Syllabus
- Introduction
- Data-Centric AI vs. Model-Centric AI
- Label Errors
Dataset Creation and Curation- Data-centric Evaluation of ML Models
- Class Imbalance, Outliers, and Distribution Shift
- Growing or Compressing Datasets
- Interpretability in Data-Centric ML
- Encoding Human Priors: Data Augmentation and Prompt Engineering
- Data Privacy and Security
Introduction
page: https://dcai.csail.mit.edu/lectures/dataset-creation-curation/
Lab: https://github.com/dcai-course/dcai-lab/blob/master/dataset_curation/Lab%20-%20Dataset%20Curation.ipynb
What we've learnt?
- Data-Centric AI vs. Model-Centric AI
- Data-centric pipline:
- Step 1:데이터가 있으면, 일단 탐색해보고 ML에 맞게 변형을 한다!
- Step 2: 변형된 데이터를 가지고 일단 ML 실험을 돌려봐
- Step 3: 모델을 개선하기 전에 data-centric ai 기술을 적용해서 여러 실험을 돌려봐라!
- Step 4: 3단계에서 개선된 데이터셋을 가지고 이제는 모델링 기술들을 적용해서 실험해봐라!
*신신당부: 절대 2단계에서 4단계로 뛰어넘지 말고, 좋은 시스템 구축을 위해서 3-4단계를 반복해라!
- Data-centric pipline:
- Label Errors and Confident Learning
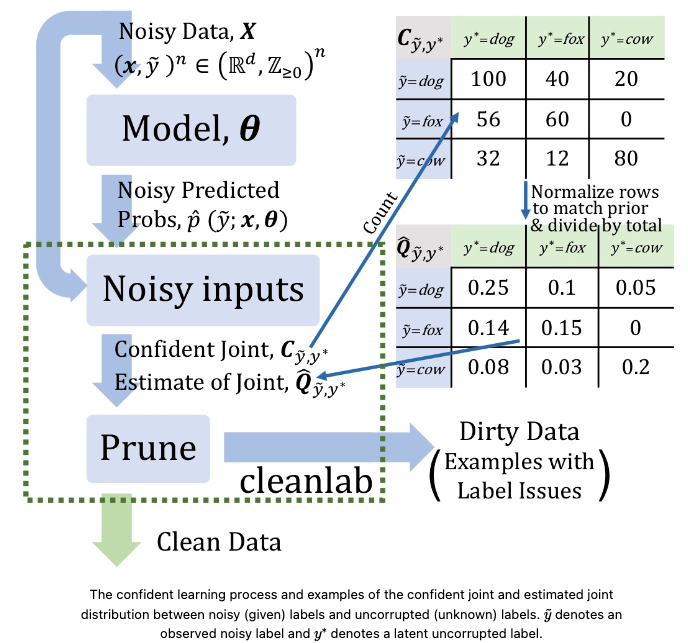
What we are going to learn?
Supervised learning을 위해 데이터셋 구축 및 curation을 위한 고려해야할 사항들 알아보기
- 우리가 하려는 task에 맡게 class들이 잘 정의되어 있나?
- 데이터를 sourcing하는 건 제대로 했나? (e.g. selection bias)
- 라벨 annotation은 적절하게 했나?
Sourcing data
학습 데이터를 수집할 때 꼭 고려해야할 사항!!
- ML 모델의 결과를 어떻게 사용할 것인가? 어떤 모집단을 대상으로 모델이 예측을 진행할 것인가?
- 모델이 반드시 정확한 예측을 해야하는 그런 high-stakes 시나리오는 어떤 것이 있는가? (우리 연구로 치면 자살 위험도 제일 높은 사람 예측하는 거?)
Selection Bias
- [퀴즈!] image classifier가 왼쪽 그림은 잘 맞췄는데, 오른쪽 그림은 잘 못맞췄다! 왜 일까?
[정답!] 학습데이터 중 소들이 있는 배경은 대부분 푸르른 들판이 있는 곳이었어서!
