
이번에 프로젝트를 마무리 함에 있어서 FastText 와 LDA에 대해 다시 한 번 정리하는 시간을 가져보고자 한다.
LDA 탄생 계기
우선 LDA 즉 잠재 디리클레 할당에 대해서 이해 하기 위해서 토픽 모델링과 기존에 작성하였던 TF-IDF로 추천 시스템 구현하기를 읽어 보면 이해하기 쉽다.
TF-IDF 추천시스템 구현하기
TF-IDF 에서 단점으로 말했던 것처럼 단어의 의미를 고려하지 못한다는 단점이 있었다.
이를 위해서 DTM의 잠재 의미를 파악하기 위해서 LSA라는 것이 처음에 나왔다. 이는 앞에서 autoEncoder에 대해 설명 했을 때 나오는 SVD(truncated SVD) 를 사용하는데 단순하게 말해서 차원을 축소시키고 그 중 값이 높은 것을 잠재적인 의미로 끌어낸다는 아이디어에서 출발 한 것이다.
LSA는 이런 SVD 하나만으로 의미를 파악하기 때문에 구현이 용이하고 잠재의미를 끌어내서 좋은 성능을 보여준다. 하지만 사람들이 사용하지 않는 이유가 무엇일까?
LSA 단점
TF-IDF 에서는 단어를 추가하기 위해 임의적으로 사전에 넣어주는 것을 확인하였다. 이와 더불어 LSA 또한 새로운 데이터를 추가하여 계산하려고 하면 처음부터 다시 계산해야 한다는 단점이 존재한다는 것이다. 따라서 이런 추가적인 학습을 하기 위해서 나온것이 LDA이다.
LDA 이해
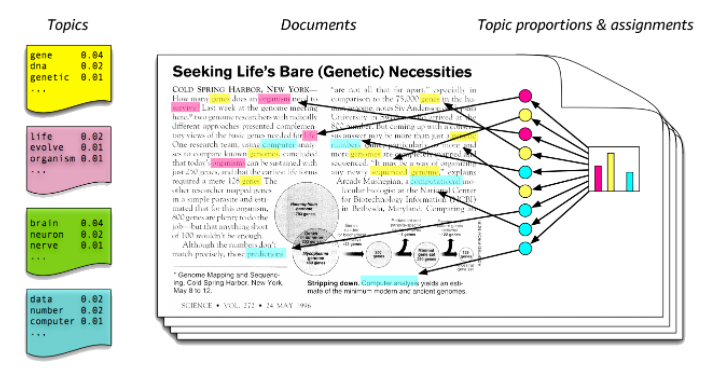
LDA는 LSA처럼 토픽을 찾아내는 프로세스 이다. LSA는 DTM을 차원 축소하여 축소 차원에서 근접 단어들을 토픽으로 묶는 반면에 LDA는 단어가 어느 토픽에 존재할 확률과 문서에 특정 토픽이 존재할 확률을 결합확률로 추정하여 토픽을 추출하는 방식을 말한다. LDA를 사용하여 Topic 을 추출하고 그 주제를 대표하는 단어와 문서 안에 문서를 구성하는 단어의 공통점을 주제어로 태깅을 하게 되는 것이다.
따라서 모든 문서를 학습해서 나오는 문서 전체의 토픽의 의미에 대해서 알 수 있다느 것이다.
LDA 수행과정은 다음과 같다.
- 사용자는 LDA에게 토픽의 갯수를 전달한다.
- 모든 단어를 하나의 토픽에 할당한다.
- 모든 문서의 모든 단어에 대해 아래 과정을 진행한다.
- 문서의 각 단어 w는 자신은 잘못된 토픽에 할당되어 있지만 다른 단어들은 올바르게 할당 되었다고 과정하고 진행하고 w는 문서 단어 들중 해당 단어들의 비율과 각 토픽에서 해당 단어 w의 분포를 기준으로 재할당 된다.
더 자세한 수식 설명은 아래 블로그를 참조 하면 좋다.
https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/06/01/LDA/
LDA 코드 구현
처음에 LDA를 프로젝트에 데이터를 넣는 임시 코드이다. init_vocab_read()로 피클로 저장되어 있는 단어들로 사전을 형성하고 corpus로 만든다. 만든 corpus와 주제 갯수를 정하여 model을 생성하고 저장하면 된다.
def initTrain():
print("first train")
data = init_vocab_read()
dictionary = Dictionary(data)
corpus = [dictionary.doc2bow(d) for d in data]
model = LdaModel(corpus=corpus, id2word=dictionary,
num_topics=10, random_state=1)
save_model(model, dictionary)아래 코드는 모델을 저장하고 불러오는 코드를 함수로 나누어서 정리한 것이다. 마지막으로 코사인 유사도를 사용하기 위해서 matutils 를 사용한 것을 볼 수 있다.
