paper: https://arxiv.org/pdf/1904.05862.pdf
code: https://github.com/facebookresearch/fairseq
참고 blog: https://asidefine.tistory.com/240
Introduction
-
Challenge:
데이터 부족 -
Goal:
label없는 raw audio로 unsupervised pre-training (최초의 시도인가?! 엄청나군!) -
Approach:
- Unsupervised learning
- a simple multi-layer convolutional neural network
- Contrastive loss that requires distinguishing a true future audio sample from negatives
- move beyond frame-wise phoneme classification and apply the learned representations
-
Result:
- WSJ benchmark
- 1000 hours of unlabeled speech => character-based log-mel filterbank baseline의 WER 감소.
-
Contribution
- easily parallelized over time
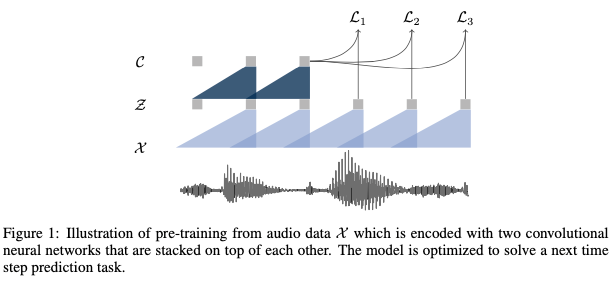
Method
wav2vec1.0 - 2.0의 차이는?
-
기존에 contrastive predictive coding:
바로 다음 sequence랑 가깝게 하는걸로! generative 같은것처럼 비슷한 맥락이군?-
기존 공유벡터에서는 cnn, rnn => cnn, cnn으로 바꿨다.
-
커널을 10씩 옮겨가면서 / 커널의 기준을 뭐로 했지???? raw의 하나하나???
-
공유벡터랑 특징벡터의 차이가 뭔가요??
- positive: 공유- 특징 (다음 단어~?)
- negative: 공유랑 random으로 뽑아서
-
-
wav2vec:
- 10개씩 negative 쌍 뽑아서 평균 내서 로스 줄이는걸로 학습
- 210ms 가 있으면 10씩 옮겨가면서 하나씩 뽑는다? casual cnn?
Experiments
-
data:
- WSJ (월스트릿저널)
-
embedding만 다르게 해서 실험
-
baseline:
- wave2letter: 17층의 gated CNN
-
language model (= decoding model)
: 얘는 아직 End-to-end가 아니구나?logmel filterbank를 모델에서 어디서 사용되는거임? -
ablation
- negative 수: 늘어날 수록 성능은 좋은데 훈련시간이 늘어남
- audio sequence cutting: 어떻게 자르냐에 따라 성능이 다르네, cutting안한게 오히려 성능 떨어짐! 오호
- 미래 예측 step k: 바로 다음꺼로 예측할것이냐? k개의 범위가
그럼 Positive쌍을 k개가 있단건지? 아님 k번째 애랑 한다는 건지?
=> loss k개가 나오고, negative 애들은 평균낸다!
=> casual convolution 1d convolution
- wave2vec 2.0의 등장
- transformer를 사용해서 성능을 높였다.
- masking 작업 포함해서 Masking 예측하는 방식!
Code review
Question
- 어떻게 작동될라나~
- frame-wise phoneme clf는 뭘까나?
- negative 는 뭘로 뒀을라나~

왈왈