현재 항공회사에서 재구축 프로젝트를 진행하면서 처음으로 postgresql을 사용하면서 다른 분들도 알면 좋은 점에 대해서 정리 하려고 한다.
해당 aurora 버전은 Amazon Aurora for PostgreSQL 15.x 을 사용하고 있다.
그래서 aurora를 왜 사용해요?
먼저 Aurora는 aws에서 mysql, postgresql 과 호환되는 RDMS 인데 기존의 RDS mysql, postgresql 의 차이점은 저장하는 방식 즉 스토리지와 read replica, 관리주체 로 3가지 정도가 다르다.
관리주체는 rds mysql 은 관리자가 rds mysql, postgresql 의 버전을 올리면서 사용하지만 오로라는 aws 가 버전 업그레이드를 주기적으로 진행하기 때문에 관리주체가 다르다고 볼 수 있다.
저장 방식은 오로라는 shared storage를 사용하며 mysql 의 경우 binlog 기반의 replication 이 아닌 storage와 page 기반의 replication 을 사용하며 이는 read replica 에서 넘겨주는 bandwidth 를 줄이기 위함이다.
아래의 사진에서 보이는 것과 같이 rds의 경우 ebs에 저장하고 미러링 하는 반면에 오로라는 데이터 4/6은 storage에 저장하고 나머지 2 / 6 redo 로그의 내용만 replica에 공유한다.
이 처럼 오로라에서는 성능 최적화에 힘 썻다는 것을 알 수 있으며 rds에서 최소 3배 최대 5배 정도의 성능 차이가 난다고 한다.
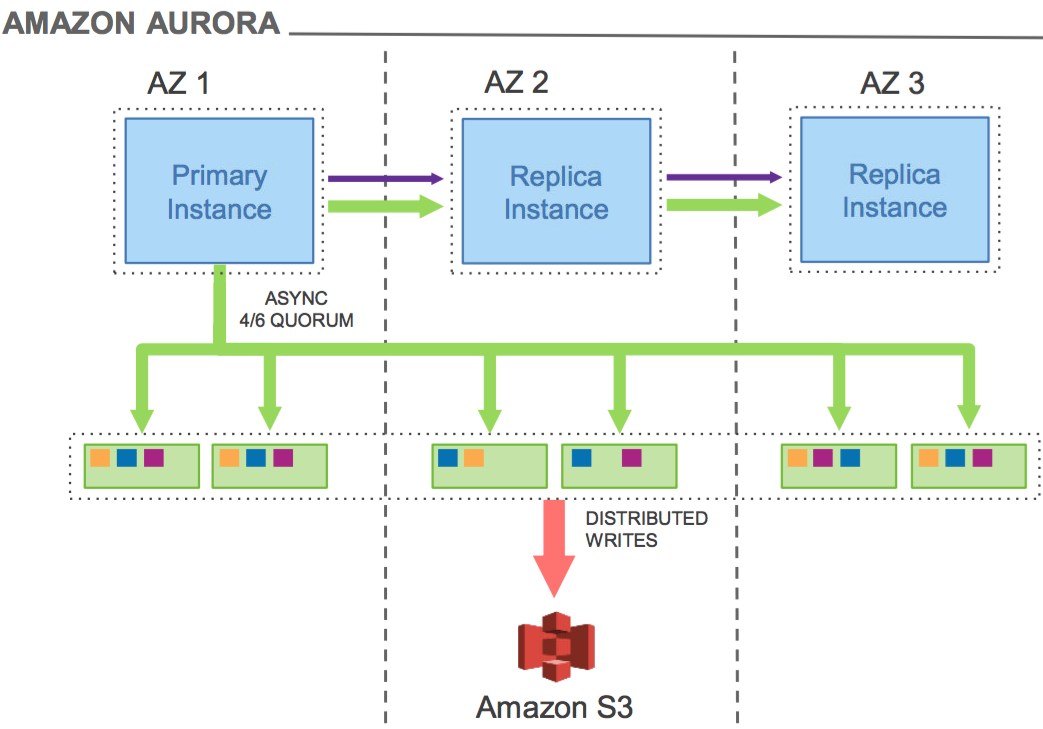
aurora mysql vs postgresql
처음에 프로젝트를 투입해서 가장 먼저 든 생각이다. RDBS에서 제일 많이 사용하는 oracle이 있고 비용문제가 크다면 주로 mysql를 사용했기 때문이다. 따라서 한글로 되어 있는 글을 찾아보니 우테코(https://techblog.woowahan.com/6550/) 에서 작성한 글이 있어 parllel 기능과 복잡한 join 기능 제공, 속도 측면에서 AURORA POSTGRESQL 을 사용하였고 한다.
