Syllabus
- Introduction
- Data-Centric AI vs. Model-Centric AI
- Label Errors
- Dataset Creation and Curation
- Data-centric Evaluation of ML Models
Class Imbalance, Outliers, and Distribution Shift- Growing or Compressing Datasets
- Interpretability in Data-Centric ML
- Encoding Human Priors: Data Augmentation and Prompt Engineering
- Data Privacy and Security
Introduction
page: https://dcai.csail.mit.edu/lectures/imbalance-outliers-shift/
Lab: https://github.com/dcai-course/dcai-lab/blob/master/outliers/Lab%20-%20Outliers.ipynb
What we are going to learn?
- class imbalance
- outliers
- distribution shift
Class imbalance
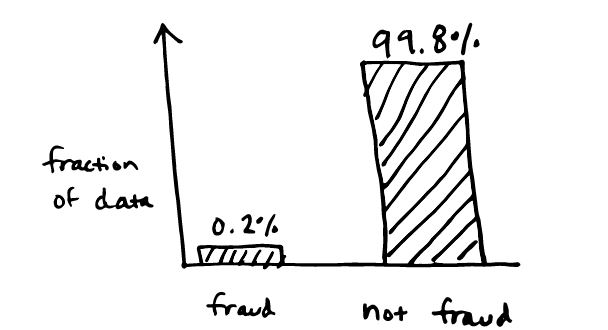
- Evaluation metrics
- precision, recall, f1 score
- Training models on imbalanced data
- Sample weights
- Over-sampling
- Under-sampling
- SMOTE (Synthetic Minority Oversampling TEchnique)
- Balanced mini-batch training
Outliers
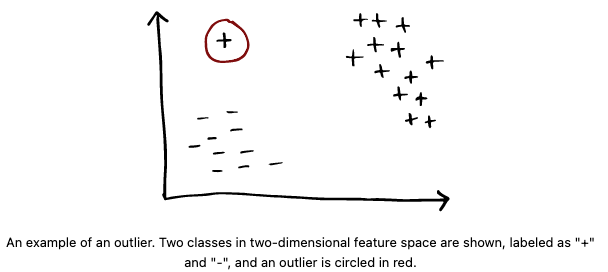
- Problem setup
- Outlier detection
- Anomaly detection
- Identifying outliers
- Tukey’s fences:
- IQR = Q3 - Q1 기준으로 밖에는 아웃라이어로!
- Z-score
- Isolation forest
- decision trees 관련- "랜덤 의사결정 트리" 생성하고얼마나 많은 노드가 필요한지에 따라 데이터 포인트 점수를 매김
- 알고리즘은 무작위로 특징과 분할값을 선택하여 (일부) 데이터셋을 재귀적으로 분할하는데, 재귀적으로 분할하여 하나의 인스턴스만 포함된 하위 집합이 될 때까지 진행.
- 아웃라이어 데이터 포인트는 고립되기 위해 더 적은 분할이 필요하다는 아이디어에 기반.
- KNN distance
- 내부 분포 데이터는 이웃과 가까울 가능성 높음. 데이터 포인트의 k개 최근접 이웃까지의 평균 거리(코사인 거리와 같은 적절한 거리 측정 기준을 선택)를 점수로 사용. 이미지와 같은 고차원 데이터의 경우, 훈련된 모델의 임베딩을 사용하여 임베딩 공간에서 KNN을 수행할 수 있음.
- Reconstruction-based methods
- 오토인코더는 고차원 데이터를 저차원 표현으로 압축한 다음 원래 데이터를 재구성하는 방식으로 훈련된 생성 모델.
- 만약 오토인코더가 데이터 분포를 학습한다면, 내부 분포의 데이터 포인트를 인코딩한 후 다시 디코딩하면 원래 입력 데이터와 유사한 데이터 포인트로 재구성할 수 있어야 함.
- 그러나 외부 분포 데이터의 경우, 재구성은 더 나빠질 것이므로 이상치를 탐지하기 위해 재구성 손실을 점수로 사용할 수 있음.
