python 주로 사용되는 모듈
| 항목 | Matplotlib | Seaborn (Matplotlib위에 구축됨) |
|---|---|---|
| 목적 | 기본적인 데이터 시각화 라이브러리 | 통계적 데이터 시각화에 중점을 둔 고수준 인터페이스 |
| 기능성 | 다양한 플롯 유형과 세부 조정 가능 | 통계적 플롯 유형과 기본 스타일링 제공 |
| 사용 용이성 | 다소 복잡하고 세부 조정 필요 | 간단하고 직관적인 API 제공 |
| 통계적 지원 | 통계적 기능이 부족 | 기본적으로 통계적 기능 지원 |
| 기본 스타일 | 기본 스타일이 단순함 | 기본 스타일이 더 세련되고 시각적으로 매력적 |
| 테마 | 기본 테마 외에 별도의 설정 필요 | 다양한 기본 테마와 스타일 제공 |
| 확장성 | 고도로 사용자 정의 가능 | Matplotlib 기반으로 확장 가능 |
| 복잡한 플롯 | 복잡한 플롯을 그리는 데 적합 | 복잡한 플롯 구현은 Matplotlib보다 어려울 수 있음 |
| 데이터 핸들링 | 기본 데이터 핸들링 기능 | Pandas DataFrame과의 통합이 우수 |
| 히스토그램 | 히스토그램을 위한 다양한 옵션 제공 | 히스토그램 및 커널 밀도 추정 플롯을 쉽게 생성 |
| 시작하기 | 더 많은 설정과 코드 필요 | 기본 플롯을 빠르게 생성 가능 |
| 컬러 팔레트 | 별도의 컬러 팔레트 설정 필요 | 다양한 기본 컬러 팔레트 제공 |
Matplotlib 공식문서
Quick start guide — Matplotlib 3.9.0 documentation
seaborn 공식문서
API reference — seaborn 0.13.2 documentation
Matplotlib, Seaborn 기본 개념(?)
Seaborn은 Matplotlib위에 구축되어있기에
결국 그래프를 표시할때는 Matplotlib의 show()함수로 표시하게 된다.
아무것도 없는 백지 그리기
import matplotlib.pyplot as plt
# 빈 Figure 생성
monitor_size = [6.4, 4.8]
fig = plt.figure(figsize=monitor_size) # https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.figure.html
num_graph = (1, 1, 1) # nrows, ncols, index
fig.add_subplot(*num_graph) # https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.subplot.html
# Figure를 보여줌
plt.show()
monitor_size와 num_graph는 각각 figure()와 add_subplot()의 기본값이다.
add_subplot은 총 몇개의 그래프를 nrows, ncols, index 별로 그릴것인가 인데 일단 백지를 그리고 싶었기에 총 1*1개의 그래프의 1번째에 백지를 그리는 것이다.
제목, x축 라벨, y 축라벨 그래프에 표시
import matplotlib.pyplot as plt
# 빈 Figure 생성
fig = plt.figure() # https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.figure.html
fig.add_subplot() # https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.subplot.html
plt.title('This is Title')
plt.xlabel('X Label')
plt.ylabel('Y Label')
# Figure를 보여줌
plt.show()
plt.title()은 그래프의 제목
plt.xlabel()은 x축의 이름
plt.ylabel()은 y축의 이름 을 할당해줄 수 있다.
막대그래프
주로 범주형 데이터를 살펴볼때 사용한다.