하지만 해당 글은 3년전 글이기도 하고 현재 MYSQL 에서 많은 패치가 이루어진 8.0이 aurora에서 제공하기 때문에 큰 성능 차이를 확인 할 수 없었다.
따라서 개인적인 생각으로는 postgresql은 15년도 부터 JSON 저장 기능을 제공하며 심지어 NOSQL 처럼 인덱스 기능을 제공하고 있으며 현재 full text search 를 하는 것이 아닌 엘라스틱 검색 엔진을 제공하는 횡보를 보여주고 있기 때문이다.
따라서 필자라면 최신기술에 관심이 많고 진보적인 횡보를 많이 보여주고 있는 postgresql 을 사용하지 않을까 싶다.
해당 부분은 참고 에서 확인 할 수 있다.
Oracle vs Postgresql
개인적으로 oracle 과 가장 큰 차이는 MVCC 모델과 shared Pool 의 존재 여부의 차이라고 생각한다. 오라클은 undo 세그 먼트를 통해서 mvcc 를 구현하였지만 postgresql 에는 블록 내에 이전 레코드를 저장하는 방식을 사용한다.
동시성을 높이기 위해서 읽기 작업은 쓰기 작업을 블로킹 하지 않고 쓰기 작업은 읽기 작업을 블로킹 하지 않기 위해 mvcc 를 사용하는데 이 때 undo 로그를 사용한다. 하지만 postgresql 은 마킹하는 프로세스를 걸치는 작업을 진행한다.
오라클에서는 shared Pool 을 통해서 1회 hard pasring 을 진행하고 soft poarsing 의 비율을 높여 성능을 높이는 반면에 postgresql 은 버퍼캐시를 통해서 읽은 데이터 페이지를 저장하고 개별적으로 파싱하고 실행 계획을 연결마다 파싱하지만 공유하지 않는 방법을 통해서 오래된 계획으로 인한 문제를 방지함과 동시에 wal 버퍼, 운영체제 버퍼를 통해서 성능을 높이는데 힘을 썻다.
MYSQL BIN BINARY 방식
위에서 복제하는 방식에서 성능 포퍼먼스를 높이기 위한 노력을 확인할 수 있다. mysql 에서도 bin 복제 방식 이외에 성능 최적화를 위한 statement 복제 방식, GTID 복제 방식 등 여러가지 복제 방식을 보여줬는데
mysql 에서 default transaction는 repeatable read 방식이지만 해당 기법은 데드락을 발생 시킬 수 있으며 속도 측면에서 저하 우려가 있어 대부분 프로젝트에서는 read-commited 방식을 사용하고 있다.
read-committed, binlog = statement 인 경우에 non-repeactable-read가 발생하여 원자성이 안 지켜지는 경우가 있어 master-slave구조를 이룰 수 없기 때문이다. 따라서 bin log 복제를 사용한다.
MYSQL MVCC vs MGA
앞 서 Undo segment 방식은 update 된 최신 데이터는 기존 데이터 블록의 레코드에 반영하고 변경 전 값을 undo 영역이라는 별도의 공간에 저장하여 갱신에 대한 버전관리를 하는 방식이다.
MySQL은 InnoDB 스토리지 엔진에서 각각 row의 데이터에 대한 버전 정보를 저장하고 이전 버전의 데이터는 변경되지 않고 유지되는 방식이다.
MGA(Multi Generation Architecture) 방식은 튜플을 update할 때 새로운 값으로 replace 처리하는 것이 아니라, 새로운 튜플을 추가하고 이전 튜플은 유효 범위를 마킹하여 처리하는 방식이다.
이처럼 같은 RDMS 임에도 서로 다르게 동시성을 보장하기 위해 여러 가지 노력을 한다는 것을 알 수 있다.
Cluster Endpint
Amazon Aurora는 고가용성과 성능을 위해서 여러 인스턴스로 구성되고 있는데 이는 Oracle에서 RAC 구조와의 차이점이다.
