
JAVA8
제일 많이 사랑 받던 버전이기도 하고 현재는 11버전을 주로 사용하고 있는데 각 버전에서 어떤 부분때문에 사랑 받았고 11버전에는 어떤 부분이 추가되었는지 알아보자.
Functional Interface
함수형 인터페이스는 추상 메서드가 오직 하나인 인터페이스를 의미한다.
추상 메서드가 하나라는 뜻은 default method 또는 static method 는 여러 개 존재해도 상관 없다
default method와static method는 OCP 원칙을 지키는 것이 일방적이나 현업을 진행함에 따라서 원칙을 지키지 못하는 경우가 많다.
만일 해당 interface에 method를 추가하게 되는 경우 해당 인터페이스를 상속하는 클래스 메소드를 추가해야 하기 떄문에 편의성을 위해 제공하고 있다.
@FunctionalInterface 어노테이션을 사용하는데 어노테이션을 사용하지 않아도 되지만 컴파일 전에 Method가 하나 인지를 파악하기에 사용한다.
자바에서 기본적으로 제공하는 여러개의 SAM이 있지만 그중에서 Stream에서 주로 사용하는 2개의 SAM 에 대해서 알아보고자 한다.
Predicate
@FunctionalInterface
public interface Predicate<T> {
boolean test(T t);
}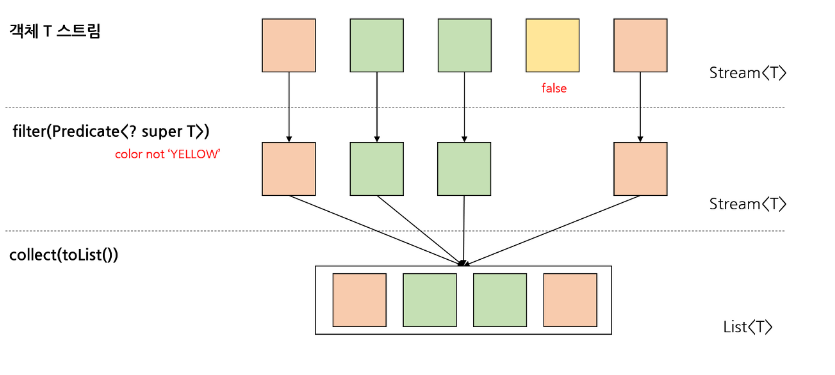
Predicate는 전달받은 T값으로 boolean값을 반환하는 SAM이며 Stream에서 filter에서 매개변수 요청 값이이며 아래와 같이 람다로 표현할 수 있다.
List<String> names = Arrays.asList("James","Alex")
List<String> result = names.strea()
.filter(name -> name.startWith("A")
.collect(Collectors.toList())Consumer
@FunctionalInterface
public interface Consumer<T> {
void accept(T t);
}Consumer는 전달받은 T값을 넘겨받은 파라미터를 수행하고 아무것도 반환하지 않는 SAM이며 Stream에서 foreach()의 파라미터 값으로 넘겨주게 된다.
List<String> names = Arrays.asList("James","Alex")
List<String> result = names.stream()
.foreach(System.out::println)
Optional 과 Stream
Stream은 별도로 다룰 정도로 자주 사용하여서 이곳 에서 참고 할 수 있다.
Stream을 사용한 것과 iterator를 사용하는 것 차이에 대해 의문을 가질 수 있다.
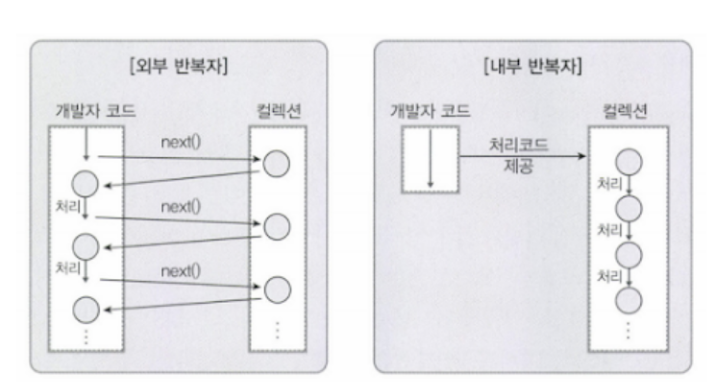
위의 사진 처럼 iterator는 외부 반복자로 개발자가 next()를 사용할때마다 컬렉션에서 값을 찾는 과정이 포함되어 있는 반면에 Stream은 컬렉션에게 처리과정을 맡김으로서 시간을 절약할 수 있다.
