Ref: https://velog.io/@gy77/Review-A-Survey-of-Large-Language-Models-Chapter-2
Background for LLMs
일반적으로 Large Language Models(LLMs)는 방대한 텍스트 데이터로 수천억개(또는 그 이상의) 파라미터를 가지는 Transformer language model를 의미함.
LLMs에 대한 빠른 이해를 위해, 이 섹션에서는 LLMs의 주요 등장배경인 Scaling Law와 Emergent Ability에 대해 소개함.
A. Scaling Law
기존 언어모델들은 일반적으로 기본적인 Transformer 아키텍처의 구조와 Pre-training objective (e.g., language modeling)을 따랐음.
그러나, LLM은 Transformer 아키텍처에서 model size, data size, total compute (orders of magnitude) 부분이 크게 확장된 것임.
이전 연구들은 LLM의 스케일을 확장하는 것이 model capacity를 향상시키는 데 도움을 준다는 것을 발견하였음.
그리고, 그것을 정량화하여 LLM의 performance에 영향을 줄 수 있는 다양한 요인들과 그것의 영향에 대한 특정 공식을 도출해내고자 하였음. (Scaling Law/스케일링 법칙)
이후부터는 Transformer language model을 위한 스케일링 법칙의 가장 대표적인 두 가지 예시를 소개하고자 함.
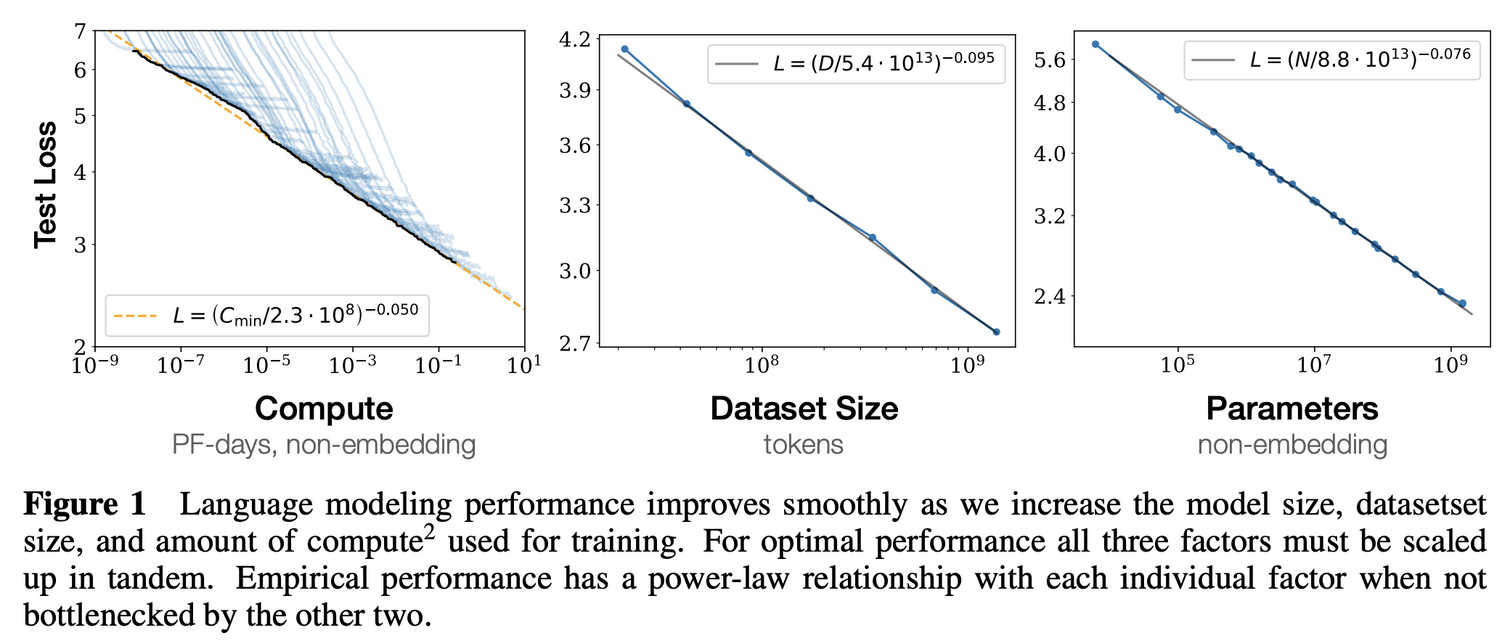
✅ KM Scaling Law (2020) : 2020년 OpenAI 팀은 거대언어모델의 성능과 세 가지의 주요 요인들 간의 관계를 설명하였음.
더 큰 모델, 더 많은 데이터, 더 많은 컴퓨팅을 사용하면 예측 가능한 방식으로 성능이 항상됨. (Power-law) 모델의 크기와 데이터 크기를 동시에 늘리면 성능은 예측 가능하게 증가하지만, 한쪽을 고정하면 어느 시점에서 성능이 향상되지 않음. 즉, 큰 모델은 성능 향상을 위해 더 많은 데이터를 필요로 함.