또 한 Aurora 는 고가용성은 자동 장애 조치, 다중 가용 영역 배포, 지속적인 백업 기능을 제공하고 있으며 프로젝트를 진행하면서 해당 고가용성을 사용하고 있는지 DR 테스트를 진행하면서 spring application.yml 올바르게 작성하는 방법에 대해서 설명하고자 한다.
Aurora는 에는 endopint가 4가지가 존재하는데 End Point는 Client 가 Database로 접근하기 위한 host 정보를 말하며 여기서는 2개의 endpoint에 대해서 설명하고자 한다.
Cluster EndPoint(Writer Endpoint) : Writer Endpoint 라는 이름으로 등장했지만 현재는 cluster endpoint로 많이 유명하다.
aurora 는 single writer cluster 이기 때문에 Writer instance 만 접근 되는 endpoint를 말한다.
Reader Endpoint 는 말 그대로 Aurora Read Replica 들을 그룹화한 endpoint 를 말하며 round-lobin 방식으로 connection을 획득한다.
여기까지만 확인하면 스프링 application.yml 파일을 아래와 같이 작성할 수 있다.
datasource:
tempdb:
master:
jdbc-url: jdbc:postgresql://my-dlwre-aws.rds.amazonaws.com:5957/cnsdb
username: lgcns_app
hikari:
driver-class-name: org.postgresql.Driver
maximum-pool-size: 5
minimum-idle: 5
idle-timeout: 0
max-life-time: 0
connection-timeout: 10000
data-source-properties:
preparedStatementCacheQueries: 1000
preparedStatementCacheSizeMiB: 250
reader:
jdbc-url: jdbc:postgresql://my-dlw32q2re-aws.rds.amazonaws.com:5957/cnsdb
username: lgcns_app
hikari:
driver-class-name: org.postgresql.Driver
maximum-pool-size: 5
minimum-idle: 5
idle-timeout: 0
max-life-time: 0
connection-timeout: 10000
data-source-properties:
preparedStatementCacheQueries: 1000
preparedStatementCacheSizeMiB: 250reader, writer에 기본적으로 작성해야할 기본 특성값들을 적어주고 jdbc-url 에는 aurora cluster endpoint를 작성해 주었다.

하지만 각자 역할에 맞는 DB를 연결하고 DR 테스트를 진행해 본 결과
writer DB가 다운되고 나서 reader DB가 승격되었지만 문제는 yml 파일에 writer로 저장되어있는 writer endpoint만을 바라보고 있어 장애가 발생하였다.
따라서 fast failover 를 하기 위해 하나의 endpoint만을 작성하는 것이 아닌 여러개의 endpoint를 작성하였고 아래에서 보이것과 같이 2개의 endpoint를 작성하고
targetServerType을 지정해주어 어떤 connection 을 얻을지 지정, preferSecondary 옵션을 통해서 가급적 reader 로 연결하나 연결이 끊길시에 writer endpoint 에서 connection 을 얻도록 작성하였다.
datasource:
tempdb:
master:
jdbc-url: jdbc:postgresql://temp.com:5957,rds-temp.temp.com:5957/temp?targetServerType=primary
username: temp
hikari:
driver-class-name: org.postgresql.Driver
maximum-pool-size: 5
minimum-idle: 5
idle-timeout: 0
max-life-time: 0
connection-timeout: 10000
data-source-properties:
preparedStatementCacheQueries: 1000
preparedStatementCacheSizeMiB: 250
reader:
jdbc-url: jdbc:postgresql://rds-oc-prd.temp.com:5957,rds-temp-ro.temp.com:5957/temp?targetServerType=preferSecondary&loadBalanceHosts=true
username: temp
hikari:
driver-class-name: org.postgresql.Driver
maximum-pool-size: 5
minimum-idle: 5
idle-timeout: 0
max-life-time: 0
connection-timeout: 10000
data-source-properties:
preparedStatementCacheQueries: 1000
preparedStatementCacheSizeMiB: 250SE 관점에서 알면 좋은 것들
사실 SE 입장에서는 postgresql의 아키텍쳐나 성능 보다는 구현에 신경쓰이기 마련이다. 그래서 SE가 구현하면서 알았으면 하는 점에 대해 작성하려고 한다.