High-capacity ML 모델들은 정확도를 높이기 위해서 학습 데이터를 기반으로 any correlation을 사용한다. 그럼 이때 real-world와는 다른 correlation을 사용하게 되기 때문에 (== Spurious correlations (가짜 상관 관계)), real-world 데이터셋에는 저조한 성능을 보일 수 밖에 ㅠ_ㅠ
⇒ Spurious correlations은 selection bias로 인해 발생할 수 있음.

📎 Beery, S., Van Horn, G., and Perona, P. Recognition in terra incognita. European Conference on Computer Vision, 2018.
Challenge
selection bias (== confounding ,distrbution shift) 는 수집된 학습 데이터의 분포와 모델이 예측해야할 실제 real-world 데이터 분포 사이의 systematic 편차를 말함. 즉, 학습 데이터가 real-world setting을 대표하지 못하는 것임. 그런데! 이게 modeling 으로는 bias가 있는지 설명하기가 굉장히 어려움. 따!라!서! 데이터를 수집하기 전부터 bias를 일으킬 수 있는 잠재적인 원인들을 잘 파악하는 게 필요함.
- Selection Bias 원인 예시들
| Bias | Detailed | |
|---|---|---|
| 1 | Time/location bias | 데이터를 수집했던 과거 상황과 현재 상황이 달라졌을 때, or 수집한 지역과 예측해야하는 지역이 다를 때 |
| 2 | Demographics bias | 수집한 데이터가 소수의 집단만을 대표할 때 (under-represented) |
| 3 | Response bias | 설문조사 응답률, 질문의 형식이나 답변의 형식에 따른 prompting bias |
| 4 | Availability bias | most representative 대신 주변에서 쉽게 구할 수 있는 데이터를 사용, 친구들만 설문조사 한다는 등 (이것도 under-represented 겠군) |
| 5 | Long tail bias | 아주 드물게 나타나는 시나리오들. 얘네는 학습 데이터에 포함 안되어있을 경우가 다분 (자율주행 자동차가 갑자기 처음보는 길로 진입해버리거나 사고를 내버림) |
Selection Bias 해결책
일단 데이터에 selection bias가 생기면 modeling을 통해서 mitigating하긴 어려움. 그래서 차선책으로 예상할 수 있는 bias 상황들을 고려해서 evaluation을 잘하는 것임!
- ex 1) 데이터 수집했을 때와 현재 상황이 바뀌었다면, 가장 최근 데이터를 validation set으로
- ex 2) 만약 데이터를 다양한 지역에서 수집했다면, 특정 지역에서 수집한 데이터를 다 validation set으로!
- (이건 번역을 정확하게 했는지 모르겠음…!!!!! ) If data are collected from multiple locations and new locations will be encountered during deployment, one might reserve all data from some locations for validation.
- ex 3) 만약 데이터가 rare하지만 엄청 중요한 케이스를 포함하고 있다면, validation set 구성할 때 이 데이터셋들을 over-sample 해가지고 뻥튀기!
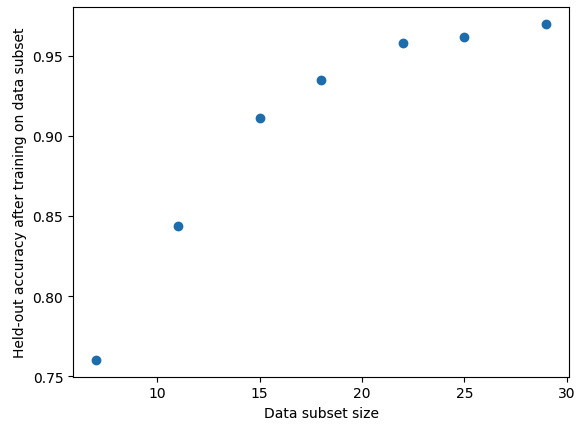
How much data will we need to collect?
우리가 95퍼센트의 정확도를 내고 싶다고 했을 때, 어느 정도의 데이터 샘플이 있어야 이게 가능할 까? 어떤 기준으로 데이터를 추가 수집해야할까?
Notation
- D_train : n sample의 학습 데이터
- D_val : 고정된 숫자의 val 데이터
실험 setting
- 다양한 비율로 샘플 사이즈를 조정해서 데이터 pair를 만든다!