Matplot 사용
import numpy as np
import matplotlib.pyplot as plt
# 데이터 설정
categories = ['A', 'B', 'C', 'D', 'E']
values1 = [10, 24, 36, 12, 25]
values2 = [15, 18, 25, 22, 30]
# 막대의 위치 설정
x = np.arange(len(categories)) # 카테고리의 위치
width = 0.35 # 막대의 너비
# 그림 설정
plt.figure(figsize=(10, 6))
# 막대그래프 그리기
plt.bar(x - width/2, values1, width, label='Group 1', color='skyblue')
plt.bar(x + width/2, values2, width, label='Group 2', color='lightgreen')
# 제목과 축 레이블 설정
plt.title('Grouped Bar Chart')
plt.xlabel('Categories')
plt.ylabel('Values')
plt.xticks(x, categories) # x축 눈금을 카테고리 이름으로 설정
plt.legend() # 범례 표시
# 그래프 표시
plt.show()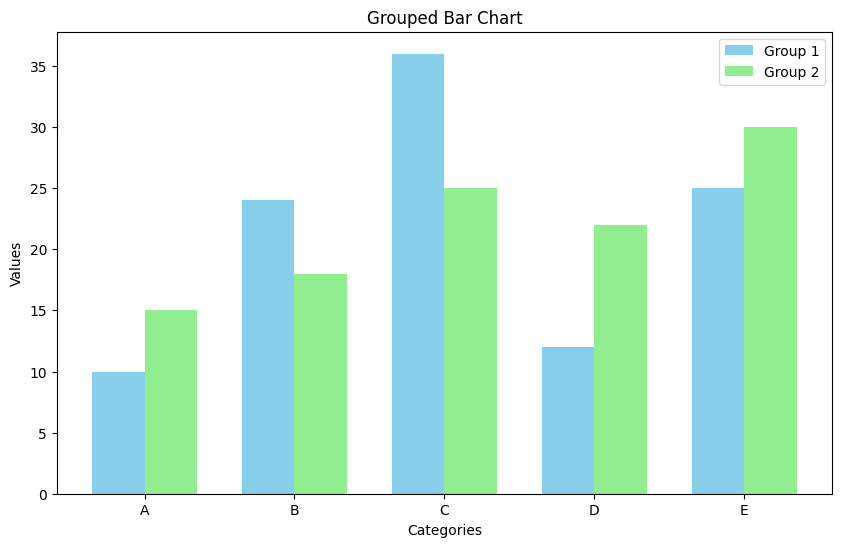
plt.bar는 막대그래프를
plt.xticks()는 x 축의 눈금을 표시 해주는것이고
plt.legend()는 범례를 표시해준다.
Seaborn 사용
같은 막대그래프를 Seaborn으로 그리는 코드를 작성해보면 아래와 같다.
# https://seaborn.pydata.org/generated/seaborn.barplot.html
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
# 데이터 설정
categories = ['A', 'B', 'C', 'D', 'E']
values1 = [10, 24, 36, 12, 25]
values2 = [15, 18, 25, 22, 30]
# DataFrame으로 데이터 변환
data = pd.DataFrame({
'Category': categories * 2,
'Values': values1 + values2,
'Group': ['Group 1'] * len(categories) + ['Group 2'] * len(categories)
})
# 그림 설정
plt.figure(figsize=(10, 6))
# Seaborn을 사용한 막대그래프 그리기
sns.barplot(data=data, x='Category', y='Values', hue='Group', palette=['skyblue', 'lightgreen'])
# 제목과 축 레이블 설정
plt.title('Grouped Bar Chart')
plt.xlabel('Categories')
plt.ylabel('Values')
# 그래프 표시
plt.show()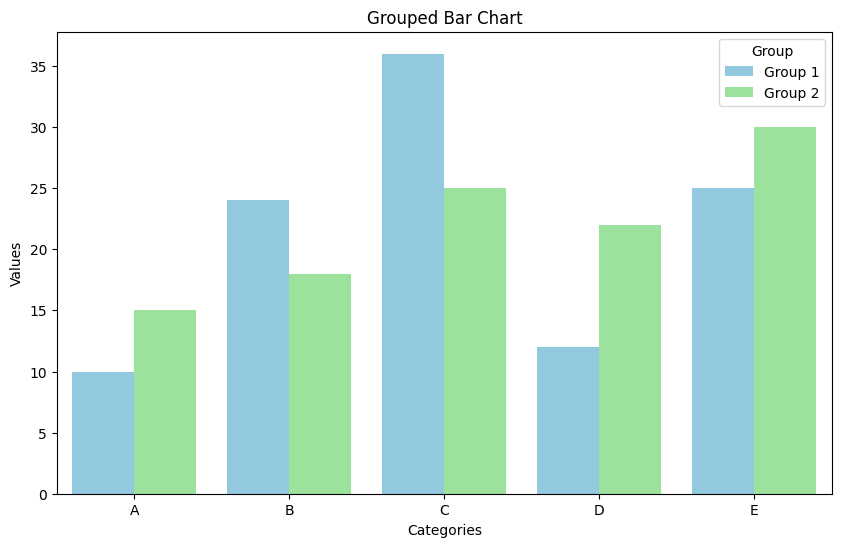
sns.barplot의 매개변수로 data, x, y, hue등 한줄로 Matplot의 막대그래프보단 좀더 간편하게 같은 그래프를 그릴 수 있다. 각 매개변수는
공식문서의 매개변수 설명중 일부
Parameters (매개변수):
- data: DataFrame, Series, dict, array 또는 list of arrays
- 플로팅할 데이터셋.