1) https://explain.dalibo.com/
개인적으로 정말 좋아하는 사이트이다. 어떤 프로젝트를 들어가냐에 따라서 DBA 나 튜너가 있을 수 있는데 항공사에서는 소규모로 일하다 보니 개인적으로 해결해야 하는 부분이 많았다. explain 명령어를 통해서 실행 계획을 볼 수 있지만 너무 긴 글로 인한 가독성이 떨어져 애먹는 시간이 많았다.
아래의 사진은 실제로 사용하고 있던 쿼리 실행계획을 넣은 부분이며 컬럼이나 테이블에 대해서는 가렸으며 사진과 같이 비용을 많이 차지하는 조인에 대해서 알기 쉽게 보여준다. 왼쪽 아래에서 볼 수 있듯이 sequential scan(full scan) 의 경우 비용이 높아 $ 기호가 붙은 것을 볼 수 있다.
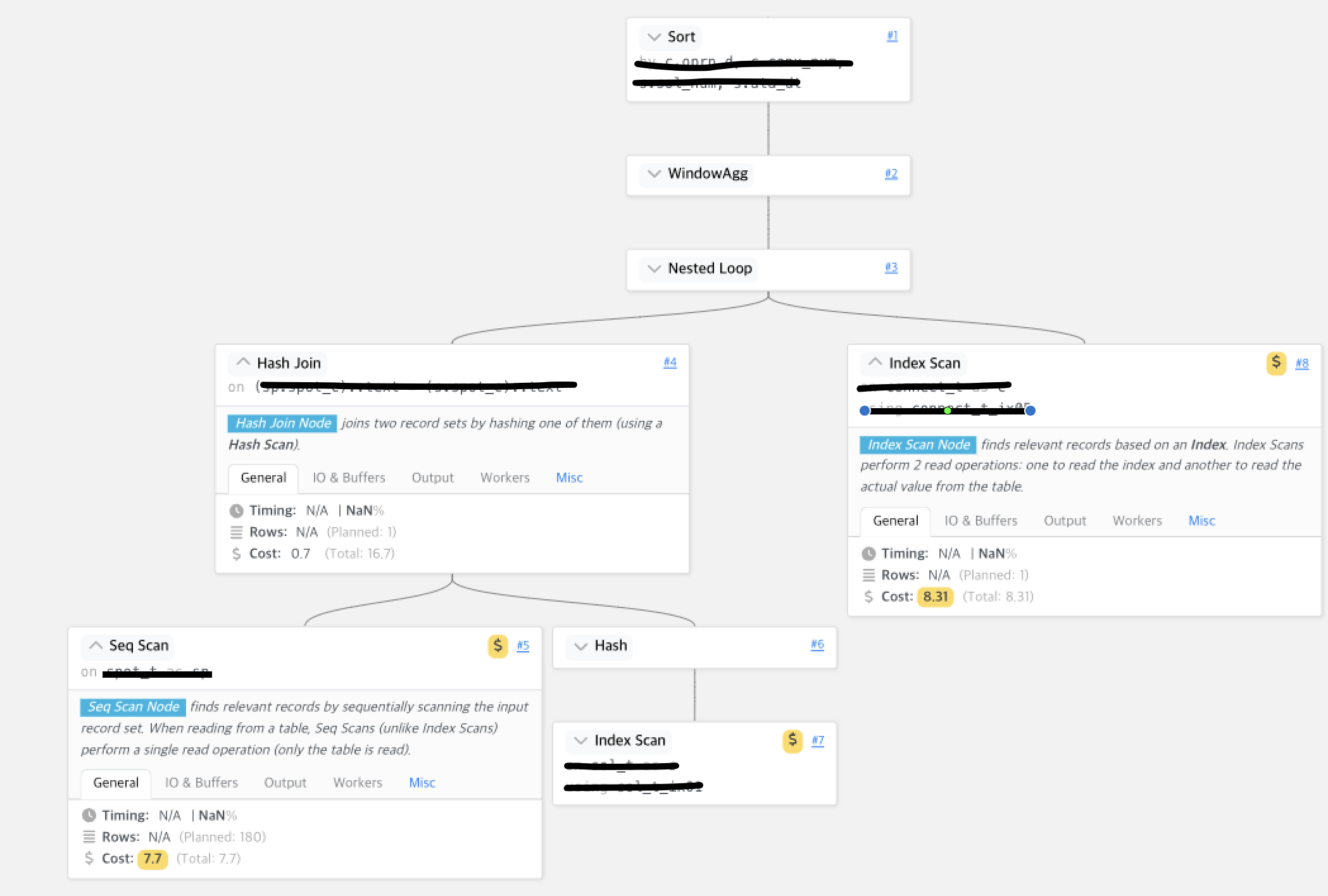
해당 사이트를 통해서 not exist 문을 left outter join 과 조인 키가 null인 조건을 통해서 10초 걸리는 쿼리를 2초로 변경 할 수 있었으며 인덱스를 탈 줄 알았던 쿼리가 정상적으로 타지 않아 복합 인덱스를 수정하여 15초 걸리는 쿼리를 3초로 변경 할 수 있었다.
