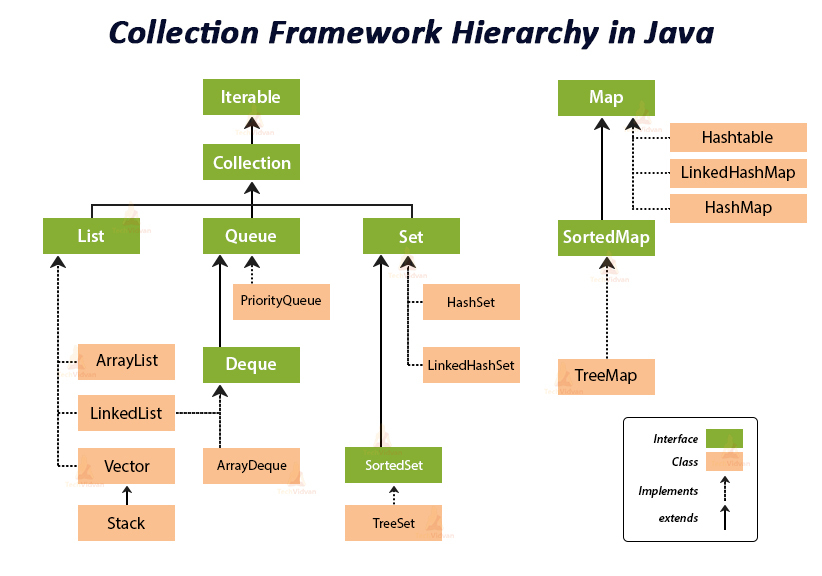
(출처: https://memostack.tistory.com/234)
List와 Set과 달리 HashMap은 Collection 인터페이스가 아닌 Map을 구현한 클래스이다.
HashMap은 키-밸류 페어로 값을 저장하며 저장할 때와 값을 꺼내올 때의 시간복잡도는 O(1)이다. List에서 특정 값을 찾기 위한 시간복잡도가 O(n)이므로(인덱스 사용 안할시) List보다 성능이 좋다고 할 수 있다(물론 모든 경우에 그런건 아니다).
데이터 추가 메커니즘
해시맵에 데이터를 저장하려면 put() 메서드를 사용한다.
public class MyKey {
private int id;
@Override
public int hashCode() {
return id;
}
// constructor, setters and getters
}public void testHashMapPutMethod() {
MyKey key = new MyKey(1);
Map<MyKey, String> map = new HashMap<>();
map.put(key, "val");
}단순히 put() 메서드를 사용하여 값을 저장하면 되는 걸로 보이지만 뒤에서는 여러 작업들이 일어난다.
먼저 맵에 값이 추가될 때 키 오브젝트의 해시코드 메서드를 호출하여 초기 해시값을 얻어낸다. 그 다음 HashMap의 hash() 메서드가 내부적으로 호출되고 초기 해시값을 사용하여 최종적인 해시값을 계산해낸다. 이 최종 해시값에 해당하는 버킷에 데이터 "val"을 저장하게 된다.
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}hash() 메서드는 위와 같다. 최종 해시값을 계산하기 위해 키 객체의 hashcode() 메서드를 호출하는 것을 볼 수 있다.
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}put() 메서드는 위와 같다. 최종 해시값은 보다시피 첫 번째 파라미터로 들어가게 된다.
그리고 두 번째 파라미터에 키가 들어가는 것을 볼 수 있다. 이유는 HashMap은 버킷에 Map.Entry 객체로
키와 밸류 둘 다 저장하기 때문이다.
이 글의 첫 부분에 HashMap은 Collection 인터페이스를 구현하지 않는다고 했는데 바로 이러한 이유 때문이다. 즉 맵은 싱글 엘레먼츠를 저장하는 것이 아닌 키-밸류 페어로 저장하기 때문에 Collection 인터페이스의 기본 메서드인 add나 toArray 같은 메서드들을 맵에 사용할 수 없다. 그러므로 Map이라는 별도의 인터페이스를 따로 구현하게 된다.
HashMap은 또한 Null 키와 Null 밸류가 허용된다.
Null을 키 값으로 해서 put() 메서드를 호출한다면 자동으로 최종 해시값을 0으로 할당한다. 즉 키가 Null일 때는 hashcode() 메서드가 호출되지 않으며 NullPointerException 예외 역시 발생하지 않는다.