- i: label을 뜻하는 듯 (클래스별로 stratified한다고 했음)
- j: original 대비 몇 퍼센트의 데이터셋 묶음할지
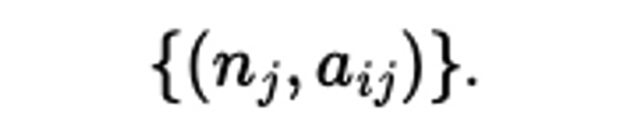
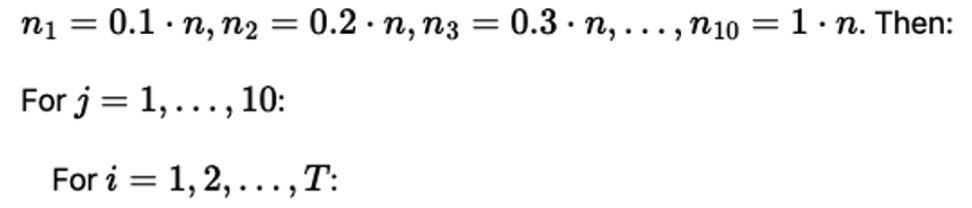
Goal
데이터 수에 따라 라벨별 정확도 어떻게 달라지는지 확인하여, sample 수가 미치는 영향 파악해본다.
여기서 잠깐! 이때 KNN이나, Liniear Regression 모델을 쓰는 건 부적절한 이유는 뭘까?
=> 이건 extrapolation (외삽) 과 interpolation (보간)을 알아야 하는 거구나?!
💛 extrapolation (외삽법) Vs interpolation (보간법)
- 대상 영역:
- 외삽: 주어진 데이터 범위를 벗어나는 외부 영역에 대한 값을 예측합니다. 따라서 외삽은 기존 데이터 범위를 넘어서는 새로운 영역에 대한 예측을 수행합니다.
- 보간: 이미 알려진 데이터 포인트 사이에서 새로운 값을 예측합니다. 보간은 주어진 데이터 범위 내에서 누락된 값이나 부드러운 곡선을 생성하는 데 사용됩니다.
- 사용 방법:
- 외삽: 외삽은 기존 데이터 패턴이나 동작을 기반으로하여 미래 예측이나 미지의 영역에 대한 값을 결정합니다. 이는 기존 데이터의 추세를 이용하여 데이터 범위를 넘어서는 값을 예측합니다.
- 보간: 보간은 주어진 데이터 포인트 사이에서 데이터의 누락된 부분을 채우거나 원활한 곡선을 생성하기 위해 사용됩니다. 보간은 주어진 데이터 범위 내에서의 누락된 값을 예측하며, 데이터 간의 관계를 이용하여 부드러운 곡선을 생성합니다.
- 결과의 신뢰성:
- 외삽: 외삽은 기존 데이터의 패턴을 따르는 가정에 의해 예측을 수행하기 때문에, 데이터 범위를 벗어난 예측은 불확실성을 가질 수 있습니다. 따라서 외삽 결과는 주의해야 하며, 데이터 범위를 벗어난 예측이 정확하지 않을 수 있습니다.
- 보간: 보간은 이미 주어진 데이터 포인트 사이에서 예측을 수행하기 때문에, 주어진 데이터의 신뢰성에 따라 결과의 신뢰성이 결정됩니다. 보간은 기존 데이터 포인트 사이의 패턴을 보존하므로, 주어진 데이터가 정확하고 신뢰할 경우 결과도 정확하고 신뢰할 수 있습니다.
따라서 우리는 지금 정확도 예측에 초점을 맞추고 있기 때문에 unseen data에서 얼마나 잘하냐! 이걸 보고 있지 않습니까? 그래서 interpolation 방식인 KNN이랑 linear regression은 적절하지 않은 것임!!!!!