2)postgreSQL 은 default commit 이 true 이다.
처음 프로젝트를 투입하고 나서 개발 가이드를 읽어 보는데 dbeaver의 autocommit을 true 로 놓고 개발하라는 문구를 보고 바로 의문을 가졌다.
개발자도 사람이기에 실수로 commit을 하게 되어 운영 데이터를 날릴 수 있지 않나? 따라서 autocommit = false 는 당연한 것이 아닌가?
하지만 postgreSQL 의 default autocommit 은 true 이기 때문에 dbeaver에서 false로 변경해도 dml 를 사용하면 바로 적용이 되고 commit을 하게 되면 0건 업데이트가 된다.
이는 autocommit이 off이더라도 PostgreSQL의 기본 동작은 여전히 SQL 명령어가 하나의 트랜잭션으로 실행되게끔 동작하지 때문이다. 그렇기 때문에 각 SQL 문(statement)은 자동으로 커밋된다.
만일 false 인 것처럼 작동하기 위해서는 쿼리를 실행하기 전에 begin; 문을 통해서 명시적 트랜잭션을 시작해주어야 한다.
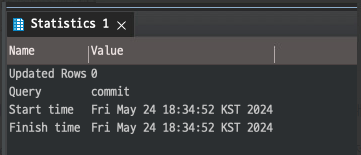
3)returning 구문
spring에서 dml 을 사용하고 나서 변경된 부분에 대해서 정보를 얻고 싶은 경우가 있다. dto를 해당 업데이트 값으로 사용자가 직접 업데이트 하여 사용하거나 select 하는 동일한 로직을 실행하여 값을 얻어 올 수 있지만
postgresql 에서 아래와 같은 returning 구문을 통해서 변경, 삽입 된 데이터에 대한 정보를 별도의 쿼리 없이 얻을 수 있다.
INSERT INTO users (name, email)
VALUES ('John Doe', 'john.doe@example.com')
RETURNING id;4) 자잘한 상식
partitional index
oracle 에서는 index 와 실제 data를 세그먼트 형식으로 나누어서 저장하며 모든 데이터에 대해서 저장하게 된다. 하지만 postgresql 에서는 데이터들 중에 일부를 partitional index 를 적용할 수 있도록 기능을 제공한다.
date 문
특이하게 oracle에서는 Date 자료형은 날짜와 시간을 저장하나 postgresql 에서는 날짜만 저장한다. 따라서 postgresql 에서는 날짜 및 시간을 저장하기 위해서는 timestamp 를 사용하며 oracle 에서는 분 보다 더 세밀한 초가 필요할 때 timestamp 자료형을 사용한다.
null index
oracle 에서는 인덱스 컬럼에 is null, is not null 비교시에는 인덱스를 타지 않고 풀스캔을 하게 되는데 postgresql 에서는 인덱스를 탈 수 있다. (이는 mysql, mariadb에서도 동일하다.)
결론
지금까지 프로젝트를 아직 3군대를 다녔지만 DB를 oracle, mysql, postgresql 을 사용해서 각 db의 장점에 대해서 항상 생각했는데 특정 db가 좋다라기 보다는 각 업무, 비용에 따른 적절한 db를 선택하는 것이 현명하다고 생각한다.
취업 준비생들이 mysql8.0 동물책으로 공부를 많이 하는데 postgresql 은 별도로 유명한 책이 없어서 접근하기가 어려웠다. BitMap index Scan 이나 Vacumn에 대해서 더 공부하고 싶다면 postgresql 9.6 성능 이야기 라는 책을 추천한다.