- Tukey’s fences:
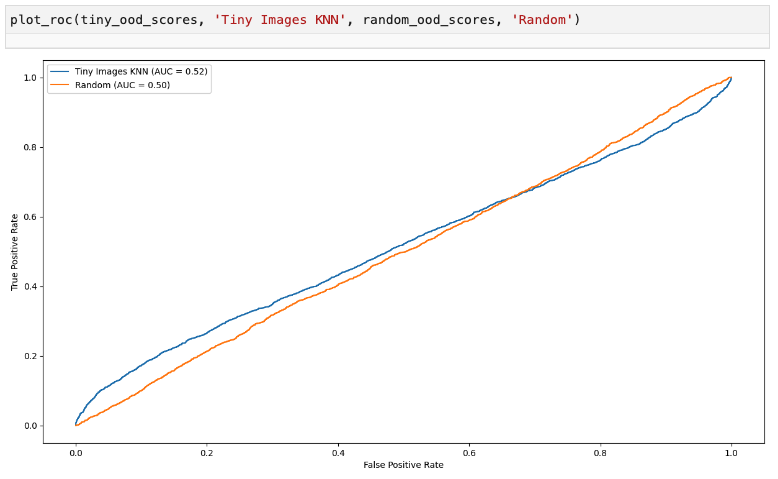
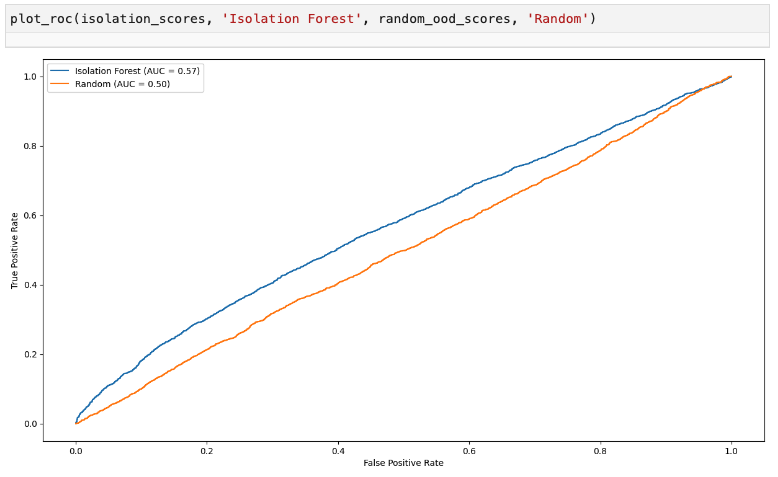
많은 이상치 탐지 기법에서는 모든 데이터 포인트에 대한 점수를 계산하고 임계값을 설정하여 이상치를 선택하는 방식을 사용합니다. 이상치 탐지 방법은 ROC 곡선을 확인함으로써 평가할 수 있으며, 여러 방법을 비교하기 위해 단일 요약 숫자인 AUROC를 확인할 수도 있습니다.
Distribution shift

distribution shift는 train데이터랑 test 데이터랑 데이터 분포가 다를 때 문제가 생김!
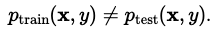
Types of distribution shift
-
Covariate shift / data shift
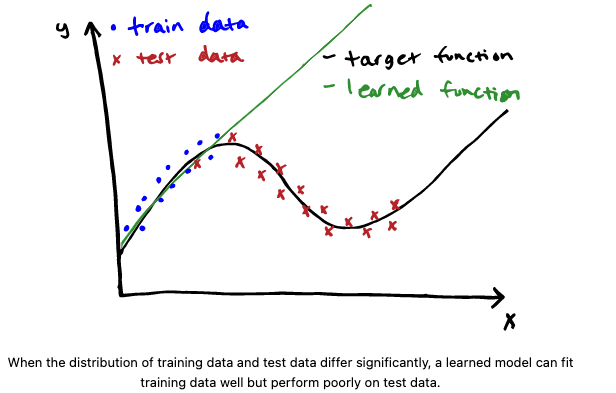
- p(x)는 train, test에서 다른데, p(y|x)는 변함 없을 때 발생. 즉, train, test에 들어가는 input의 분포는 다른데, input과 output간의 relationship은 변함이 없음!
