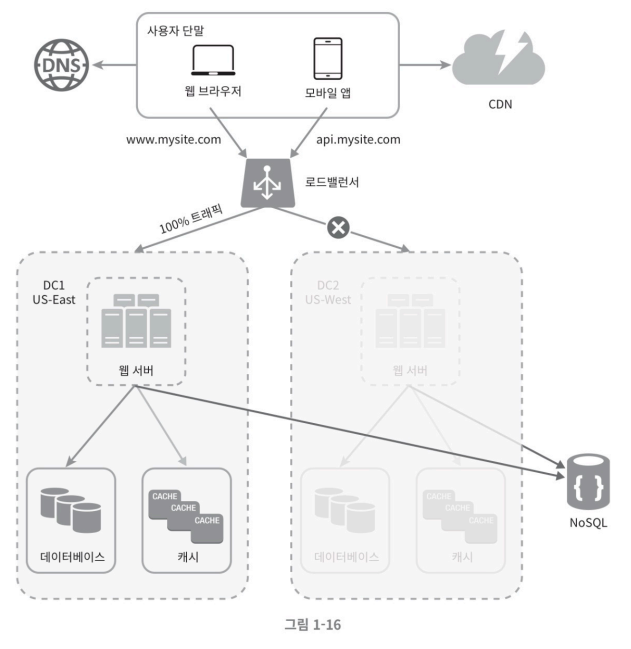
이렇게 구성하고자 하면 몇 가지 기술적 난제를 해결해야 한다.
- 트래픽 우회: 올바른 데이터 센터로 트래픽을 보내는 효과적인 방법을 찾아야 한다. GeoDNS는 사용자에게서 가장 가까운 데이터센터로 트래픽을 보낼 수 있도록 해준다.
- 데이터 동기화: 데이터 센터마다 별도의 데이터베이스를 사용하고 있는 상황이라면, 장애가 자동으로 복구되어 트래픽이 다른 db를 우회된다 해도, 해당 데이터센터에는 찾는 데이터가 없을 수도 있다. 이런 상황을 막는 보편적인 전략은 데이터를 여러 데이터센터에 걸쳐 다중화하는 것이다.
- 테스트와 배포: 여러 데이터 센터를 사용하도록 구성한 상태라면 웹 사이트 또는 애플리케이션을 여러 위치에서 테스트 해 보는 것이 중요하다. 자동화된 배포 도구는 모든 데이터 센터에 동일한 서비스가 설치되도록 하는 데 중요한 역할을 한다.
시스템을 더 큰 규모로 확장하기 위해서는 시스템의 컴포넌트를 분리하여, 각기 독립적으로 확장될 수 있도록 해야 한다. 메시지 큐는 많은 실제 분산 시스템이 이 문제를 풀기 위해 채용하고 있는 핵심적 전략가운데 하나다.
메시지 큐
메시지 큐는 메시지의 무손실 즉, 메시지 큐에 일단 보관된 메시지는 소비자가 꺼낼 때까지 안전히 보관된다는 특성을 보장하는, 비동기 통신을 지원하는 컴포넌트다. 메시지 큐의 기본 아키텍처는 간단하다. 생성자 or 발행자 (producer/publisher) 라고 불리는 입력 서비스가 메시지를 만들어 메시지를 발행(publish)한다. 큐에는 보통 소비자 또는 구독자(consumer/subscriber)라 불리는 서비스 혹은 서버가 연결되어 있는데, 메시지를 받아 그에 맞는 동작을 수행한다.

메시지 큐를 이용하면 서비스 또는 서버 간의 결합이 느슨해져서, 규모 확장성이 보장되어야 하는 애플리케이션을 구성하기 좋다. ‘소비자’는 생산자 서비스가 가용한 상태가 아니더라도 메시지를 수신할 수 있다.
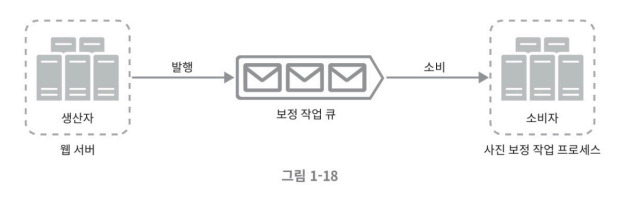
위 사진 처럼 웹서버가 발행한 메시지를 사진 보정 작업 프로세스(worker)들이 각각 독립적으로 확장 될 수 있다. 큐의 크기가 커지면 더많은 작업 프로세스가 추가해야 처리 시간을 줄일 수 있다. 반대로 큐가 거의 항상 비어있는 상태라면 작업 프로세스의 수는 줄일 수 있다.