# 모델 저장하기
def save_model(model, dictionary, model_path=model_path, dict_path=dict_path):
model.save(datapath(model_path))
dictionary.save(dict_path)
print("LDA model saved")
# 모델 불러오기
def load_model(model_path=model_path, dict_path=dict_path):
dictionary = Dictionary.load(dict_path)
model = LdaModel.load(datapath(model_path))
print("LDA model loaded")
return model, dictionary
# vec 유사도
def vec_sim(vec_A, vec_B):
return matutils.cossim(vec_A, vec_B)FastText 이해하기
앞에서 word-vec 에 대해 설명하였을 때 OOV에 대해 워드 벡터값을 얻을 수 없고 드물게 나오는 단어에 대해 학습이 불안전 하다고 하였다.
따라서 FastText는 OOV를 해결하기 위해서 n-gram 을 추가하였다. 먼저 단어의 시작과 끝 부분에 <,> 를 추가하고 n=3 이면
where -> <wh, whe, her ,ere ,re> 슬라이딩 윈도우처럼 잘리는 것을 볼 수 있다.
이처럼 단어를 나누어서 표현하게 되면 모르는 단어에 대해서도 비슷한 단어 벡터를 얻을 수 있다. where 과 wherre 은 두개의 subwords만 다르고 대부분이 비슷하기 때문이다.
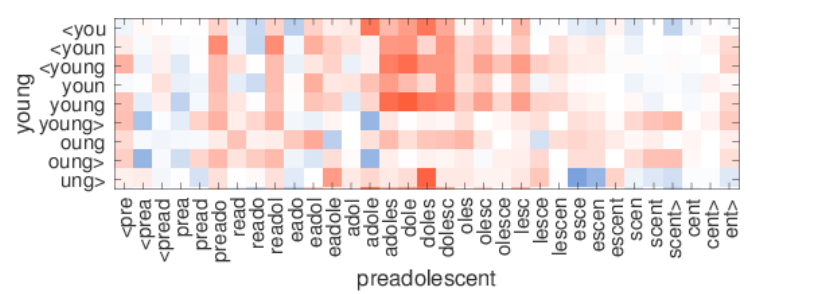
이 과정을 통하여 학습 때 포함되지 않은 단어들에 대해서도 형태적 유사성을 고려한 단어의 벡터를 표현할 수 있게 됩니다.
한글 같은 경우는 텍스트 라는 단어가 있고 n=2 라면 자모단위, 종성 단위로 로 나뉘게 된다.
텍스트 -> <텍, 텍스, 스트, 트>
FastText 코드 구현
실제로 학습하는 부분에서 어떤 프로젝트에 인지 알기 쉬운 Table명과 컬럼들이 존재하여 저장하고 벡터를 비교하는 코드를 가져와 봤다. 모델 로드와 저장은 gensim 공식 홈페이지에서 확인 할 수 있으며 해당 단어 리스트의 벡터값을 추출하는 것은 matutils를 통해 구현하였다.
def save_model(model, path=model_path):
model.save(path)
print("Fasttext model saved")
# 모델 로드
def model_load(path=model_path):
return FastText.load(path)
# 두 단어 리스트 사이의 유사도 측정
def doc_sim(doc_A, doc_B, model=default_model):
return model.wv.n_similarity(doc_A, doc_B)
# 두 벡터 간의 코사인 유사도 측정
def vec_sim(vec_A, vec_B, model=default_model):
return np.dot(vec_A, vec_B)/(norm(vec_A)*norm(vec_B))
# 해당 단어 리스트의 벡터값 추출
def get_doc_vector(doc, model=default_model):
v = [model.wv[word] for word in doc]
return matutils.unitvec(np.array(v).mean(axis=0)) 참고 자료 :
https://coredottoday.github.io/2018/09/01/LDA%EC%99%80-%ED%86%A0%ED%94%BD-%EB%AA%A8%EB%8D%B8%EB%A7%81%EC%97%90-%EB%8C%80%ED%95%9C-%EA%B8%B0%EB%B3%B8%EC%A0%81%EC%9D%B8-%EC%9D%B4%ED%95%B4/
https://wikidocs.net/30708