✅ Chinchilla Scaling Law (2022):
Google DeepMind team이 2022년에 발표한 스케일링 법칙. 이전 연구보다 다양한 스케일의 모델과의 비교를 통해 다른 관점에서의 Scaling Law 제시하였음.
같은 Compute budget 데이터 크기보다 모델의 크기를 더 늘리는 것을 권장했던 이전 연구와는 달리 Chinchilla는 모델, 데이터셋 두 크기를 동일한 스케일로 늘려야 한다고 주장.
같은 계산 비용이라면 더 작은 모델을 더 많은 데이터로 학습시키면 더 좋은 성능을 얻을 수 있다고 주장함. (이전 연구보다 학습 데이터의 양을 보다 강조)
✅ Discussion on Scaling Laws
-
Predictable Scaling
실제로 Scaling Law는 보다 작은 규모의 언어 모델을 Scale up할 때 인풋 대비 성능을 안정적으로 추정할 수 있게 만들었음.
그런데 향후 가용 LLM 훈련 데이터가 소진(exhausted)될 수 있는 환경에서, 데이터 증강 등의 추가적인 기법들을 사용한 LLMs에 Scaling Law이 어떻게 적용될 지에 대한 연구 필요할 것임. -
Task-level predictability
기존의 scaling laws 연구들은 대부분 language modeling loss(e.g., per-token cross-entropy loss)에 초점을 맞춘 반면, 우리가 실제로 관심 있는 것은 actual tasks들을 수행하는 LLM의 성능임.
이에 따라 근본적인 문제는 어떻게 language modeling의 loss의 감소가 task performance의 향상으로 이어질 수 있냐는 것임.
최근 연구들에서 LLMs의 특정 작업(Coding ability)의 성능이 어떻게 정확하게 scaling law를 통해 예측될 수 있는지 연구된 사례도 있음. 일부 테스크에서는 inverse scaling이 발생한다는 사례도 보고되었음. (손실 감소-특정 작업 성능하락)
우리는 언어 모델링 측면에서의 Loss의 감소가 항상 Downstream task의 성능 향상을 의미하지는 않는다는 것을 알고있어야 함.
B. Emergent Abilities
LLM의 Emergent abilities는 종종 "The abilities that are not present in small models but arise in large models"로 정의되며, 이는 LLM과 PLM을 구별하는 가장 두드러지는 특징 중 하나로 고려되고 있음.
Performance rises significantly above random when the scale reaches a certian level.
- 특정 작업을 수행할 때, '랜덤(Random)'은 무작위로 답을 선택하는 것을 의미. → 언어 모델이 기본적으로는 "다음에 나올 가장 적절한 단어"를 확률에 기반해 생성하는 것에 초점을 맞추기 때문에 모델이 해당 작업을 이해한 것이기 보다는, 확률적으로 토큰을 출력하는 것에 지나지 않음.
- 모델의 성능이 이보다 '유의미하게(Significantly)' 높아진다는 것은 모델이 실제로 특정 작업의 본질을 '이해'하기 시작했다는 것을 의미함.
- 즉, LLM이 특정 규모에 도달하면 단순한 확률적 예측을 넘어 더 깊은 수준의 언어 및 테스크에 대한 이해를 보여주기 시작하며, 이것이 PLM과 LLM을 구분하는 가장 두드러지는 특징으로 여겨지고 있다는 것.
- 이후부터는 이러한 능력을 가짐으로써 LLM이 얻게 된 세 가지 능력에 대해 소개함.
✅ In-context learning
추가적 훈련 없이도 test inference 가능
✅ Instruction following
instruction tuning => A-B pair 보고 학습하렴~
일반화 능력 상승
✅ Step-by-step reasoning
단계별 추론!
C. How Emergent Abilities Relate to Scaling Laws
- Scaling Law은 LLM의 연속적인 성능 향상을,
Emergent Abilities는 LLM의 급격한 성능 도약을 의미함. - LLM의 성능 향상(Loss의 감소)이 테스크에 대한 성능 향상을 의미하지는 않음. 테스크에 대한 성능 향상이 어떻게 이루어지는가에 대한 추가적인 연구 필요함을 시사함
- 인간의 언어 발달 및 능력 습득 과정과 유사하다고 보기도 함.