x와y가 없으면 이는 wide-form으로 해석됩니다. 그렇지 않으면 long-form으로 예상됩니다.
- 플로팅할 데이터셋.
- x, y, hue: 데이터 내 변수 이름 또는 벡터 데이터
- long-form 데이터 플로팅을 위한 입력값. 해석 예시는 아래 예시를 참고하세요.
- order, hue_order: 문자열 리스트
- 범주형 레벨을 플로팅할 순서; 그렇지 않으면 데이터 객체에서 레벨이 추론됩니다.
Countplot (분포를 나타내는 막대그래프)
범주형 변수의 분포 확인할때 유용한 그래프.
Matplot 사용
import numpy as np
import matplotlib.pyplot as plt
# 범주형 데이터 생성
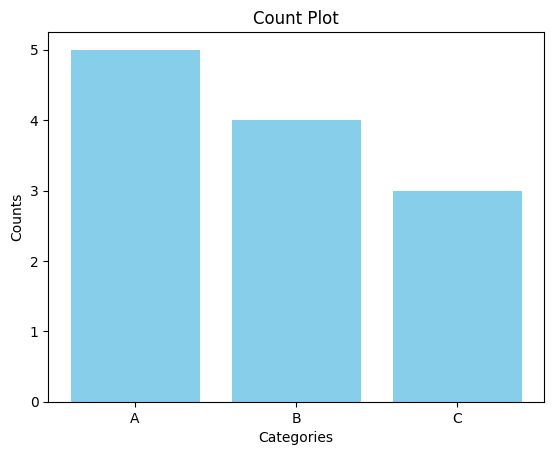
categories = ['A', 'B', 'C', 'A', 'B', 'A', 'C', 'A', 'A', 'B', 'C', 'B']
# 범주별 빈도 계산
unique_categories, category_counts = np.unique(categories, return_counts=True)
# 막대 그래프 그리기
plt.bar(unique_categories, category_counts, color='skyblue')
# 제목과 축 레이블 설정
plt.title('Count Plot')
plt.xlabel('Categories')
plt.ylabel('Counts')
# 그래프 표시
plt.show()
Seaborn 사용
import seaborn as sns
import matplotlib.pyplot as plt
# 범주형 데이터 생성
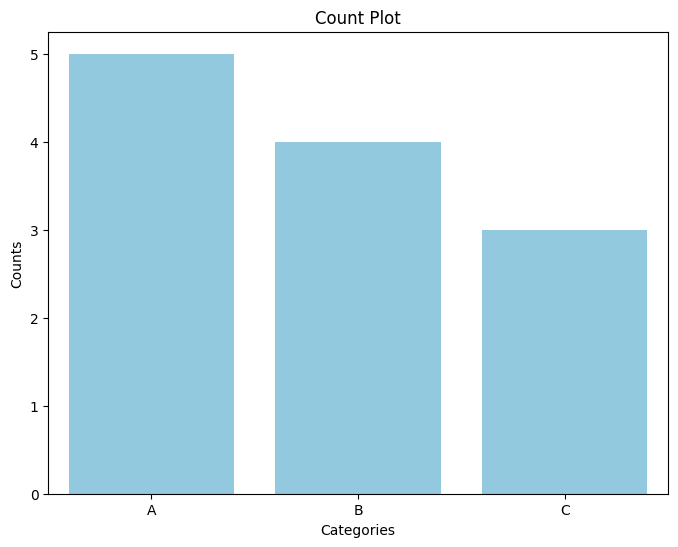
categories = ['A', 'B', 'C', 'A', 'B', 'A', 'C', 'A', 'A', 'B', 'C', 'B']
# Countplot 그리기
plt.figure(figsize=(8, 6))
sns.countplot(x=categories, palette=['skyblue'])
# 제목 설정
plt.title('Count Plot')
# 그래프 표시
plt.show()
선 그래프 (꺾은선 그래프)
시간의 흐름에 따른 데이터의 변화를 보여줄때 사용
Matplot 사용
# https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.plot.html
import matplotlib.pyplot as plt
# 데이터 설정
x = [0, 1, 2, 3, 4, 5]
y1 = [0, 1, 4, 9, 16, 25]
y2 = [0, 1, 8, 27, 64, 125]
# 그림 설정
plt.figure(figsize=(10, 6))
# 첫 번째 꺾은선 그래프 그리기
plt.plot(x, y1, marker='o', linestyle='-', color='b', label='y = x^2')
# 두 번째 꺾은선 그래프 그리기
plt.plot(x, y2, marker='s', linestyle='--', color='r', label='y = x^3')
# 제목과 축 레이블 설정
plt.title('Multiple Line Plot')
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
# 범례 추가
plt.legend()