- interpolation 예시
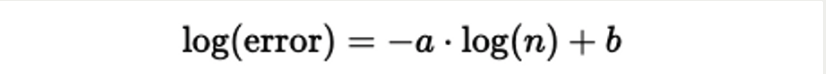
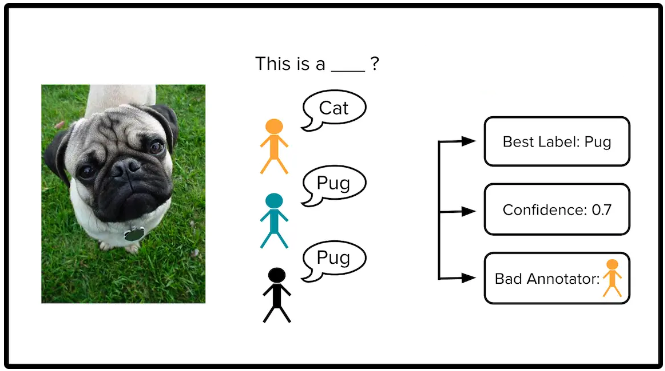
Labeling data with crowdsourced workers
데이터 annotation 작업을 할 때 한 명의 annotator만 작업을 하면 오류를 낼 수 있기 때문에, 여러명의 사람들이 같이하는 것이 더 reliable한 라벨을 생성할 수 있다.
Challenge
- 모든 annotator가 모든 data samples에 대해 annotation 못할 가능성 높음.
- 특정 annotator들은 다른 사람들에 비해 정확도가 낮을 수 있음
- 일부 annotator들은 다른 annotator와 공모해서 annotation 진행할 수도 있음.
해결책
이미 우리가 ground truth를 알고 있는 데이터셋을 스리슬쩍 넣어서 “quality control” 진행. 그럼 해당 데이터를 어떻게 annotation한 걸 보고 어느정도 신뢰할 수 있는지 확인해볼 수 있겠구먼! 오오오오오…!
Curating a dataset labeled by multiple annotators
하지만! 이미 annotation을 해버려서 “quality control” 데이터셋을 못 넣었던 상황이라면 다음 3가지로 대체해보자!
- consensus label: annotation 결과에 대해 consensus label을 구한다.
- consensus label에 대해 quality score: 이 라벨이 정확하다는 것을 얼마나 확신하는지 (Majority Vote)
- 각 annotator에 대한 quality score: annotator들의 전반적인 correcteness 계산 (Inter-Annotator Agreement)
- ‘+ (Dawid-Skene, and CROWDLAB)
Majority Vote and Inter-Annotator Agreement

-
**Majority Vote**
가장 쉬운 방법은! 가장 많이 annotation된 라벨을 다수결로 consensus label로 지정하는 것!
ex) i dataset에 대해서 annotator들이 어떤 label로 annotation했는지 보고 가장 많이 투표한 걸로 지정!
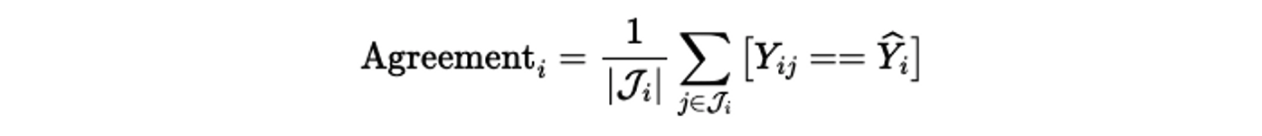
-
**Inter-Annotator Agreement**
위에서 consensus label을 구했음! 그럼 이제 그걸 ground-truth라고 생각하고 annotator별로 얼마나 잘 맞췄는지를 확인해보는 거임! 그럼 해당 annotator가 얼마나 좋은 품질의 라벨링을 했는지 알 수 있음
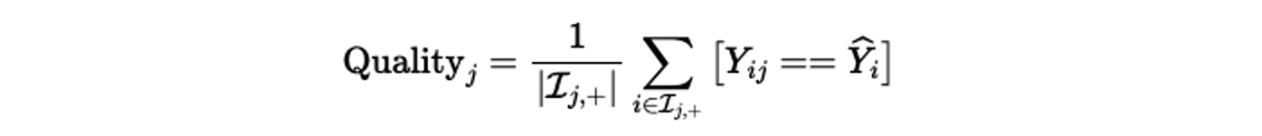
Dawid-Skene (페이지엔 써 있는데, 수업에선 설명을 안해줘서.. 대충 넘어갈게요..)
Paun, S., et al. Comparing Bayesian Models of Annotation. Transactions of the Association for Computational Linguistics, 2018.