HashMap의 Collection Views
HashMap은 세 가지 뷰를 제공한다.
Set<String> keys = map.keySet(); -> 키 값 컬렉션 뷰를 제공
Collection<String> values = map.values(); -> 밸류 컬렉션 뷰를 제공
Set<Entry<String, String>> entries = map.entrySet(); -> 모든 엔트리 뷰 집합을 제공
참고로 HashMap은 정렬되어 있지 않으므로 루프를 돌 때 특정 순서대로 출력되지는 않는다.
대부분의 경우 컬렉션 뷰를 아래와 같이 iterator()와 함께 사용할 것이다.
public void givenIterator_whenFailsFastOnModification_thenCorrect() {
Map<String, String> map = new HashMap<>();
map.put("name", "breathe");
map.put("type", "blog");
Set<String> keys = map.keySet();
Iterator<String> it = keys.iterator();
map.remove("type"); // iterator가 생성된 뒤 맵의 데이터를 삭제하고 있다.
while (it.hasNext()) {
String key = it.next();
}
}iterator는 fail-fast이다. 즉 iterator가 생성된 뒤에 맵에 구조적인 변경이 발생하게 되면 concurrent modification exception이 발생한다.
위의 코드에서도 iterator 생성 뒤에 맵에 변경을 주고 있기 때문에 예외가 발생한다.
오직 이터레이터 자체의 remove 작업만 구조적인 변경을 허용한다.
public void givenIterator_whenRemoveWorks_thenCorrect() {
Map<String, String> map = new HashMap<>();
map.put("name", "breathe");
map.put("type", "blog");
Set<String> keys = map.keySet();
Iterator<String> it = keys.iterator();
while (it.hasNext()) {
it.next();
it.remove();
}
assertEquals(0, map.size());
}HashMap의 성능
HashMap 성능은 loadfactor와 용량에 의해 결정된다.
HashMap 용량이 꽉 차면 rehashing이 발생되는데, 이는 기존 배열의 약 2배 크기의 또다른 내부 배열이 생성되고 모든 Entry가 새로운 배열의 새로운 버킷으로 재분배되는 작업을 말한다.
'용량이 꽉 찼다'의 기준은 loadfactor로 결정한다. (데이터의 개수)/(저장공간) 으로 계산하며 디폴트 loadfactor는 75%이다.
낮은 초기 용량은 메모리 상에서 많은 공간을 차지하지 않아도 되기에 상대적으로 (공간)비용이 적게 드나 rehashing이 빈번히 일어날 수 있다. 굳이 말할 필요도 없이 이 rehashing은 굉장히 비용이 많이 드는 작업이다.
즉 낮은 초기 용량은 적은 엔트리 + 많은 iteration이 필요한 경우에 유리하다. 반대로 높은 초기 용량은 많은 수의 엔트리와 적은 iteration에 유리하다.
해시 충돌
해시 충돌은 두 개 이상의 키가 동일한 최종 해시값을 갖게 될 때 일어난다. 즉 동일한 해시값을 가지므로 버킷에 밸류를 저장할 때 충돌이 난다.
이는 hashcode() 메서드가 반드시 유니크한 해시값을 계산해내지는 않기 때문이며 그로 인해 자바에서는 두 개의 유니크한 객체가 충분히 같은 해시값을 가질 수 있다.
또한 기본 배열의 제한된 사이즈로 인해 발생할 수도 있다. 즉 배열이 작을수록(용량이 적을수록) 충돌 가능성이 높아진다.
객체가 저장될 버킷을 결정하는 것은 키의 해시값이다. 따라서 두 키의 해시값이 중복되더라도 해당 값은 여전히 동일한 버킷에 저장된다. 이러할 경우 자바에서는 디폴트로 LinkedList를 이용해 값을 저장하게 된다.
충돌이 일어난 경우에는 기존 put, get 작업에 대한 기존 시간복잡도 O(1)은 O(n)까지도 늘어날 수 있다.
최종 해시값이 있는 버킷 위치를 찾은 후 이 위치에 있는 값들을 equals()를 사용하여 일일이 순회하며 비교하는 작업이 추가되기 때문이다.
자바8부터는 하나의 버킷에 저장되어 있는 데이터 수가 특정 임계치를 넘어서면(데이터 수 8개) LinkedList가 아닌 균형 이진트리를 사용하여 데이터를 저장하게 된다. 이 경우 시간복잡도는 O(log n)까지 낮아진다.
