Abstract
- Background: LM 모델을 더 크게 만든다고 해서 꼭 사용자의 의도대로 더 좋아지게 발전되는 것은 아님. 예를 들어 large LM은 가끔 untruthful, toxic, or not helpful 결과를 도출해 냄. 이걸 "models들이 user들과 aligned되지 않았다!" 라고 할 수 있음.
- Goal: 휴먼 피드백을 기반으로 finetuning해서 aligning language models with user intent 개발하기!
- Method 'InstructGPT' : ChatGPT는 instructGPT에 dialogue 시스템 조금 덧붙인 것!
1) labeler-written prompts 셋들 수집해서 GPT-3 finetuning 시킴. 2) 모델 아웃풋을 가지고 dataset ranking 을 수집함. 이걸가지고 강화학습으로 supervised model fine-tune하는 거 시킴. - Result: GPT-3보다 InstructGPT 성능 잘 나옴. 훨씬 파라미터 수도 적음.
- Limitation: 여전히 mistake가 있음. human feedback이 더 나은 방향으로 direction 준다
오 AI system 팀에 찰떡인 모델이다!
Introduction
Background
- GPT-3
- transformer에 decoder구조를 사용, in-context learning gpt2부터 적용
- RLHF
- 사람 피드백 적용해서 강화학습을 적용. policy가 large gpt가 된다.
- reward training/policy trainig
- LM에서 강화학습
- policy: text generation
- agent: LM
- action space: LM의 다음 token
- reward function: reward (리워드 최대화하는 방향으로 policy 업데이트)
- Reinforcement
- POO (polict gradient) ???????
policy 신경망 오호 action 확률표가 나온다. - 한계점: gradient 매우 가파를 경우 어떤 행동할지 예측 불가능, 너무 완만하면 학습 진행 불가
=> TRPO (2015) gradient 속도 제한 (구간을 정해서 거기 안에서만 작동하도록 제한을 둔다)
=> PPT (2017): TRPO + Clipping
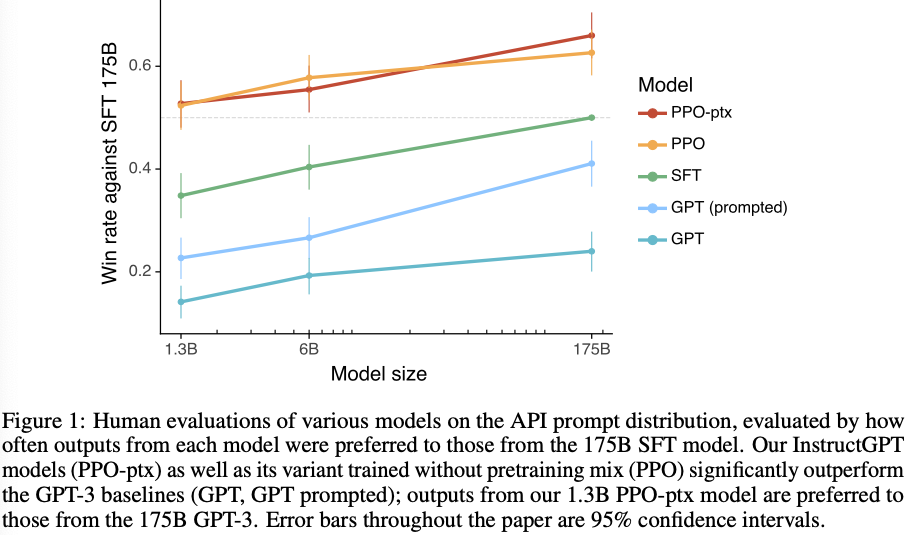
- Labelers significantly prefer InstrcutGPT outputs over outputs from GPT-3
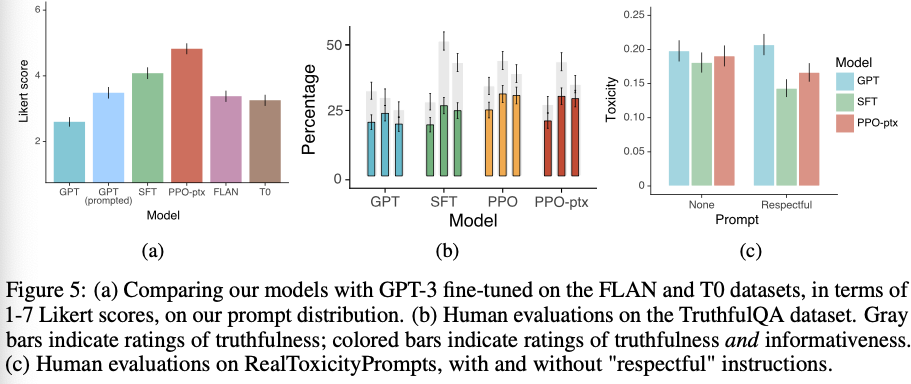
- InstructGPT models show improvements in truthfulness over GPT-3
- InstructGPT shows small improvements in toxicity over GPT-3, but not bias
- We can minimize performance regressions on public NLP datasets by modifying our RLHF fine-tuning procedure
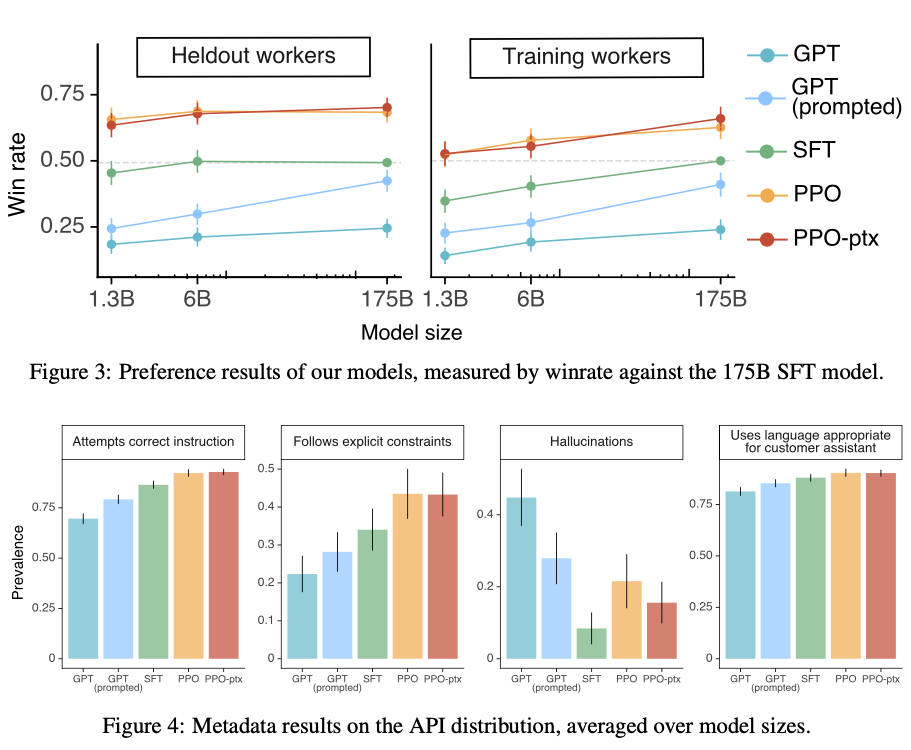
- Our models generalize to the preferences of “held-out” labelers that did not produce any training data.
- Public NLP datasets are not reflective of how our language models are used.