- **Majority Vote & Inter-Annotator Agreement 방법의 단점!**
- majority vote 시에 동점이 나와버리면 어떻게 하지?
- bad annotators가 한 결과는 good annotators의 결과와 동일하게 취급받는다.
- **Dawid-Skene 등장! **
- 주어진 라벨링된 데이터에서 작업자의 신뢰성과 작업 항목의 진실성을 동시에 추정하는 확률적 모델
- 일반적으로 작업자들이 다른 의견을 가지거나 작업 항목에 대해 애매한 경우에 유용
- **작동 방식**
EM(Expectation-Maximization) 알고리즘을 기반으로 작동합니다. 초기에는 작업자들의 신뢰성 및 작업 항목의 진실성에 대한 사전 분포를 가정하고, E 단계에서는 해당 가정을 사용하여 작업 항목에 대한 작업자의 신뢰성과 작업 항목의 진실성에 대한 추정치를 계산합니다. 그런 다음 M 단계에서는 추정치를 사용하여 작업자의 신뢰성 및 작업 항목의 진실성에 대한 사후 분포를 업데이트합니다. 이러한 E 단계와 M 단계를 반복하면 모델은 점차적으로 작업자들과 작업 항목의 신뢰성 및 진실성에 대한 더 정확한 추정치를 얻게 됩니다. - **Dawid-Skene의 단점**
- 라벨들이 데이터의 feature랑 어떤 연관이 있는지에 대해서는 완전히 무시하고 간다.
- annotator들이 noisy한 라벨링을 한거면, Dawid-Skene은 한명의 annotator에 의해서 라벨링된 example에 대해서는 reliable한 concensus를 뽑아낼 수 없음.
- Dawid-Skene은 무조건 전체 annotator들에 대해서 KxK 메트릭스 파라미터를 측정해야함. 근데 데이터가 제한적이면 이걸 계산하는게 힘들 수 있음. 특히 특정 annotator는 몇개 라벨링을 안하거나 다른 주석자들이랑 annotation결과가 안겹치면 더 계산하기 힘듦.
또 다른 간단한 방법! (feature까지 고려)