개발을 할 때 개발자를 괴롭히는 문제중 하나가 NPE(NullPointerException) 이다. 각 API혹은 Method마다 반환값이 null값인지 확인하는 것 또한 코드가 복잡하게만 느껴진다. 따라서 null값 처리에 대해서 코드 가용성 및 가독성을 좋게 해주는 것이 Optional이다.
public final class Optional<T> {
// If non-null, the value; if null, indicates no value is present
private final T value;
...
}
Optional<String> optional = Optional.empty();
위으 코드는 Optional의 선언부이며 아래의 코드를 통해서 Optional를 생성할 수 있다.
List<String> names = getNames();
List<String> tempNames = list != null
? list
: new ArrayList<>();
// Java8 이후
List<String> nameList = Optional.ofNullable(getNames())
.orElseGet(() -> new ArrayList<>());if 절이나 삼항 연산자를 피할수 있으며 Optional Method 파라미터값이 Fucntional Interface 중에서 Consumer 인 부분이 많아 메소드 래퍼런스를 사용하기에도 용이하다.
실제 개발하면서 반환값을 Optional를 사용한 적은 없었다. 기본적으로 DAO로 통신을 하는 경우에 List값이 null이기 보다는 안에 값이 비워져 있는 List이고 안의 컬럼값을 가져오려고 하면 null이 나는 경우만 있었고
아래와 같이 filter로직을 사용할때 Optional을 사용하였다.
Optional<String> anyElement = elements.stream()
.filter(s -> s.startsWith("b")).findAny();Method Reference
처음에 Android로 앱을 만들 때 메소드 래퍼런스를 통해서 간략하게 나타내느 것과 :: 기호를 처음 본 것에 대해 신언어 답다고 생각하였다.
자바8에서 메소드 래퍼런스를 동일하게 제공한다. (코틀린은 더 나아가 Function Reference 를 제공한다.)
Consumer<String> func = System.out::println;
func.accept("Hello");위와 같이 객체를 생성하지 않고 참조 하는 것을 static method Reference라고 하며 객체를 생성하고 메소드 참조 또 한 할 수 있다.
DateTimeFormatter 이해
취준을 준비할 때 대답을 하지 못해 아쉬운이 남는 질문이 있었다.
Q : 앞에서 Thread-safe를 말씀하셨는데 스프링에서 Thread-safe는 어떤 것을 의미하나요?
A : 하나의 요청이 왔을 때 하나의 쓰레드를 생성하여 응답을 생성하기 때문에 스프링에서 일반적으로 Thread-safe 합니다.
Q : ...
스프링에서 대해서 공부한지 얼마 되지 않아 내 자신도 햇갈리는 답변을 한 것이다.
이에 따라서 스프링에 각 요청에 따라 스레드를 생성하는데 어떤 문제가 발생하는 것일까?
해당 문제가 발생하는 SimpleDateFormat에 대해 알아보자.
public SimpleDateFormat(String pattern, DateFormatSymbols formatSymbols) {
...
if (pattern != null && formatSymbols != null) {
...
this.locale = Locale.getDefault(Category.FORMAT);
this.initializeCalendar(this.locale);
...
}
private void initializeCalendar(Locale loc) {
if (this.calendar == null) {
assert loc != null;
this.calendar = Calendar.getInstance(loc);
}
}
위의 코드는 문제가 발생하는 코드의 일부분이다. Calender 인스턴스를 싱글톤으로 생성하여 Date에 대한 정보를 가져올 때 별도의 Thread라고 할 지라도 도중에 Calender 객체에 add, clear 를 하게 된다면 다른 Thread에서 문제가 발생한다.
이 처럼 Thread-safe 하지 않다라면 내부에 singleton 으로 내부 값을 가지고 있는지 확인하면 좋을 것 같다.
추가적으로 해당 API는 Date임에도 시간까지 다루어 경계가 모호하였다. 따라서 자바8 에서는 이를 해결하기 위해 DateTimeFormatter 를 제공하며 레거시 코드와 호환된다.
DateTimeFormatter formatter =
DateTimeFormatter.ofPattern("MM/d/yyyy");
LocalDate date = LocalDate.parse("07/15/1982", formatter);
System.out.println(date);
System.out.println(today.format(formatter));
Completable Future
먼저 Completable Future 를 사용하기 전에 Thread와 Runnable에 대해서 알아보자.
