
1. Conventional vs Direct
이는 우리가 앞에서 자주 다루었던 내용과 같다.
Conventional path 는 서버 프로세스가 버퍼 캐시에서 데이터를 가져와 CRUD 작업을 하는 것을 말하며 이는 index를 경유한 Access 즉 Random Access 라고 말한다.
만일 index를 타려고 했으나 해당 데이터가 메모리에 올라와 있지 않다면 Storage에 접근하고 메모리에 해당 데이터를 올리고 데이터를 가져오는 작업을 하게 된다.
Direct Path 는 말 그대로 서버 프로세스가 직접 Storage에 Read/Write 작업을 하는 것을 말한다. 버퍼캐시에서 Free 인 빈 공간을 찾아서 넣는 노력을 하지 않고 DML 작업시 하이워터 마크 공간에 바로 집어 넣어 속도가 빠르다. 추후 Hint편에서 /+append */ 에서 Direct Path를 사용한다.
2. SQL 의 이해
우리가 작성한 SQL문을 오라클은 어떻게 실행하려는 걸까?
우선적으로 SQL문을 받게 되면 Oracle 내부에서 상세 실행 계획으로 변경하는 작업을 진행한다.
예를 들어 어떤 테이블을 먼저 가져올 것인가? 어떤 테이블을 드라이빙 테이블로 할 것인가?
인덱스를 사용할 것인지 풀스캔을 할 것인지 같은 것이 한 예이다.
취지는 좋으나 만일 OLTP 서비스에서 수십개의 SQL이 동시에 들어오는 작업에서는 그때마다 실행계획을 세우는 것은 서비스 속도에 영향을 미칠 것이다. 따라서 library cache 에 저장하는 작업 및 옵티마이저의 실행계획에 대해 알아보자
알짜배기 개념
쿼리문을 받았을 때 다중 컴마 (,,) 테이블 이름이 틀렸을 경우 Syntax Error , 바인드 변수로 Int가 와야 할 부분이 String 으로 오는 경우 Sementic Error 가 발생하며 이런 오류를 잡기 위해 아래 와 같은 순서로 쿼리를 검사한다.
1. FROM 테이블명
2. WHERE 조건식
3. GROUP BY 칼럼(Column)이나 표현식
4. HAVING 그룹조건식
5. SELECT 컬럼명 [ALIAS명]
6. ORDER BY 컬럼
따라서 Group by 와 having 절에는 SELECT부분을 읽기 전이라 Alias를 사용할 수 없다.
2-1. 옵티마이저 실행계획 수행 절차 및 library cache
우선 호출된 sql 은 데이터 딕셔너리를 참고하여 파싱하고 데이터의 분포도나 저장구조 , 인덱스 구조를 통해서 각 실행계획의 비용을 계산하게 된다.
앞에서 말한 파싱, 쿼리변환 실행계획을 생성하는 것을 Hard Parsing 이라고 하며 생성된 실행계획을 library Cache에 보관한다.
만일 이전에 작성한 SQL의 실행계획이 library Cache에 있어 그대로 사용하는 것을 Soft Parsing 이라고 한다.
옵티마이저는 SELECT * FROM CUSTOMER WHERE CUST_ID = ? 라는 쿼리가 있을 때 custId 값이 변동됨에 따라서 다른 쿼리로 인식하여 library Cache 안에 있는 실행계획을 사용 하지 못하게 된다.
따라서 OLTP에서 사용되는 SQL은 Bind 변수를 사용하여 같은 SQL로 인식하게 하는 것이 중요하며 JDBC에서는 PreparedStatement 객체를 사용하여 구현한다.
또한 오라클에서 아래와 같은 명령어를 통해 유사한 쿼리를 같은 쿼리로 인식하게 만들 수 있다.