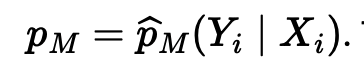
- 지금까지 annotator들이 수행한 결과를 가지고, 모델을 훈련시켜서 결과값을 뽑게 함. 우리는 이제부터 이 모델을 또다른 annotator로 취급하는 거임!
- 그래서 동점인 상황에서는 투표자가 한 명 더 생겼으니까 판결을 내릴 수 있고, 만약 한명만 주석한 데이터의 경우에서도 classifier가 정확하다는 가정하에 더 확신을 할 수 있도록 도와줄 수 있음.
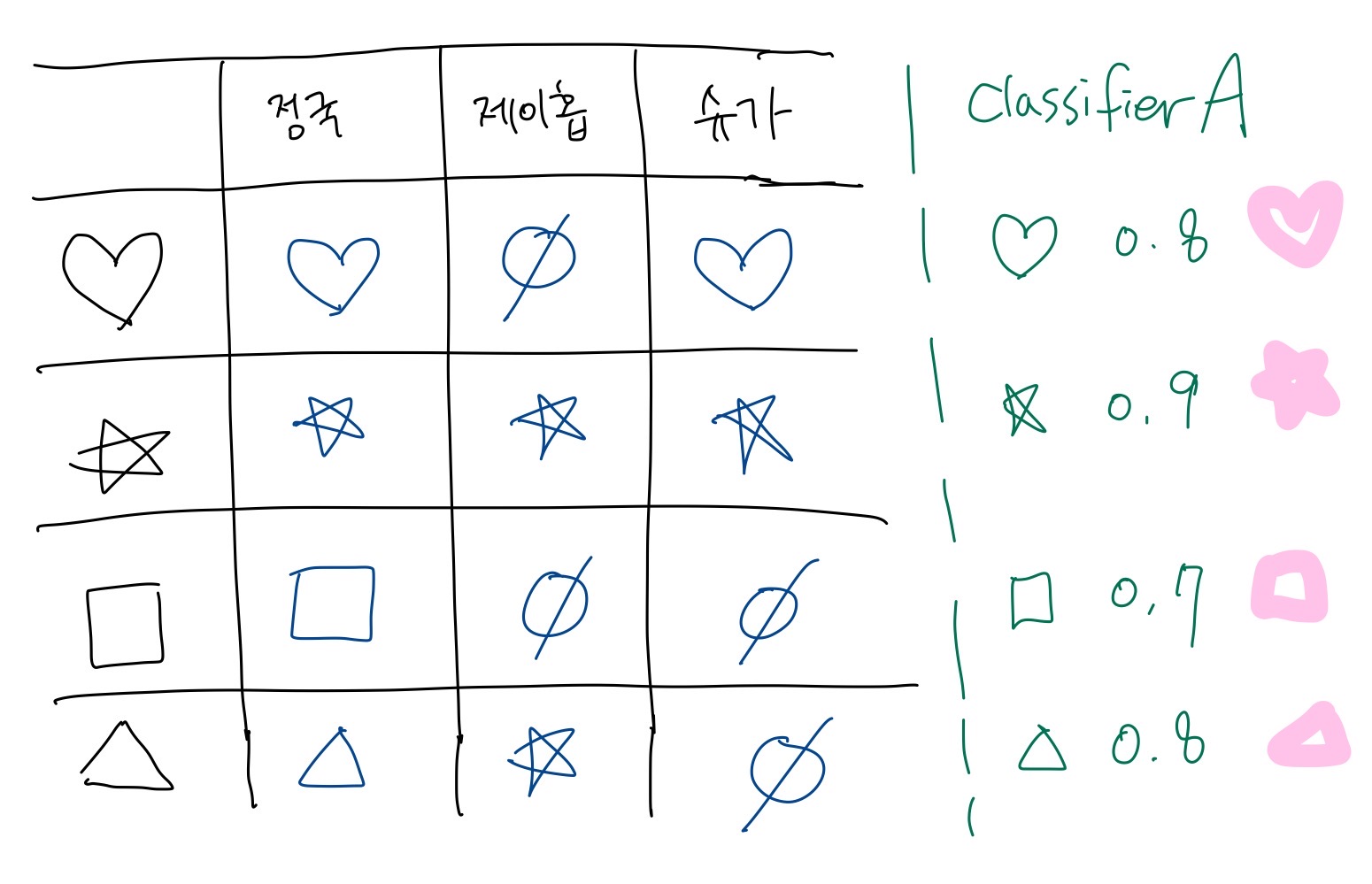
CROWDLAB (Classifier Refinement Of croWDsourced LABels)
위의 세가지 추정 방법보다 제일 나은 방식! LAB에서도 얘를 다룰 것임.
- 작동방법
- classifier가 뽑아낸 확률값과 주석자들이 평가한 라벨을 모두 고려하여 가중 평균을 사용해 확률 뿐만 아니라 자기가 얼마나 이 예측에 confident있는지 계산함.
- 위에서 본 예제에서 처럼 많은 주석자들이 다수결로 동의된 예제는 굳이 분류기의 의견이 중요하지 않지만, 소수의 사람들이 라벨링한 예제에 대해서는 분류기의 입김이 쎄져야함!! 그래서 단일 주석이 신뢰할 수 있는지 여부를 더 잘 평가하는 데 도움이 될 수 있음.
- 1) 위에서처럼 classifier의 확률값을 구함.
- 2) 그런데! 여기에 각 주석자들의 라벨값 확률을 더해줌! (예-3명중에 1명만 하트라고 했대~)
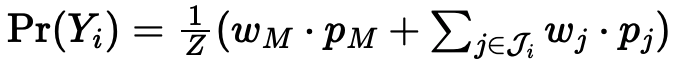
- 3) 그럼 여기서 가중치 w가 주석자랑 classifier 중에서 누가 더 믿을만한 놈인가를 계산하면서 업데이트 될 것임. 주석자의 신뢰도가 낮으면 분류기에서 나온 값이 더 많이 반영될 것임. (모든 주석자 평균내니까 주석자마다 동일한 가중치가 반영되는 군)
- 4) 그럼 다시 majority vote 등을 진행하면 됩니다!!