Thread와 Runnable
Thread는 사용자가 직접적으로 Runnable 인터페이스를 구현하고 있으며 저수준으로 사용자가 Thread를 생성하고 시작할 수 있다. 따라서 Thread를 상속해서 커스텀 Thread를 생성해도 되지만 Runnable를 구현하여 상속에서 좀 더 자유롭게 구현 할 수 있다.
하지만 값의 반환이 불가능 하며 매번 쓰레드 생성 및 종료라는 오버헤드가 발생하며 쓰레드의 관리가 어렵다는 단점이 있다.
Callable, Future
기존에 Runnable 인터페이스는 결과를 반환 할 수 없는 한계점으로 인해 Java 5에서 Callable 이 추가되었다.
@FunctionalInterface
public interface Callable<V> {
V call() throws Exception;
}Callable 인터페이스의 구현체임 Task는 가용가능한 쓰레드가 없어서 실행이 미뤄질 수 있다. 따라서 바로 결과를 받지 못하고 미래에 어느 시점에 얻을 수 있는데 미래의 값을 받기 위한 것이 Future이다.
Future
멀티 쓰레드 작업시에 ExecutorService에서 작업 결과를 받거나 기다리기 위해 Future 클래스의 future.get()을 사용하게 된다. 하지만 이는 비동기적으로 API를 호출하고 bloking 하는 형태이다.
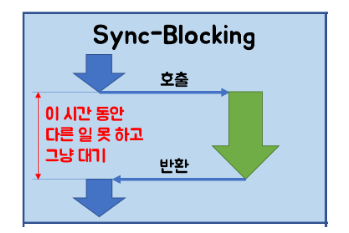
ExecutorService란?
먼저 Executor는 위에서 알아본 단점 중에서 쓰레드를 그때마다 생성하고 종료하는 불필요한 오버헤드를 줄이기 위해 쓰레드 풀의 구현을 위한 인터페이스 이며 오로지 실행하는 역할만을 가지고 있다. ExecutorService는 Bloking Queue에 Task를 담아두고 Thread Pool에 할당하는 방식으로 구현되어 있다.
따라서 bloking을 하지 않고 다른 일을 진행하다가 callback을 실행하기 위해서 Listenable Future 를 사용한다.
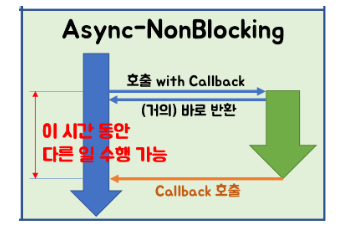
하지만 callback 패턴을 사용함에 따라서 callback hell을 겪을 수 있다.
Listenable Future 은 다음에 실행해야 될 Future에 대해서 addCallback 메소드를 작성하게 된다.
ListenableFuture<IntStream> future1 = todo(executor);
future1.addCallback(s -> {
log.info("todo 1 success");
ListenableFuture<IntStream> future2 = todo2(executor, s);
future2.addCallback(s2 -> {
log.info("todo 2 success");
ListenableFuture<List<String>> future3 = todo3(executor, s2);
log.info("todo 3 success");
future3.addCallback(s3 -> {
log.info("Finished: {}", s3);
}, e -> log.error(e.getMessage()));
}, e -> log.error(e.getMessage()));
}, e -> log.error(e.getMessage()));따라서 callback Hell 을 해결하기 위함과 편리기능이 추가된 completable Future 기능이 나오게 되었다.
CompletableFuture
.supplyAsync(() -> todo, executor)
.thenApply(s -> todo(s))
.thenApply(s -> todo2(s).collect(Collectors.toList()))
.thenAccept(s -> log.info("Finished: {}", s));runAsync : 반환값이 없는 경우
supplyAsync : 반환값이 있는 경우
thenApply : 받을 인자가 있고 반환할 게 있는 경우 (중간 연산자)
thenAccept : 받을 인자는 있고 반환할 게 없는 경우 (최종 연산자)
이 외에도 작업조합 및 에러처리 같은 부가기능을 제공한다.