- 예시
- 샌프란시스코의 화창한 도로에서 훈련된 자율주행 자동차를 보스턴의 눈이 내리는 도로에 test
- 원어민 영어 사용자로 훈련된 음성 인식 모델을 모든 영어 사용자에 대해 test
- 보스턴의 병원 데이터로 훈련된 당뇨 예측 모델을 인도 병원에서 사용
-
Concept shift
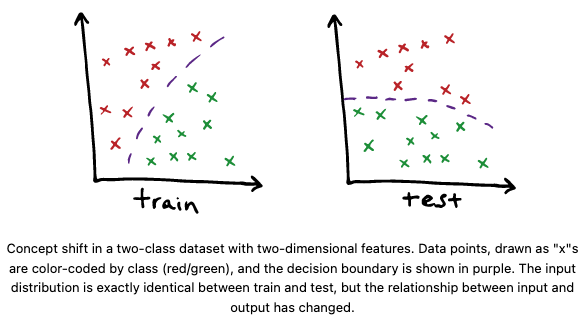
- 이건 위의 covariate shift랑 반대로! p(y|x)는 train, test에서 다른데, p(x)는 변함이 없음! 즉 input의 분포는 변함이 없는데, input과 output간의 관계가 변한다는 거임. 이 경우가 distribution shift 탐지하기 제일 어렵고 까다로운 유형임
- 예시
- 1975년의 데이터로 훈련되고 2023년에 배포된 회사 펀더멘털을 기반으로 주가를 예측합니다. 회사 펀더멘털에는 주당 수익과 같은 통계.
- 팬데믹 이전 데이터에 대해 교육을 받고 2020년 3월에 배포된 웹 브라우징 행동을 기반으로 구매 추천.
-
Prior probability shift / label shift
- 이건 y->x 일때만 발생 (y causes x, y는 x를 유발한다). train과 test 사이에서 p(y)가 달라지고, p(x|y)는 안달라졌을 때 발생. covariate shift의 완전 반대구만?
- 예시
- 스팸 분류에 일반적으로 사용되는 모델인 나이브 베이즈를 사용. 모델이 50%의 스팸과 50%의 스팸이 아닌 이메일로 구성된 균형 잡힌 데이터셋으로 훈련된 후, 90%의 이메일이 스팸인 실제 환경에서 모델을 배포할 때.
- 증상을 기반으로 진단을 예측하는 분류기를 훈련할 때, 질병의 상대적 유병률이 시간에 따라 변하는 경우...! 질병이 증상을 일으키기 때문. (오... bipolar라면..?!)