근데 이런데도 수렴이 안한다? 그럼 계속 반복해서 위의 작업을 하면됨.
디테일한 수식들이 있지만 넘어가겠음 ^^
Code
Task
CROWDLAB을 이용하여 주석 결과값이 동점이 상황에서 최선의 라벨을 찾아랏!
데이터 로드

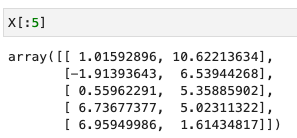
- X: 학습 데이터 (3 classes, 2d features)
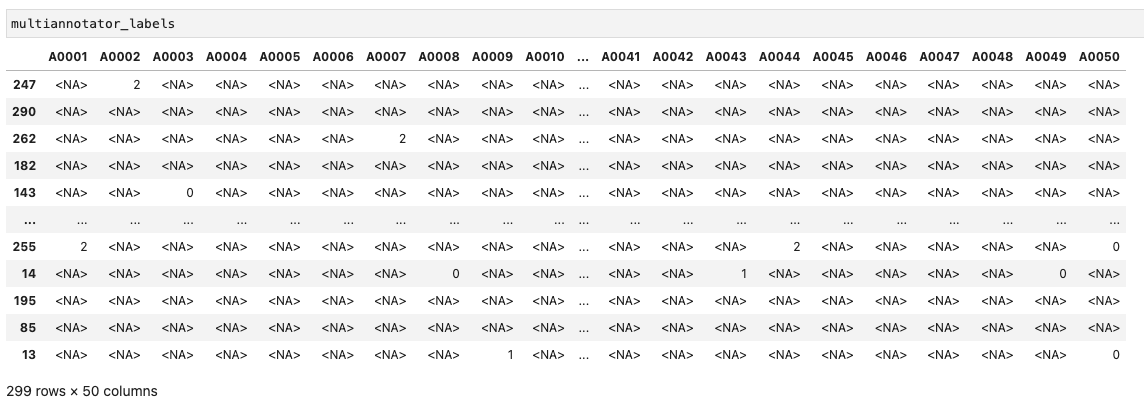
- multiannotator_labels: 어노테이션 결과
(예시로 아래와 같이 데이터셋을 만들었음.)- columns은 어노테이터들 아이디
- rows는 아이템들
- values는 주석자들이 라벨링한 값 (0~3), NA같은 경우는 주석 작업 안한 케이스임!
- true_labels: ground truth labels이긴 하지만, 분석에 쓰이는 것은 아님!
Train model with cross-validation
- 본문에서처럼 아무 모델을 정해서 학습을 시켜가지고 확률값을 구합니다! 여기서는 KNN을 모델로 선택했수다!

- 모델을 학습시킬 때 사용하는 데이터 라벨은 어노테이터들이 라벨링한 거에서 임의로 하나 선택해서 라벨 값으로 지정한거로 사용하는 거였음!!!
- 그냥 랜덤한거 정확도 보면 68퍼, 근데 그 데이터로 cross-val한거는 80퍼! 오~

- 신기한건 true-label로 학습해도 백퍼는 안나오는 구나?

- 그냥 랜덤한거 정확도 보면 68퍼, 근데 그 데이터로 cross-val한거는 80퍼! 오~
- 디테일
- 랜덤하게 하나 고른 거 보이쥬?
- 그래서 만들어진 거 비교하니까 차이 있는거 보이쥬?

- 랜덤하게 하나 고른 거 보이쥬?
Exercise 1: Compute majority-vote consensus labels
-
subtask
- 1: majority-vote 방식으로 consensus label 구한 후에 얼마나 정확한지 확인해봐!
- 2: 이때 뽑힌 라벨들로 knn모델 다시 학습시킨다면 정확도 얼마나오는지 확인!
- 3: annotator들의 quality구해서 누가 최악의 annotator인지 확인해봐!
-
subtask 1:
- cleanlab에 majority-vote 구하는 함수가 있음! 오 그래도 랜덤하게 뽑은건 67퍼 나왔는데 훨씬 높구먼!

- cleanlab에 majority-vote 구하는 함수가 있음! 오 그래도 랜덤하게 뽑은건 67퍼 나왔는데 훨씬 높구먼!
