Linux 시스템 아키텍처
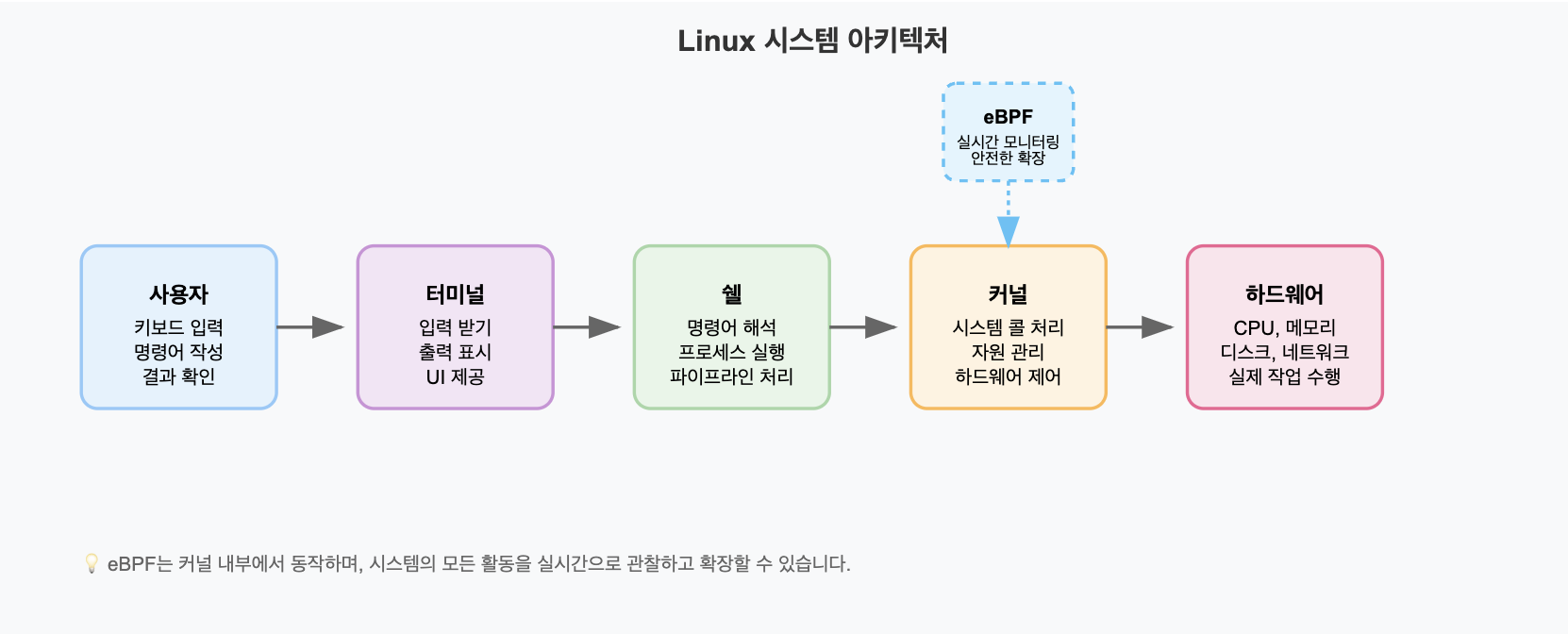
Linux의 커널은 컴퓨터를 부팅하면 하드웨어 메모리에 올라가서 끌때까지 메모리 위에서 동작한다.
따라서 응용 프로그램을 실행하면, 커널이 메모리에 충분한 공간이 있는지 없는지 모니터링하는 역할을 하게 된다.
기존 Linux 모니터링의 한계
제한적인 관찰 능력
- 정해진 형태의 정보만 제공: 커널이 미리 준비해둔 데이터만 확인 가능
- 낮은 실시간성: 주로 1초 단위로 업데이트되는 평균값만 제공
- 표면적인 정보: 시스템 내부에서 일어나는 세부적인 동작을 파악하기 어려움
커널 확장의 위험성
만약 커널 내부에서 일어나는 일들을 사용자가 원하는 방식으로 관찰하거나, 수정하기 위해서는 커널 모듈(kernel module) 을 작성해야했는데 이 방식은 위험하고 복잡한 작업이었다.