D. Key Techniques for LLMs
LLM이 general하고 capable한 learner로 될 수 있게 만들어주었던 핵심 기법들에 대해 소개
- ✅ Scaling
- ✅ Training : 분산처리알고리즘 등으로 병렬처리 해서 훈련 가능하게 함 DeepSpeech
- ✅ Ability eliciting: general-purpose task solver
- ✅ Alignment tuning: RLHF (reinformcement learning with human feedback)을 활용
- ✅ Tools manipulation: external tools를 활용하기 시작함
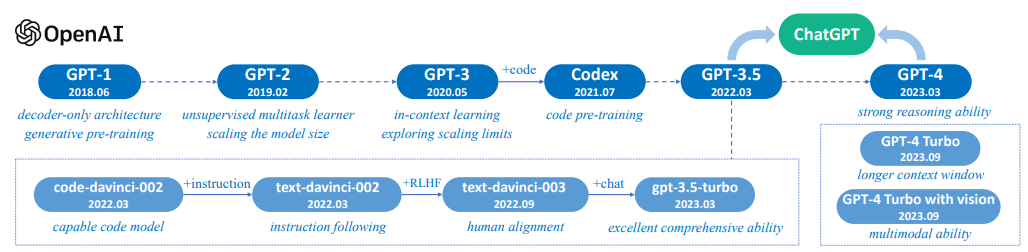
Technical Evolution of GPT-series Models
General-purpose task solver로서의 GPT 성공에는 두 가지 키포인트가 있음.
- Decoder-only Transformer를 훈련하여 다음 단어를 정확하게 예측하는 것.
- Language model의 사이즈를 scale-up하는 것
A. Early Explorations
- ✅ GPT-1 (2018): unsupervised pretraining과 supervised fine-tuning이라는 hybrid approach를 활용함
- ✅ GPT-2 (2019): unsupervised learning 만으로 다양한 테스크를 수행하는 것을 목표로 제작됨. unseen task에 대해서도 잘 동작하는 zero-shot learner를 만들었음. T5, few-shot, task도 같이 넣어준다!
B. Capacity Enhancement
GPT-2가 unsupervised multitask learner로 소개되긴 했으나, 이것은 여전히 supervised fine-tuning sota 모델보다 inferior했음.
GPT-2를 바탕으로 GPT-3은 generative pre-training architecture를 scaling함으로써 key capacity leap을 입증하였음.
-
✅ GPT-3 (2020): meta learning, in-context learning이 가능하게 함! 모델을 상당한 크기로 늘렸을 때 성능이 크게 증가할 수 있다는 것을 경험적으로 보여준 사례임.
-
✅ GPT-3.5:
- Training on code data: 코딩을 가르쳤더니 수학능력이 향상?! plain text로 사전 훈련된 오리지날 GPT-3 모델의 주요 한계는 complex task에 대한 reasoning ability의 부족이었음. (e.g., solving math problem) 이러한 한계를 극복하기 위해 2021년 7월 OpenAI는 Codex를 공개했음. 이는 Github 코드로 fine-tuned된 GPT 모델임.
- Human alignment: 2017년 OpenAI는 인간이 annotation한 preference comparisons 데이터와 강화학습을 통해 인간의 가치를 학습할 수 있다고 밝힘. 이 논문이 발표된 직후인 2017년 7월에 PPO(Proximal Policy Optimization) 논문이 발표되었으며, 이는 현재 human preferences를 학습하기 위한 foundational RL algorithm으로 사용되고 있음.
C. The Milestones of Language Models
-
✅ ChatGPT
ChatGPT는 InstructGPT와 유사한 방식으로 학습되었음 (called "a sibling model to InstructGPT" in the original post) 그러면서도 dialoge에 특화된 모델이라고 할 수 있음.
특히, 두 모델은 학습 데이터에서 차별화되어 있음. ChatGPT의 데이터는 InstructGPT의 데이터에 추가적으로 human-generated conversations (playing both the roles of user and AI)를 훈련한 것임. 이를 통해 기본적인 상식, 인간의 지시를 이해하는 능력을 유지할 뿐만 아니라 multi-turn 대화이해 능력까지 보유할 수 있게 됨. -
✅ GPT-4
2023년 3월 출시, 멀티모달 입력을 지원하는 모델임. GPT-3.5보다 더 복잡한 테스크를 해결할 수 있으며 추가적인 alignment (RLHF traninig) 통해 환각, 프라이버시, 악의적인 쿼리에 보다 안전하게 응답할 수 있게 됨.
또한 이때 OpenAI는 predictable scaling이라는 새로운 메커니즘을 소개하였음. (모델 훈련 중 small proportioin of compute 만으로 final performance를 정확히 예측할 수 있는 기법) => 미리 예견해서 학습해야하는 거 좀 대비 가능해졌다 -
✅ GPT-4V, GPT-4 turb, and beyond
- GPT-4V: GPT-4 발표 후 OpenAI는 2023년 9월 GPT-4V를 공개하였음. 이는 GPT-4의 vision 기능의 안전한 배포에 초점을 두었음.
- GPT-4 turbo: 동시에 Assistants API가 런칭되면서 agent-like assistants 를 개발하기 엄청 쉬워졌음. 개발자들은 특정 지시사항이나 외부 전문지식을 추가하여 자신만의 챗봇을 만들고 서비스할 수 있게 됨. (chatgpt 기반 챗봇 많이 만들 수 있다!)
나의 의견 정리
어쨌든 계속해서 목적은 사람의 일을 얼마나 대체하여 잘 할 수 있는가구나?!
어떤 점이 인간을 대체하기 힘든지를 확인하는 게 중요하겠다.
kdd 연구할 때 COT ablation 구조 짜봐야겠다!