-
subtask 2:
- 모델에 넣어서 뽑은 것도 아주 높구먼?

- 모델에 넣어서 뽑은 것도 아주 높구먼?
-
subtask 3:
- 각 주석자들의 annotation 결과값이랑 majority vote에서 뽑힌 라벨이랑 얼마나 차이가 나는지 정확도 구해서 제일 퀄리티 안좋은 애들 10명 뽑아봄!

- 각 주석자들의 annotation 결과값이랑 majority vote에서 뽑힌 라벨이랑 얼마나 차이가 나는지 정확도 구해서 제일 퀄리티 안좋은 애들 10명 뽑아봄!
Exercise 2: Estimate consensus labels using the CROWDLAB algorithm
https://docs.cleanlab.ai/stable/tutorials/multiannotator.html
-
본문에서 우리는 CROWDLAB 방식을 사용하려면! 모델의 확률값 + 주석자들의 consensus labels 평균값이 필요했음!
-
이것도 cleanlab 함수를 이용하면 그냥 바~로 구해짐!
- 근데 여기서 의문..! 여기서 나온 crowdlab_label가 위의 식을 모두 끝낸 애를 말하는 거임? 그러네! 이미 모델에서 얻은 값이 있으니까 그걸 input으로 같이 넣어주니까 바로 계산 때리는 거구나! 오호오호!

안을 뜯어보자~
대박대박대박!! 각 데이터마다 consensus라벨과 스코어가 나온다!
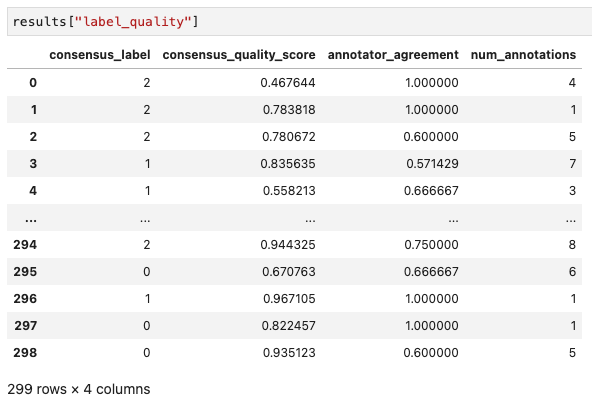
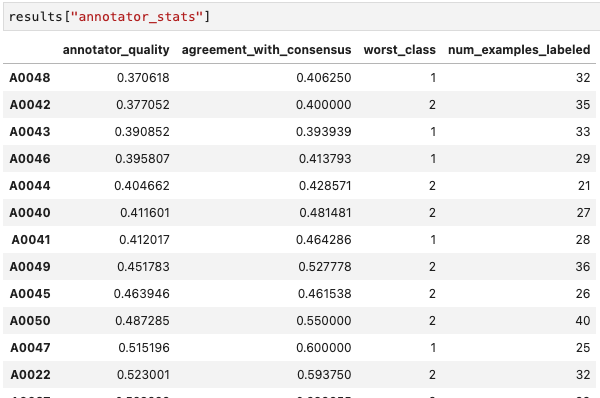
이건 어노테이터들마다 퀄리티 값!
각자 뭘 제일 못했는지도 나오는구만? 신기해!
허거덩~ 정확도를 구해보니 96퍼가 나왔음!! (majority_vote는 82퍼였는데!!!!)
이거를 모델에 넣어보니 거의 true label 넣어서 나온 값 (97퍼)랑 비슷하게 나오네 싄기방기~

- 근데 여기서 의문..! 여기서 나온 crowdlab_label가 위의 식을 모두 끝낸 애를 말하는 거임? 그러네! 이미 모델에서 얻은 값이 있으니까 그걸 input으로 같이 넣어주니까 바로 계산 때리는 거구나! 오호오호!
Review
- 수식이 이번에 많이 나왔는데, 생각보다 인강이 훨씬 더 쉽게 설명해줘서 좋았음!!!!!!
- 우리는 annotator들이 많지 않아서 쓰기에 적합할지 모르겠지만, AI system처럼 annotator Crowd sourcing할 때처럼 대량으로 할때는 아주 좋을 듯!!!!