Detecting and addressing distribution shift
test 상황에서 distribution shift 탐지하는 방법
- 모델의 성능 모니터: 정확도, 정밀도, 통계적 측정 또는 기타 평가 지표 모니터링. 이러한 지표가 시간에 따라 변화한다면, 분포 변화 때문일 수 있음.
- 데이터 모니터: 훈련 데이터와 배포 데이터의 통계적 속성을 비교하여 데이터 변화를 감지.
Code

Visualize some of the data
Evaluation metrics
Baseline methods
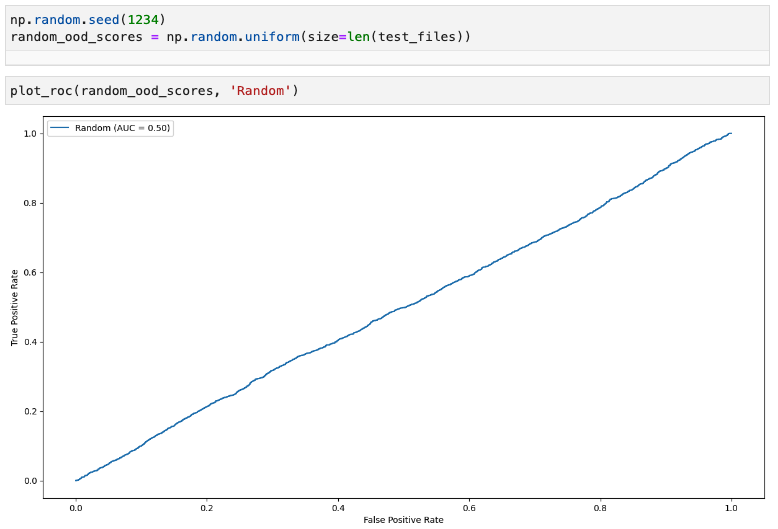
Random scores
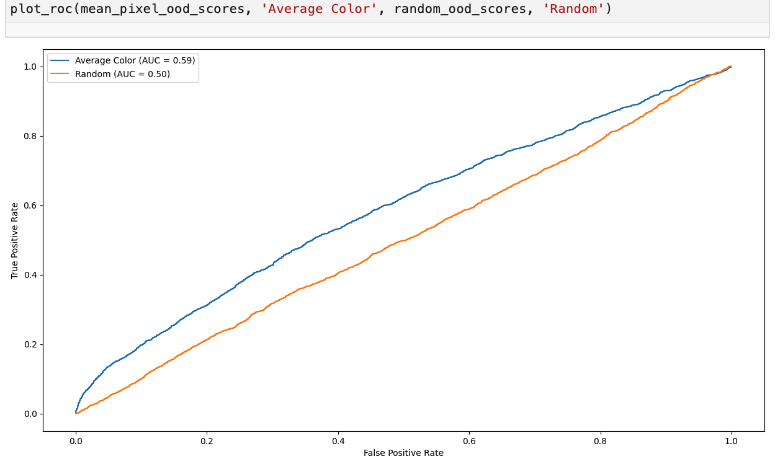
Average color
KNN in image space, on resized images
Isolation forest on image histograms

Comparing the (very simple) methods we implemented
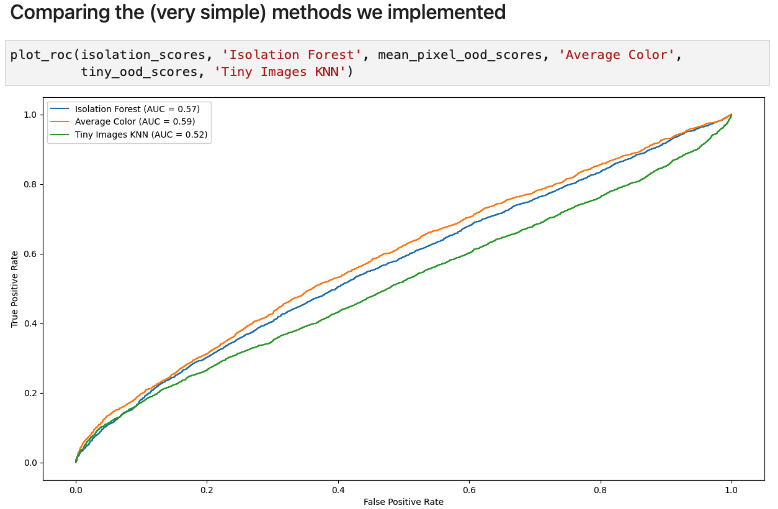
Exercise: implement and compare outlier detection methods
Compute embeddings
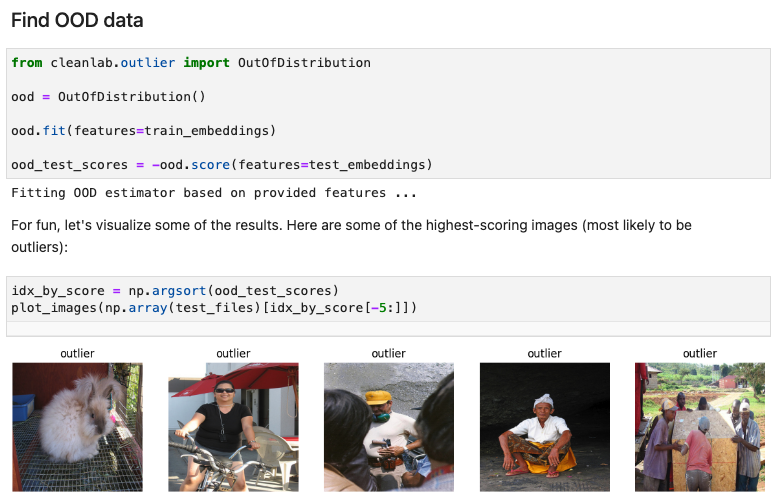
Find OOD data
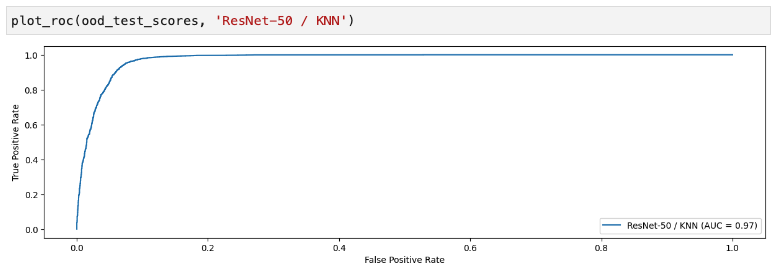

왈왈
데이터 샘플링을 어떻게 하면 좋을지 와 관련해서 여러 아이디어를 얻고 생각해볼 수 있는 시간이었어요!!! 어노테이터도 어떻게 하면 좀 더 신뢰를 높일 수 있을지 한 번 더 생각해봐야겠네여 !! 좋은 발표 감사합니당 !