# 그래프 표시
plt.show()
Seaborn 사용
# https://seaborn.pydata.org/generated/seaborn.lineplot.html
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
# 데이터 설정
x = [0, 1, 2, 3, 4, 5]
y1 = [0, 1, 4, 9, 16, 25]
y2 = [0, 1, 8, 27, 64, 125]
# 데이터를 long-form DataFrame으로 변환
data = pd.DataFrame({
'x': x + x, # x 데이터를 두 번 반복하여 long-form 형식으로 변환
'y': y1 + y2, # y1과 y2 데이터를 결합
'Function': ['y = x^2'] * len(x) + ['y = x^3'] * len(x) # 각 데이터에 라벨 추가
})
# 그림 설정
plt.figure(figsize=(10, 6))
# Seaborn을 사용한 꺾은선 그래프 그리기
sns.lineplot(data=data, x='x', y='y', hue='Function', style='Function', markers=['o', 's'], dashes=False, palette=['b', 'r'])
# 제목과 축 레이블 설정
plt.title('Multiple Line Plot')
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
# 그래프 표시
plt.show()
산점도(scatter)그래프
두 변수 간의 상관 관계를 확인 할때나, 회귀 모델의 유용성을 시각적으로 평가하고 예측의 정확도를 평가 할떄 사용되는 그래프다.
Matplot 사용
import matplotlib.pyplot as plt
# 데이터 설정
x = [1, 2, 3, 4, 5]
y = [2, 3, 5, 7, 11]
# 산점도 그래프 그리기
plt.figure(figsize=(8, 6)) # 그림의 크기 설정
plt.scatter(x, y, color='blue', marker='o', s=100) # 산점도 그래프 그리기
# 제목과 축 레이블 설정
plt.title('Sample Scatter Plot')
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
# 그래프 표시
plt.grid(True) # 그리드 표시
plt.show()
Seaborn 사용
import seaborn as sns
import matplotlib.pyplot as plt
# 데이터 설정
x = [1, 2, 3, 4, 5]
y = [2, 3, 5, 7, 11]
# 산점도 그래프 그리기
plt.figure(figsize=(8, 6)) # 그림의 크기 설정
sns.scatterplot(x=x, y=y, color='blue', marker='o', s=100) # 산점도 그래프 그리기
# 제목과 축 레이블 설정
plt.title('Sample Scatter Plot')
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
# 그래프 표시
plt.grid(True) # 그리드 표시
plt.show()
히스토그램 그래프
데이터 분포를 확인할때, 데이터의 추이나 패턴을 확인하여 특정 동향을 파악할때 주로 사용되는 그래프다.