이 작업은 마치 집 구조를 바꾸려고 할때, 벽을 허무는 것과 같은 작업이다. 만일하나 실수를 하게되면 집 전체가 무너질 수 있는 위험도가 컸다.
eBPF: 안전한 커널 확장 기술
반면 eBPF는 Linux 커널의 한계를 확장시켜 사용할 수 있다.
기존의 커널을 사용하려면, 커널 모듈(kernel module)을 작성해야했다.
하지만, eBPF는 샌드박스 환경에서 안전하게 커널 레벨 코드를 실행할 수 있게 해준다.
또한, 커널이 기본적으로 제공하는 모니터링은 제한적이었으나, eBPF로는 네트워크 패킷 하나, 시스템 콜 호출, 파일 접근 등 실시간으로 세밀하게 관찰하고 분석할 수 있다.
eBPF의 핵심 장점
1. 안전한 실행 환경
- 샌드박스 보호: 격리된 환경에서 코드 실행
- 사전 검증: 코드 로딩 전 안전성 검사
- 메모리 보호: 허용된 메모리 영역만 접근 가능
- 무한루프 방지: 실행 시간 제한으로 시스템 보호
2. 동적 기능 추가
시스템 재부팅 없이 커널에 새로운 기능을 즉시 추가할 수 있다.
예시: 웹 서버 보안
상황: 웹 서버에 특정 IP의 요청만 차단하고 싶은 경우
- 기존 방식: 커널의 동작 방식을 바꾸거나 확장이 필요하기 때문에 수정 후 재부팅이 필요했고, 재부팅을 하지 않는다면 시스템 크래시가 발생할 위험이 있었다.
- eBPF 방식: 안전하면서 즉시 적용할 수 있게 되었고, 재부팅이 불필요해서 안전하게 새로운 기능을 추가할 수 있다
이는 수천 대의 서버를 관리하는 환경에서 특히 중요하다. 서비스 중단 없이 보안 정책이나 모니터링 규칙을 실시간으로 적용할 수 있기 때문이다.
모니터링 방식의 혁신적 변화
Linux
Linux 에서는 "이미 만들어진 음식을 받아먹는 것"으로 볼 수 있었다.
1초 단위로 업데이트되는 평균값들을 커널이 미리 준비해둔 정보만 볼 수 있었고, 정해진 형식으로만 데이터를 제공받을 수 있었다.
netstat -an | grep :80
# 결과: 현재 80포트 연결 상태의 스냅샷만 제공eBPF
eBPF에서는 "주방에 들어가 요리하는 과정을 직접 보는 것"으로 볼 수 있다.
커널 내부에서 일어나는 모든 일들을 "나노초 단위로 실시간으로 정밀하게 측정하여 관찰할 수 있다.
bpftrace -e 'kprobe:tcp_connect {
printf("%s PID:%d -> %s:%d (지연시간: %dus)\n",
comm, pid, ntop(arg1), arg2, elapsed/1000)
}'연결 시도 순간마다 실시간 추적이 가능하고, 어떤 프로그램이 어디에 얼마나 빨리 연결했는지 상세 정보를 확인 할 수 있다. 또한, 데이터 커스터마이징이 가능한 장점이 있다.
클라우드 환경에서 eBPF의 중요성
클라우드 네이티브 환경, 특히 Kubernetes와 같은 환경에서는 수천 개의 컨테이너가 복잡한 네트워크 환경에서 작동한다. 기존의 모니터링 도구로는 상세한 문제 추적이 어려워 eBPF 기반 도구가 점점 중요해지고 있다.
- 실시간 성능 모니터링: 컨테이너의 성능을 초정밀 실시간으로 측정 및 관리
- 네트워크 트래픽 분석: 상세한 패킷 수준의 실시간 트래픽 추적
- 보안 위협 탐지: 이상 행동과 잠재적인 보안 위협을 신속히 식별
- 서비스 메쉬 관찰성 향상: 컨테이너 간 통신 흐름과 장애를 실시간으로 명확히 추적하여 빠른 문제 해결 지원
서비스 메시와 eBPF 기반 도구들
서비스 메시(Service Mesh)
여러 서비스들이 서로 데이터를 주고 받을 때, 각 지점마다 전담 프록시를 두고, 중앙에서 모든 과정을 관리하는 시스템이라고 볼 수 있다.