로그, 메트릭 그리고 자동화
규모가 커지면 로그, 메트릭, 자동화 에 필수적으로 설계 해야 한다.
- 로그: 시스템의 오류와 문제들을 쉽게 찾아낼 수 있게 해준다. 서버 단위로 모니터링 할 수도 있지만 로그를 단일 서버로 모아주는 도구를 활용하면 더 편리하게 검색 및 조회할 수 있다.
- 메트릭: 사업 현황에 관한 유용한 정보를 얻을 수도 있고, 시스템의 현재 상태를 손쉽게 파악할 수 있다.
- 호스트 단위 메트릭: CPU, 메모리, 디스크 I/O에 관한 메트릭이 겨이 해당
- 종합 메트릭: 데이터베이스 계층의 성능, 캐시 계층의 성능같은 것이 여기 해당
- 핵심 비즈니스 메트릭: 일별 능동 사용자, 수익, 재방문 같은 것이 여기 해당
- 자동화: 시스템이 크고 복잡해지면 생산성을 높이기 위해 자동화 도구를 활용해야 한다. 지속적 통합(continuous integration)을 도와주는 도구를 활용하면 개발자가 만드는 코드가 어떤 검증 절차를 자동으로 거치도록 할 수 있어서 문제를 쉽게 감지할 수 있다. 이 외에도 빌드, 테스트, 배포 등의 절차를 자동화할 수 있어서 개발 생산성을 크게 향상시킬 수 있다.
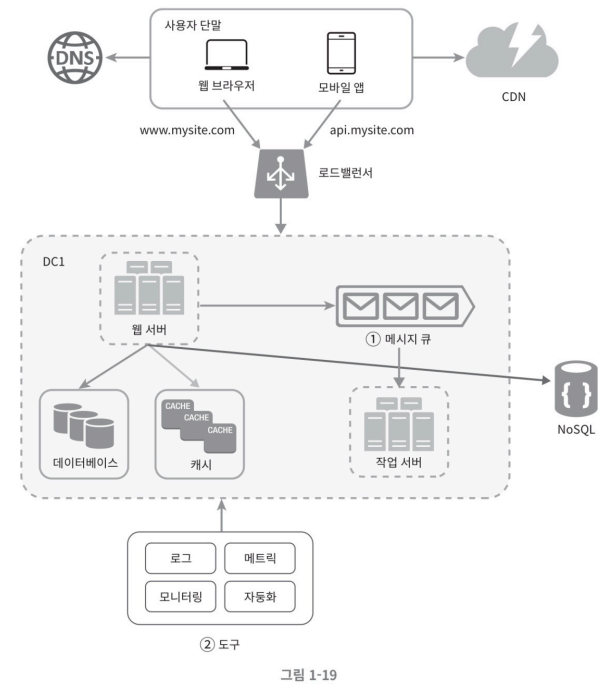
메시지 큐,로그,메트릭,자동화 등을 반영하여 수정한 설계안
- 메시지 큐는 각 컴포넌트가 느슨히 결합될 수 있도록 하고, 결함에 대한 내성을 높인다.
- 로그, 모니터링, 메트릭, 자동화 등을 지원하기 위한 장치를 추가했다.
데이터베이스의 규모 확장
저장할 데이터가 많으면 데이터베이스에 대한 부하도 증가한다. 데이터베이스는 어떻게 증설해야할까? 데이터베이스 수직적/수평적 규모 확장을 알아보자.
수직적 확장
스케일 업이라고도 부르는 수직적 규모 확장법은 hardware를 늘리는것이다.
수평적 확장
데이터베이스의 수평적 확장을 샤딩이라고도 부르는데, 더 많은 서버를 추가함으로써 성능을 향상시킬 수 있도록 한다.
데이터베이스 수평적 확장 - 샤딩
샤딩은 대규모 데이터베이스를 샤드라고 부르는 작은 단위로 분할하는 기술을 일컫는다. 모든 샤드의 스키마는 동일하지만 데이터의 중복은 없다.