추가적으로 timeout시간 내에 exception 이 발생하도록 구현 할 수 있다.
thenCompose :두 작업이 이어서 실행하도록 조합하며, 앞선 작업의 결과를 받아서 사용할 수 있으며 함수형 인터페이스 Function을 파라미터로 받음
thenCombine :두 작업을 독립적으로 실행하고, 둘 다 완료되었을 때 콜백을 실행하며 함수형 인터페이스 Function을 파라미터로 받음
allOf :여러 작업들을 동시에 실행하고, 모든 작업 결과에 콜백을 실행함
anyOf : 여러 작업들 중에서 가장 빨리 끝난 하나의 결과에 콜백을 실행함
exeptionally : 발생한 에러를 받아서 에러 처리
handle : 별도의 handler 작성하여 에러처리
다음은 stackoverflow 에 간단한 Task를 진행하려고 하는데 ForkjoinPool을 사용하는 것과 Completable Future 차이에 대해서 물어본 질의이다.
(Completable Future는 기본적으로 ForkjoinPool을 사용한다.)
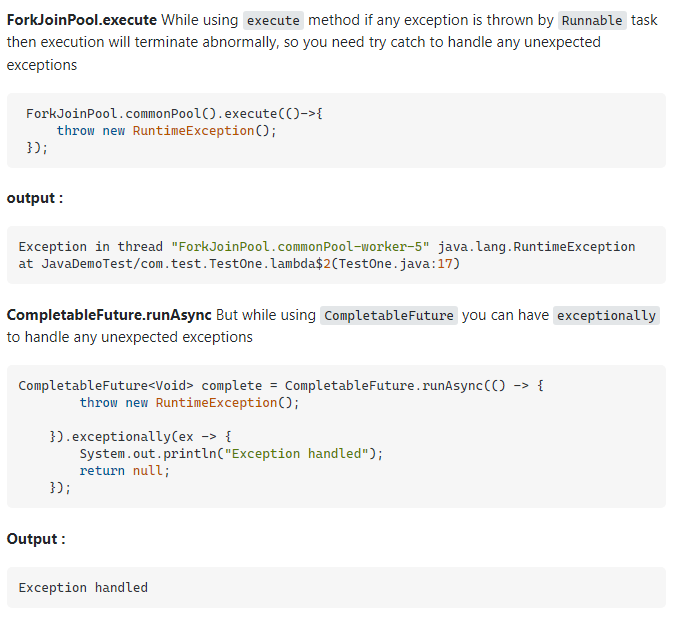
Stream 병렬작업 과 Completable Future
멀티 쓰레드를 활용해서 최적의 자원을 사용하여 최대한 빠른 속도로 데이터를 전달하고 할 때 Stream 병렬작업을 사용해야 할지 completable Future를 이용하는 것중에 어떤 것을 사용하면 좋을까?
우선 stream 병렬 작업은 데이터의 작업내에서 쪼개어 서브 데이터들을 만들고 해당 병령 처리를 통해서 작업을 완수하는 방법을 사용한다. 이때 기본적으로 forkjoin Pool을 사용하며 만일 쿼드 쿼어인 경우에는 4개의 서브 요소들로 나누고 4개의 쓰레드가 가각의 서브 요소들을 병렬 처리하는 방법이다.
Completable Future는 ExecutorService 를 커스텀하여 해당 Future Function을 커스텀 할 수 있는 이점이 크다. 아래 코드는 Stream, Completable Future 비교 코드이며 여기서 사용되는 executor를 Custom 하여 성능을 극대화 할 수 있다.
executor 커스텀 하는 방법은 @Async 부분에서 알아보자.
public List<String> streamFunction() {
return shops.parallelStream()
.map(s-> todo(s))
.map(s -> s.upperCase())
.map(s -> todo2(s))
.collect(toList());
}public List<String> completableFutureFunction(){
List<CompletableFuture<String>> Futures =
shops.stream()
.map(s -> CompletableFuture.supplyAsync(
() -> todo(s), executor))
.map(future -> future.thenApply(s.upperCase()))
.map(future -> future.thenCompose(s ->
CompletableFuture.supplyAsync(
()-> todo2(s), ForkJoinPool.commonPool())))
.collect(toList());
return Futures.stream()
.map(CompletableFuture::join)
.collect(toList());
}코드에서 ForkJoinPool에 대해서 넣은 것처럼 다양한 Threadpool에 대해서 설정할 수 있다.
Spring에서 @Async 사용하기
Spring은 AOP를 만족시키기 위해 Proxy 패턴을 통해서 AOP를 제공하고 있다.
(메소드 실행 시점 및 런타임 시에 Proxy 적용)
@Async를 사용하기 위해서는 main 메소드에 @EnableAsync 를 추가하거나 커스텀 하고자 하는 스레드 풀에 추가해주면 된다.
Main 함수에 추가하게 되는 경우 SimpleAsyncTaskExecutor를 사용하며 이는 단순하게 쓰레드 생성만 해주는 역할을 하며 이는 쓰레드 관리에 어려움을 가지게 된다.