왜 서비스 메시가 필요한가?
전통적인 방식 (모놀리식):
하나의 큰 애플리케이션
[사용자] → [하나의 큰 애플리케이션] → [데이터베이스]
- 쇼핑몰 전체가 하나의 프로그램
- 주문, 결제, 배송이 모두 한 덩어리 마이크로서비스 방식
[사용자] → [API Gateway]
↓
[주문서비스] ↔ [결제서비스] ↔ [재고서비스] ↔ [배송서비스]
↓ ↓ ↓ ↓
[주문DB] [결제DB] [재고DB] [배송DB]
마이크로서비스 방식의 경우, 서비스들 간의 통신이 복잡해졌다.
어떤 서비스가 어떤 서비스와 얼마나 많이 통신하는지 파악이 어려워, 네트워크 오류, 보안, 트래픽 제어 등을 각 서비스마다 따로 관리하는 문제가 있었다.
서비스메시의 역할
서비스메시는 이런 복잡한 통신을 투명하게 관리해주는 도구다.
서비스 메시가 없었을 때는 개발자가 직접 통신해야했다.
[주문서비스] --직접통신--> [결제서비스]
(개발자가 직접 재시도, 암호화, 모니터링 코드 작성)그러나 서비스 메시가 있을 경우, 중앙에서 모든 통신들을 관리하기
서비스 메시 있을 때:
[주문서비스] → [프록시] → [프록시] → [결제서비스]
↑ ↑
자동으로 재시도, 자동으로 암호화,
로드밸런싱, 모니터링
트래픽 분석메트릭(Metric)
메트릭 = 측정 가능한 숫자 데이터
서버 상태:
- CPU 사용률: 75%
- 메모리 사용량: 8GB / 16GB
- 디스크 사용률: 60%
- 네트워크 트래픽: 100Mbps메트릭 수집이 왜 중요한가?
메트릭 없이 서버 관리한다면 다음과 같은 상황 발생
상황: 쇼핑몰 웹사이트가 갑자기 느려짐
개발자: "어? 왜 느리지?"
방법: 서버에 직접 접속해서 하나씩 확인
- htop 실행해서 CPU 확인
- free 명령어로 메모리 확인
- df 명령어로 디스크 확인
- 로그 파일 하나씩 뒤져보기
문제: 이미 문제가 생긴 후에야 알 수 있음메트릭을 수집하면 문제를 즉시 발견하고 원인을 파악하기 용이하다.
상황: 쇼핑몰 웹사이트가 갑자기 느려짐
모니터링 대시보드에서 즉시 확인:
- CPU: 95% (빨간불) ← 문제 발견!
- 메모리: 90% (주황불)
- 응답시간: 5초 (빨간불)
- 에러율: 10% (빨간불)
결과: 문제를 즉시 발견하고 원인도 바로 파악eBPF로 메트릭 수집 방법
기존 방식 vs eBPF 방식
기존 방식
외부에서 관찰
모니터링 프로그램이 1초마다:
cat /proc/cpuinfo # CPU 정보 읽기
cat /proc/meminfo # 메모리 정보 읽기
netstat -an # 네트워크 연결 정보 읽기문제점:
- 1초 단위로만 확인 가능
- 평균값만 알 수 있음
- 세세한 내부 동작은 모름
eBPF 방식
내부에서 실시간으로 관찰
커널 내부에 eBPF 프로그램을 심어두고:
- 함수가 호출될 때마다 측정
- 네트워크 패킷이 올 때마다 기록
- 파일이 읽힐 때마다 시간 측정결과:
- 나노초 단위 정밀 측정
- 실시간 데이터
- 세세한 내부 동작까지 파악
eBPF 메트릭 수집 장점
1. 정확성
기존: "평균적으로 응답시간이 2초"
eBPF: "95%는 100ms, 4%는 500ms, 1%는 10초"→ 1%의 매우 느린 요청이 문제라는 걸 정확히 파악할 수 있다.