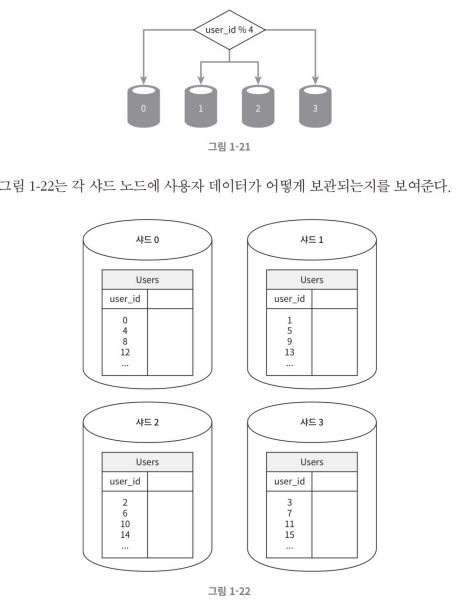
위 그림은, 샤드로 분할된 데이터베이스를 어떤식으로 사용 되는지에 대한 사진이다.
샤딩 전략을 구현할 때 가장 중요한 것은 샤딩 키를 어떻게 정하느냐 이다.
샤딩 키는 파티션 키라고도 부르는데, 데이터가 어떻게 분산될지 정ㅎ는 하나 이상의 컬럼으로 구성된다. 샤딩 키는 데이터를 고르게 분할 할 수 있도록 하는게 가장 중요하다.
샤딩은 DB 규모를 확장시키는데 훌륭한 기술이지만 완벽하진 않다. 샤딩을 도입하면 시스템이 복잡해지고 풀어야 할 새로운 문제도 생긴다.
- 데이터의 재 샤딩: 데이터가 너무 많아져서 하나의 샤드로는 감당이 안될때. 샤드 간 데이터 분포가 균등하지 못해서 특정 샤드에 할당된 공간 소모가 다른 샤드보다 빠르게 진행될 때(샤드 소진) 이런 문제가 생기면 샤드키 계산 방법을 다시 바꿔야한다. (안정 해시 기법을 활용하면 이 문제 해결 가능)
- 유명인사 문제: 핫스팟 키라고도 부른다. 특정 샤드에 질의가 집중되어 서버에 과부하가 걸리는 문제다. 유명한 저스틴 비버, 레이디 가가 같은 유명인사가 모두 같은 샤드에 저장되어 있다고 가정하면, 이 샤드는 read 연산 때문에 과부하가 걸리게 될 것이다. 이 문제는 유명인사 각각에 샤드를 하나씩 할당해야 할 수도 있고, 심지어는 더 잘게 쪼개야 할 수도 있다.
- 조인과 비정규화: 1개의 데이터베이스를 여러 샤드 서버로 쪼개면, 여러 샤드에 걸친 데이터를 조인하기 힘들어진다. 이를 해결하는 한 가지 방법은 DB를 비정규화 하나의 테이블에서 질의 수행되도록 하는 것이다.
최종 구조
사진은 데이터베이스에 대한 부하를 줄이기 위해 RDBMS가 아닌 NoSQL로 이전한 사진이다.
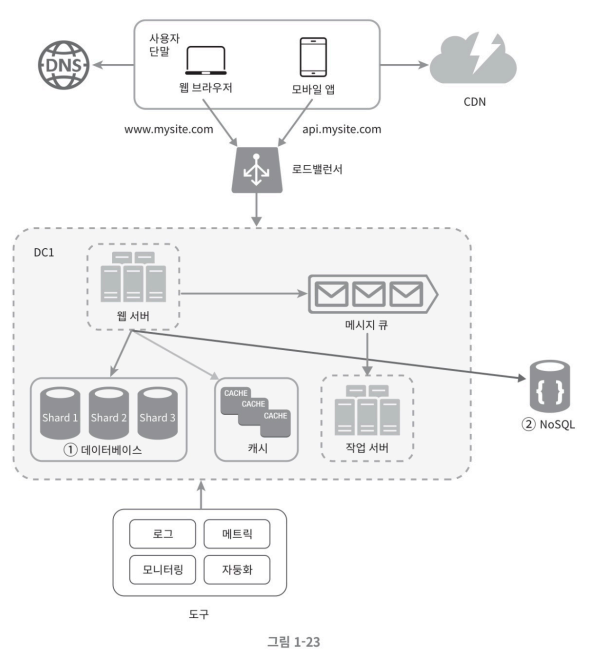
트래픽이 몰릴 경우에 대비한 모든 계층의 다중화와 캐시를 활용한 캐시서버, CDN등을 활용한 구조이다.

좋은 글 감사합니다.