빅엔디안이란?
이 방식은 사람이 평소 사용하는 방식대로, 메모리에 저장된 순서를 그대로 볼 수 있어서 이해하기 쉽다.
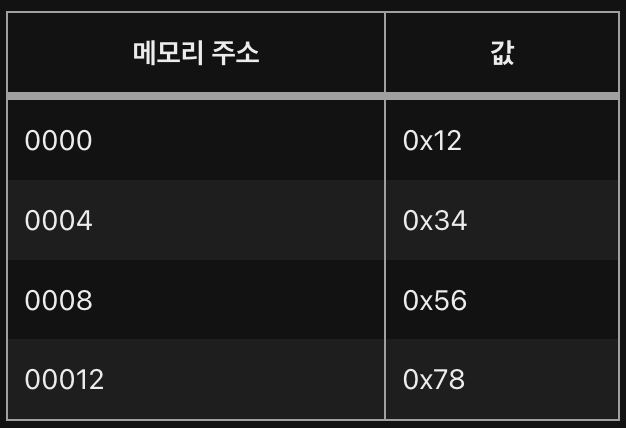
빅엔디안의 예
0x12345678 라는 32bit의 숫자를 빅엔디안으로 표시해보자.
0x12345678는 각 4개의 byte(4bit*8=32bit)로 나뉘어 0x12, 0x34, 0x56, 0x78로 나뉘며
아래와 같이 저장된다.
| 메모리 주소 | 값 |
|---|---|
| 0000 | 0x12 |
| 0004 | 0x34 |
| 0008 | 0x56 |
| 00012 | 0x78 |
리틀엔디안이란?
낮은 메모리 주소에 낮은 데이터 바이트 부터 저장하는 방식이다. (LSB: Least Sinificant Btye)
리틀엔디안의 예
위 빅엔디안의 예처럼 0x12345678을 예로 들면 아래와 같이 저장된다.
| 메모리 주소 | 값 |
|---|---|
| 0000 | 0x78 |
| 0004 | 0x56 |
| 0008 | 0x34 |
| 00012 | 0x12 |
빅엔디안과 리틀엔디안의 비교
숫자를 계산
리틀엔디안 방식은 낮은 데이터의 바이트 부터 저장하기에, 사람이 덧셈과 같은 계산을 할때와 같은 방식으로 계산할 수 있기에 리틀 엔디안이 좀더 빠르다고 할 수 있다. 왜냐하면 가장 낮은자리 수부터 계산하여 올림or내림 할 숫자가 있는지를 판단할 수 있기 때문이다.
숫자를 비교
숫자를 비교하는 부분에 있어선 가장 높은 데이터의 바이트 부터 저장하는 방식인 빅엔디안이 유리할 것이다. 높은 숫자 부터 비교해 숫자를 비교할 수 있기 때문이다.
디버깅
또한, 보통 사람이 사용하는 방식 그대로 저장하는 빅 엔디안이 디버깅에 편할 것이다.
엔디안은 무엇에 의해 지정될까?
엔디안 방식은 CPU가 어떤 엔디안을 사용하는지에 따라 달라진다.
| 리틀 엔디안 | 빅 엔디안 |
|---|---|
| Intel | IBM |
| AMD | SPARC |
CPU 제조사마다 엔디안을 사용하는 것이 다르다.
일반적으로 자주 사용되는 데스크톱 CPU는 리틀엔디안이다.
위에 숫자를 비교하는 부분과 디버깅 부분을 보면 빅엔디안이 좀더 효율적인것 같은데,
왜 자주 볼 수 있는 CPU(Intel, AMD)는 리틀엔디안 일까?
이유는 x86(32bit)아키텍처가 리틀 엔디안을 사용하기 때문에 주로 사용되는 데스크톱용의 CPU는 Intel이나AMD인 것이다.
네트워크 전송시의 엔디안
네트워크 전송시의 엔디안 방식은 빅엔디안으로 역사적으로 통일 되어있다.
따라서, 주로 사용되는 데스크톱은 리틀엔디안 방식이기에
네트워크 전송전 리틀엔디안 순서로 되어있는 메모리 순서를 → 빅엔디안 순서로 변경 후 전송하게 된다.