- InstructGPT models show promising generalization to instructions outside of the RLHF fine-tuning distribution.
- InstructGPT still makes simple mistakes.
Related work
- Research on alignment and learning from human feedback.
- Training language models to follow instructions.
- Mitigating the harms of language models.
Methods and Experimental details
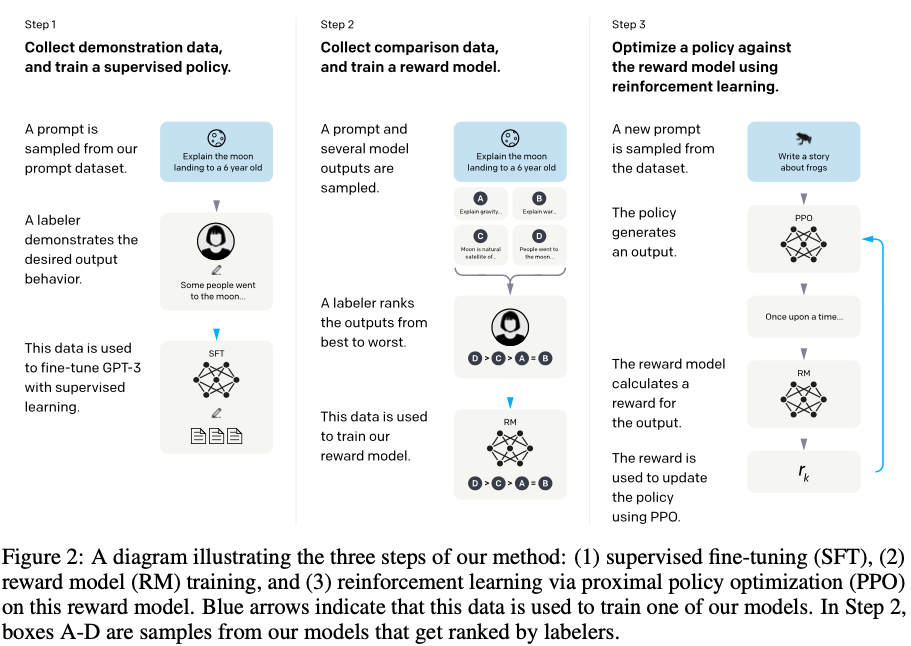
High-level methodology
- step 0: 모델 초기화!! 연구원들이 demenstrate model을 많이 만들었다? reward모델도 초기화 시킴
- Step 1: Collect demonstration data, and train a supervised policy.
- Step 2: Collect comparison data, and train a reward model.
- Step 3: Optimize a policy against the reward model using PPO.
Dataset
Human data collection
Models
- Supervised fine-tuning (SFT)
- Reward modeling (RM)
- Reinforcement learning (RL)
- Baselines
Evaluation
- Evaluations on API distribution
- Evaluations on public NLP datasets
Results
Results on the API distribution
- Labelers significantly prefer InstructGPT outputs over outputs from GPT-3
- Our models generalize to the preferences of "held-out" labelers that did not produce any train- ing data
- Public NLP datasets are not reflective of how our language models are used
Results on public NLP datasets
- InstructGPT models show improvements in truthfulness over GPT-3
- InstructGPT shows small improvements in toxicity over GPT-3, but not bias
- We can minimize performance regressions on public NLP datasets by modifying our RLHF fine-tuning procedure
Qualitative results
- InstructGPT models show promising generalization to instructions outside of the RLHF fine- tuning distribution
- InstructGPT still makes simple mistakes
Discussion
Implications for alignment research
Limitations
- Methodology
- Models
Broader impacts

왈왈