ThreadPool 설정하기
@Configuration
@EnableAsync
public class SpringAsyncConfig {
@Bean(name = "threadPoolTaskExecutor")
public Executor threadPoolTaskExecutor() {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
taskExecutor.setCorePoolSize(3); // 기본 스레드 수
taskExecutor.setMaxPoolSize(30); // 최대 스레드 수
taskExecutor.setQueueCapacity(100); // Queue 사이즈
taskExecutor.setThreadNamePrefix("Executor-");
return taskExecutor;
}
}기본적으로 core 수 만큼 쓰레드를 생성해서 Task를 처리하게 된다. 쓰레드가 처리하지 못하는 경우 OS에서 스케줄링 할 때 처럼 Queue에 쌓아두고 처리하게 되는데 큐의 최대값에 도달하거나 일의 처리에 지연이 생기면 최대 30개 까지 쓰레드를 생성하여 처리한다.
스레드 풀 설정이 완료되었다면, @Async 어노테이션이 붙은 메소드에서 위 빈의 이름을 붙이면 된다.
@Service
public class TodoClass {
@Async("threadPoolTaskExecutor")
public void todo(String s) {
System.out.println(s);
}
}개발자가 비동기 방식을 원한다면 @Async 어노테이션을 메소드 위에 붙여 주어 높은 가독성을 제공한다. 다만 @Async 기능을 사용하기 위해서는 기본적으로 프록시 모드로 동작하기 때문에 내부 참조,
private 메소드 참조 에서는 적용이 불가능하다.
Forkjoin Pool
Completable Future를 사용할 때에는 자바7에서 추가된 ForkJoin Pool 을 사용한다.
리눅스에서 부모프로세스에서 값을 복사한 자식 프로세스를 생성하는 명령어가 fork() 명령어로 유추해볼 때 쓰레드의 유후시간을 줄이기 위해서 자신의 일을 각 Thread를 생성하여 할 일을 전달하고 병합하는 방식으로 일 처리를 극대화 하는 Pool이다.
이처럼 유후시간을 줄일 수 있고 적절하게 사용하면 쓰레드들이 최적의 CPU 를 활용하는 효율성을 보이겠지만 간단한 업무에 한에서 쓰레드 개별 큐가 추가되고 불필요한 객체생성으로 낭비만 더 해져 성능이 저하될 수 있다.
Java8 과 Java11 차이점
11버전으로 업데이트 됨에 따라 아래와 같이 기능 추가 되었다.
가비지 컬렉터: Java 11에서는 G1 가비지 컬렉터의 개선된 버전이 제공된다. G1 가비지 컬렉터는 대규모 힙 및 다중 프로세서 환경에서 성능을 향상시키고 일시 중단 시간을 최소화하는 데 중점을 둔다.
HTTP 클라이언트: Java 11에서는 기본적으로 HTTP/1.1 및 HTTP/2를 지원하는 새로운 HTTP 클라이언트 API가 도입되었다. 이 API를 사용하여 HTTP 요청을 보내고 응답을 처리할 수 있습니다.
지역 변수 형식 추론: Java 10부터 도입된 지역 변수 형식 추론 기능이 Java 11에서 계속 지원된다. 이를 통해 var키워드를 사용하여 지역 변수의 타입을 추론할 수 있습니다.
문자열 API 개선: Java 11에서는 문자열 처리를 위한 새로운 API가 도입되었습니다. isblank() 와 같은 문자열 API가 추가되었으나 아직은 잘 사용하지 않아 느낌이 오지 않는다.
면접을 준비하는 독자에게
개인적으로 어떤 프로젝트를 진행하면서 어떤 버전을 사용했는지 알아두면 좋을 것 같다. warm-up 으로 버전을 물어보고 해당 버전을 왜 썻는지 물어보는 질문이 있는데 해당 질문부터 답을 하지 못하면 이후 대답에서 좋은 컨디션을 못 낼 가능성이 높기 때문이다. 😂
참고
https://steady-coding.tistory.com/611
https://velog.io/@ehdrms2034/Java-8-CompletableFuture%EC%99%80-%EB%A6%AC%EC%95%A1%ED%8B%B0%EB%B8%8C-%ED%94%84%EB%A1%9C%EA%B7%B8%EB%9E%98%EB%B0%8D-%EC%BB%A8%EC%85%89%EC%9D%98-%EA%B8%B0%EC%B4%88