ATER SYSTEM SET CURSOR_SHARING = 'FORCE';
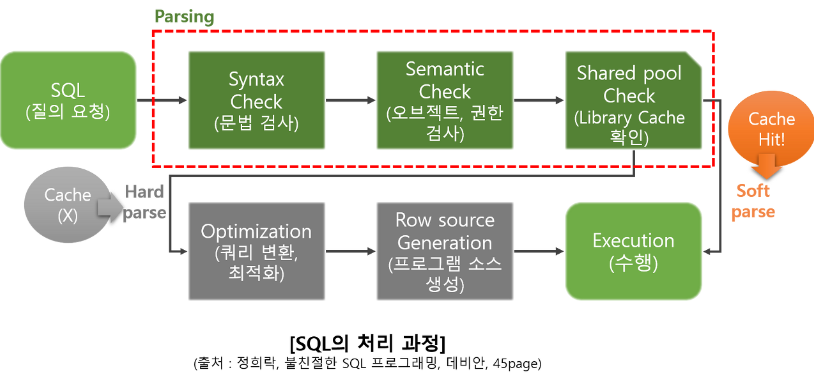
마지막으로 Shared Pool 에 대해 요약하며 마무리하고자 한다.
Shared Pool 안에는 Library Cache , Data Dictionary Cache , Result Cache로 이루어져 있다.
Library Cache : 사용된 SQL 및 실행계획이 파싱되어 보관되어 있다.
Data Dictionary Cache : 테이블/ 인덱스에 대한 object 정의 및 접근 기능 권한이 있는지 확인
Result Cache : 사용자 SQL의 결과값을 지속적으로 보관하여 동일한 SQL이 요청되었을 경우 Access 작업을 하지 않고 Result Cache 값을 반환
3. 오라클의 메모리 크기 자동 관리 기법
SGA 의 DB_CACHE_SIZE , SHARED_POOL 의 크기를 동적으로 변경을 통하여 나은 환경을 만들 수 있다.
ASMM(Automatic Shared Memory Management) 의 약자로 SGA Component 크기를 동적으로 변경하는 것이며
AMM(Automatic Memory Management) 는 SGA 뿐 만 아니라 PGA 메모리 크기도 동적으로 변경 가능하다.
3-1. 오라클의 SGA 다루기
SGA_MAX_SIZE 는 SGA의 최대 메모리 크기이며 재할당 시 인스턴스를 재 가동해야 하며 SGA_TARGET 은 SGA 사이즈 안에서 변경 가능한 SGA의 크기를 말하며 MAX_SIZE 보다 작아야 하며 운영 중에도 변경 가능하다.
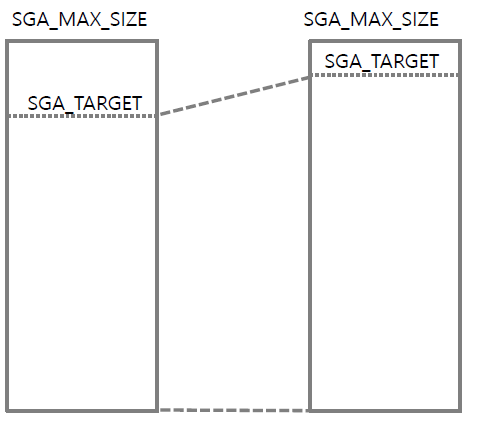
이 외에도 오라클의 메모리를 더 효율적으로 관리하기 위해 가상메모리를 사용하는데 이 때 메모리에 남은 용량보다 프로세스가 더 크게 된다면 남는 공간을 활용하지 못하는 메모리 내부 단편화를 막기 위해 Paging 기법을 사용한다.
리눅스에서는 기본 page 크기는 4kb이며 이런 page를 관리하기 위한 pageTable이 존재한다.
이때 4kb 수많은 페이지가 존재한다면 그만큼 Table이 비대해지고 이를 방지하기 위해 Huge Page 기법이 도입되었다. 4kb 크기를 2M로 늘려 page Table의 용량을 줄이기 위해서다.
3-2. 오라클의 PGA 다루기
PGA는 각 서버 프로세스 개별적으로 할당되는 메모리를 말한다.

SQL Work Area 는 말 그대로 sql을 실행함에 따라서 필요한 공간을 말한다. Sort Area 는 정렬시 필요한 공간을 말하며 Hash Area는 NL 조인을 사용하지 못하는 경우 Hash 조인을 할 때에 정렬 시 필요한 공간을 말한다.
따라서 모든 정렬 및 Hashging을 메모리에서 할 수 있도록 pga 영역을 잡아주는 것이 중요하다.