2. 실시간성
기존: 1분 후에 "아, 1분 전에 문제가 있었음"
eBPF: "지금 이 순간 문제 발생!!!"3. 세밀함
기존: "네트워크가 느림"
eBPF: "TCP 연결 설정은 빠른데, 데이터 전송에서 지연이 생김.
특히 192.168.1.100 서버와 통신할 때만 느림" 정리
메트릭 수집 = 컴퓨터의 상태를 숫자로 측정해서 기록하는 것
eBPF로 메트릭 수집 = 커널 내부에서 실시간으로 정확하게 측정하여 더 빠르고 정확한 문제 발견할 수 있고, 세밀한 성능 분석과 자동화된 대응을 가능하게 한다.
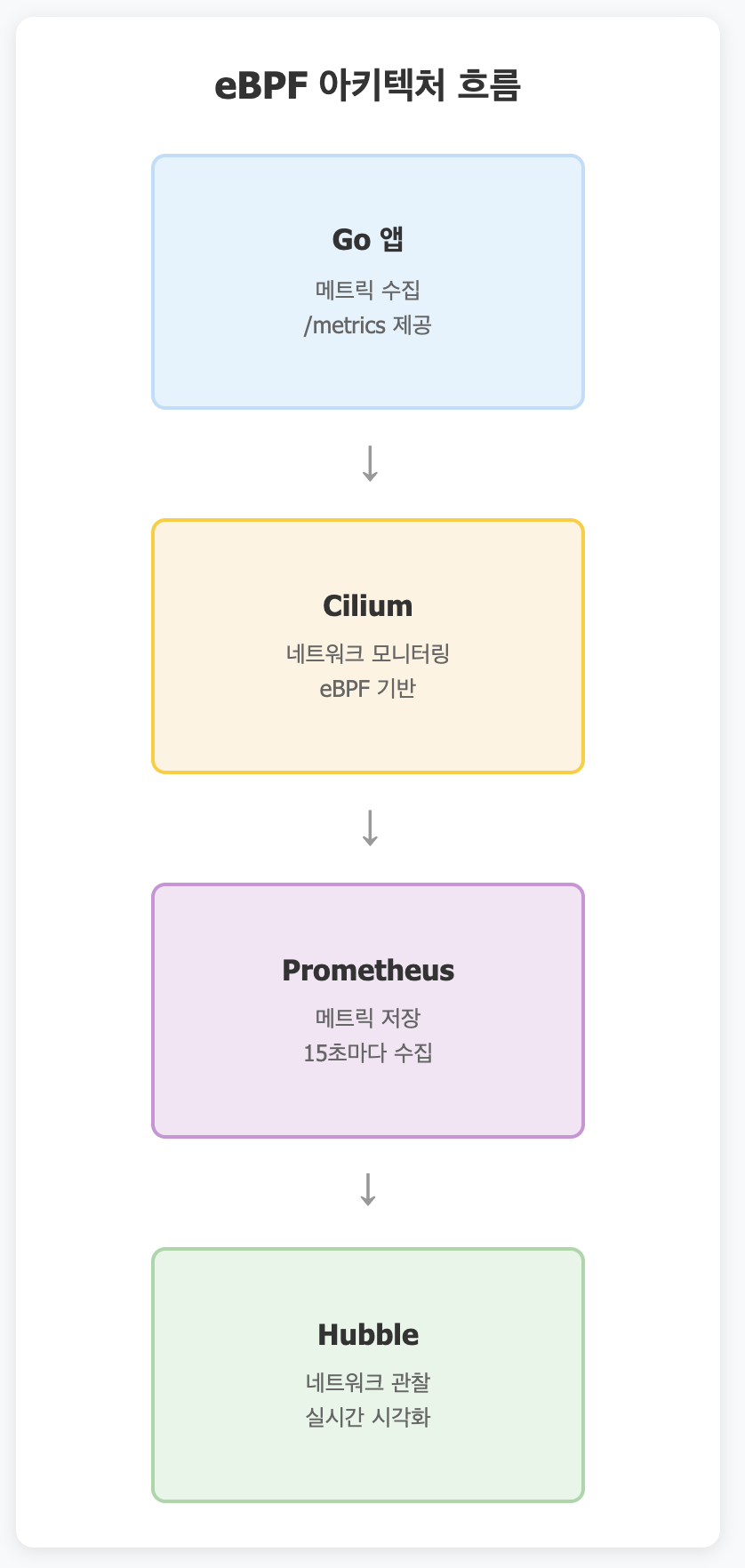
Cilium, Hubble, Prometheus
eBPF가 내장됨. (즉, Cilium과 Hubble을 설치하면 자동으로 eBPF가 사용됨)
직접 eBPF로 개발을 한다는 것은 '자동차 엔진을 직접 만드는 것'과 같다.