Matplot
import matplotlib.pyplot as plt
# 데이터 설정
data = [1, 2, 2, 3, 3, 3, 4, 4, 5, 5, 5, 5, 6, 6, 6, 6, 6, 7, 7, 8]
# 히스토그램 그리기
plt.figure(figsize=(8, 6)) # 그림의 크기 설정
plt.hist(data, bins=8, color='skyblue', edgecolor='black') # 히스토그램 그리기
# 제목과 축 레이블 설정
plt.title('Histogram')
plt.xlabel('Value')
plt.ylabel('Frequency')
# 그래프 표시
plt.grid(True) # 그리드 표시
plt.show()
Seaborn
import seaborn as sns
import matplotlib.pyplot as plt
# 데이터 설정
data = [1, 2, 2, 3, 3, 3, 4, 4, 5, 5, 5, 5, 6, 6, 6, 6, 6, 7, 7, 8]
# 히스토그램 그리기
plt.figure(figsize=(8, 6)) # 그림의 크기 설정
sns.histplot(data, bins=8, color='skyblue', edgecolor='black') # 히스토그램 그리기
# 제목과 축 레이블 설정
plt.title('Histogram')
plt.xlabel('Value')
plt.ylabel('Frequency')
# 그래프 표시
plt.grid(True) # 그리드 표시
plt.show()
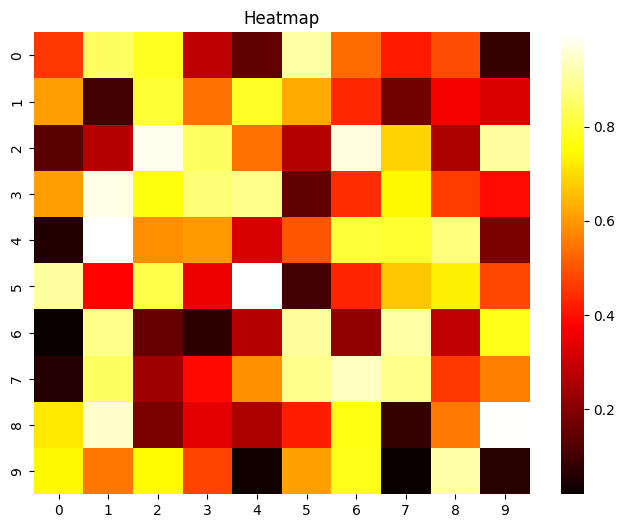
Heatmap
행렬 형태의 데이터의 상관관계를 파악 및 유사성을 확인하고 데이터를 그룹화하거나 분류하는 데 사용, 행렬 형태의 데이터를 보여줄 때 매우 유용한 그래프.
Matplot
import numpy as np
import matplotlib.pyplot as plt
# 데이터 생성
data = np.random.rand(10, 10)
# Heatmap 그리기
plt.figure(figsize=(8, 6))
plt.imshow(data, cmap='hot', interpolation='nearest')
# 컬러 바 추가
plt.colorbar()
# 제목 설정
plt.title('Heatmap')
# 그래프 표시
plt.show()
Seaborn
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# 데이터 생성
data = np.random.rand(10, 10)
# Heatmap 그리기
plt.figure(figsize=(8, 6))
sns.heatmap(data, cmap='hot')
# 제목 설정
plt.title('Heatmap')
# 그래프 표시
plt.show()