만약 정렬 해야 할 데이터가 Work Area 보다 작다면 Temporary db에 확장여 정렬하게 되고 기존 pga 를 사용하는 것보다는 느리다.
SGA 와 마찬가지로 PGA의 메모리를 지정할 수 있는데 pga가 최대로 사용할 수 있는 공간을
PGA_MAX_SIZE 라고 하며 사용하고 있고 있는 메모리를 PGA_AGGREGATE_TARGET 이라고 한다.
3-3. Cursor의 이해
Cursor는 우리 주변에서도 쉽게 접할 수 있는 용어이다. 하지만 자세히 알지는 못했는데 이는 클라이언트 프로세스가 서버의 데이터를 가져오기 위해 PGA의 Private SQL area를 가르키고 있는 Pointer 이다.
클라이언트가 데이터를 조회를 하였을때 조회 건이 천건 이고 50건씩 보내준다고 가정하였을 때 위의 사진에서 Private SQL Area에 나머지 데이터를 저장해두고 이 후에 클라이언트가 50건 이후의 데이터를 요청하였다면 buffer Pool에 접근하는 것이 아닌 SQL area에서 데이터를 가져와 빠르게 사용자에게 데이터를 넘겨 줄 수 있다.

이는 자바에서의 ResultSet와 같다.
4. Datafile I/O
오라클에는 Datafile IO 이외에도 Buffer Cache , Redo Logging IO 처럼 다양한 IO가 있으며 해당하는 wait도 수천개가 존재한다. 그중에서 Datafile의 IO를 다뤄보고자 한다.
4-1 db file sequential read
해당하는 IO는 인덱스를 경유하여 Random access를 할 때 주로 발생한다. 대량의 OLTP에서 발생하며 Single block Storage IO를 수행할 때 발생한다.
사실 Sequential 하게 읽기 때문에 테이블을 Full Scan 할 때 발생하는 줄 알았다.
하지만 sequential 은 buffer Cache에 해당 데이터가 나란히 있는 것을 말한다.
Full Scan했을 때 데이터들이buffer Cache에 나란히 못올리는 이유가 해당 데이터를 올리기 위에 기존에 있던 Cache들을 옮기는 것 자체가 손해이며 그만큼의 여유공간이 남기 쉽지 않다
또 한 Aging 하는 것도 Full Scan으로 올라오는 데이터들이어서Scattered하게 올라가 있다. index를 탄 데이터들은 Full Scan보다 적은 데이터를 가져오게 되어 나란히 올릴 수 있다.
4-2 db file scatterd read
Multi block Storage IO를 수행할 때 발생한다. 주로 테이블을 Full Scan 시에 발생한다.
원래 알고 있는 내용으로는 테이블을 Full Scan 시에 무조건 발생하는 IO인줄 알았으나 작은 테이블에 한에서만 buffer Cache에 올려두어 발생하는 IO이며 일정 용량의 테이블을 full scan시에는 direct path R/W 를 발생하며 buffer Cache에는 올리지 않는다.
4-3 direct path read, write temp
서버 프로세스가 Buffer Cache를 거치지 않고 바로 Storage에 direct R/W IO를 수행 시에 발생하며 Parallel Query 를 사용할 때 주로 발생한다.
오라클 성능 분석과 인스턴스 튜닝 핵심 가이드
처음에는 회사에서 오라클을 사용해서 어떻게 하면 쿼리를 효율적으로 작성할 수 있을까? 에 대해 강의를 찾아보던 중 듣게 된 강의였다.
사실 이 강의는 쿼리를 짜는 법 보다는 오라클 내부에서 어떻게 작동하는지에 대해 배우고 DBA가 알고있어야 할 오라클의 심화 내용을 담고 있다.
비록 쿼리를 작성하는데 도움을 받지는 못했지만 어떻게 하면 더 좋은 서비스를 제공할 수 있는지에 대해 알 수 있었다. 운영체제 혹은 데이터베이스를 학부생으로 먼저 배우고 추가적으로 학습하기 좋은 내용이다.
따라서 다양한 WAIT EVENT (CACHE BUFFER CAHINS 혹은 LUR CHAINS , BUFFER BUSY WAIT)를 배우고 $변수를 활용한 오라클 분석, 오라클의 성능개선을 배우고 싶은 사람에게 적극 추천한다.