C언어로 직접 eBPF 프로그램을 작성해야하고, 커널에 직접 로드해야한다.
데이터 수집 로직도 구현해야하기 때문에 매우 복잡하고 어렵다.
그러나, Cilium과 Hubble을 사용하면 이미 eBPF가 내장되어있어 '완성된 자동차'를 구매하는 것 과같다.
Cilium과 Hubble은 설치만하면 바로 사용 가능하기 때문에 복잡한 개발 과정이 불필요하다.
Cilium
네트워킹 + 보안

Cilium은 eBPF기반 쿠버네티스 네트워킹 솔루션이다.
Cilium 설치 시
# Cilium 설치
helm install cilium cilium/cilium --namespace kube-systemCilium 설치시 커널에 자동으로 로드되는 eBPF 프로그램들:
Cilium이 설치되면 자동으로 eBPF 프로그램들이 커널에 로드되고, 아래와 같은 기능들을 사용할 수 있게 된다.
- 네트워크 패킷 필터링
- TCP/UDP 연결 추적
- HTTP 요청/응답 분석
- 보안 정책 적용
- 메트릭 수집
- 로드밸런싱
# 설치만
kubectl apply -f cilium.yaml# cilium-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: cilium-config
data:
# eBPF로 네트워크 정책 적용
enable-policy: "true"
# eBPF로 로드밸런싱
enable-l7-proxy: "true"
# 실시간 모니터링 활성화
enable-hubble: "true"위의 Yaml을 등록하면, Cilium은 알아서 수십 개의 eBPF 프로그램을 커널에 로드하게 된다.
그렇게되면 실시간으로 네트워크 모니터링을 시작하게 되고, 메트릭 수집을 자동으로 시작한다.
Cilium이 하는 일:
- Pod 간 네트워크 통신 관리
- 보안 정책 적용 (어떤 Pod끼리 통신 가능한지)
- 로드밸런싱
- 네트워크 메트릭 수집
Hubble
관찰! 위의 Cilium을 관찰하는 도구임.
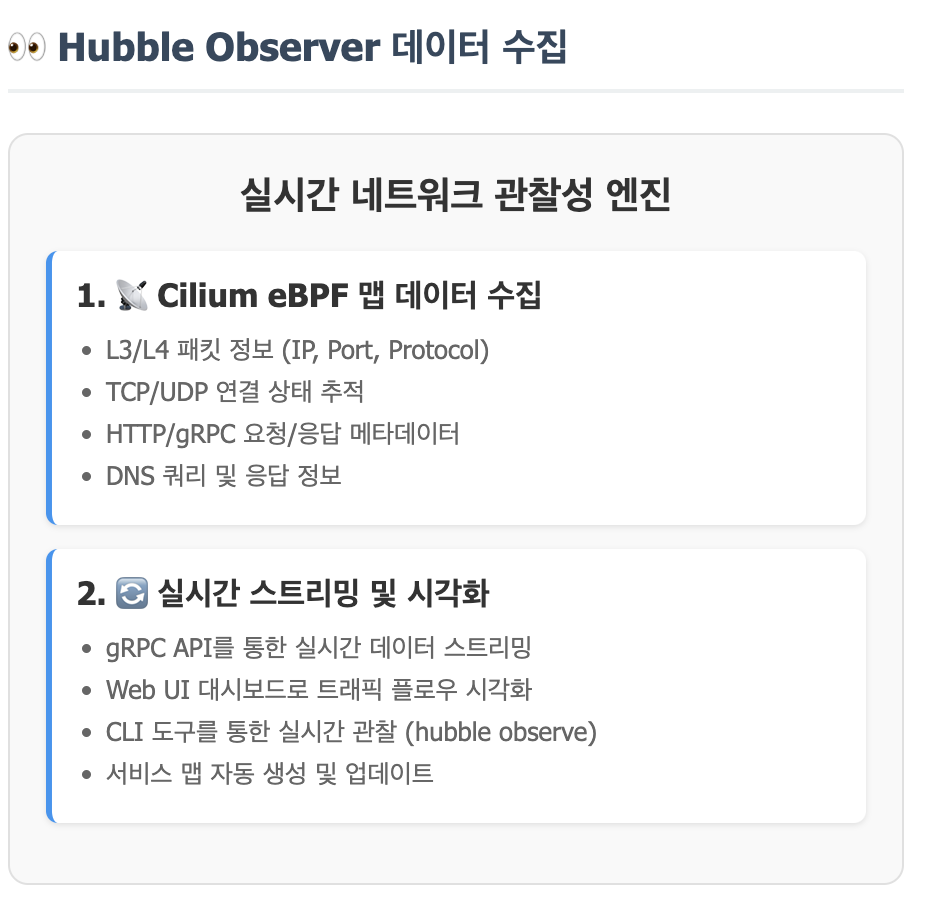
# Hubble로 실시간 네트워크 트래픽 관찰
hubble observe
# 출력 예시:
# Oct 20 12:34:56.789: frontend-pod -> backend-pod:8080 (HTTP GET /api/users)
# Oct 20 12:34:56.792: backend-pod -> db-pod:3306 (TCP)
# Oct 20 12:34:56.845: db-pod -> backend-pod:3306 (TCP)
# Oct 20 12:34:56.850: backend-pod -> frontend-pod:8080 (HTTP 200 OK)-> 로그 보니까 Skuber에서 log에 보이는 로그들과 비슷한 것 같음. (확인 필요)
네트워크 정책 적용
# network-policy.yaml
apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
metadata:
name: "allow-frontend-to-backend"
spec:
endpointSelector:
matchLabels:
app: frontend
egress:
- toEndpoints:
- matchLabels:
app: backend
toPorts:
- ports:
- port: "8080"
protocol: TCP
# 적용하면 eBPF가 자동으로 패킷 필터링 시작
kubectl apply -f network-policy.yamlHubble이 수집하는 메트릭
# 서비스별 트래픽 통계
hubble metrics list
# - dns_queries_total
# - drop_count_total
# - tcp_flags_total
# - http_requests_total백그라운드에서 일어나는 일
- kubectl apply 명령 실행
- Cilium이 정책을 읽음
- eBPF 프로그램을 자동으로 생성/업데이트
- 커널에서 즉시 패킷 필터링 시작
- 정책 위반 패킷은 자동으로 차단
Prometheus
메트릭 저장소로 메트릭을 수집하고 저장하는 데이터베이스.
# prometheus-config.yaml
global:
scrape_interval: 15s
scrape_configs:
# Hubble에서 메트릭 수집
- job_name: 'hubble'
static_configs:
- targets: ['hubble:9090']
# 내 Go 애플리케이션에서 메트릭 수집
- job_name: 'my-go-app'
static_configs:
- targets: ['my-app:8080']
Go 예시
package main
import (
"encoding/json"
"fmt"
"log"
"net/http"
"time"
"github.com/gorilla/mux"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
// 상품 구조체
type Product struct {
ID int `json:"id"`
Name string `json:"name"`
Price int `json:"price"`
}
// Prometheus 메트릭 정의
var (
httpRequestsTotal = prometheus.NewCounterVec(
prometheus.CounterOpts{
Name: "http_requests_total",
Help: "총 HTTP 요청 수",
},
[]string{"method", "endpoint", "status_code"},
)
httpDuration = prometheus.NewHistogramVec(
prometheus.HistogramOpts{
Name: "http_duration_seconds",
Help: "HTTP 요청 처리 시간",
Buckets: prometheus.DefBuckets,
},
[]string{"method", "endpoint"},
)
databaseConnections = prometheus.NewGauge(
prometheus.GaugeOpts{
Name: "database_connections_active",
Help: "활성 데이터베이스 연결 수",
},
)
)수정중..,

우와.. 가독성이 좋습니다