
DOM 트리의 탐색
브라우저는 HTML을 읽을 때 각 태그 요소들을 추출해서 나무(트리)형태로 재조립합니다.
그렇게 만들어진 DOM은 나무 형태로 자료구조의 일종인 트리 구조라고 불립니다.
자바스크립트에서는 HTML의 요소를 조작할 때 아주 자주 쓰이는 방법이 있는데
대표적으로 querySelector 또는 getElementByid 가 있습니다.
혹여나 모르시는 분을 위해서 간단하게 설명하자면
예를 들어 만약 html문서 안에 wood라는 class를 가진 노드가 있다면
document.querySelector(".wood");
이렇게 해당 노드를 찾아낼 수 있습니다.
getElementByid 또한 비슷하게 wood라는 id를 가진 노드가 있다면
document.qgetElementByid("wood");
이렇게 찾아낼 수 있습니다.
여기서 class와 id의 가장 큰 차이점은 class는 여러 노드가 동시에 가질 수 있지만
id는 하나의 노드만이 고유하게 가져야한다는 점이 있습니다.
그런데 class가 여러 노드가 가질 수 있다면 과연 querySelector은 그 중 어떤 노드를 찾을 수 있는 걸까요?
아까 말씀드렸다싶이 DOM은 트리 구조이며 그래서 순회 방법 또한 자료구조의 트리구조를 따르는데
이러한 자료구조는 효율적인 탐색 방법이 있습니다.
깊이 우선 탐색과 너비 우선 탐색
트리 자료구조는 불필요한 방문이 없이 최소한의 루트로 가기 위한 방법으로 깊이 우선 탐색과 너비 우선 탐색이 있습니다.
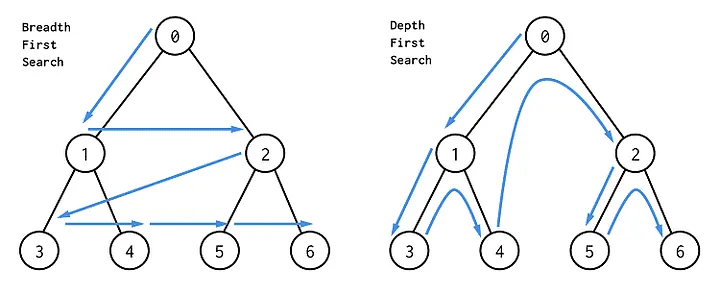
위 이미지와 같은 방법 중에 querySelector, getElementByid는 깊이 우선 탐색을 채택하고 있습니다. 그렇게 탐색을 하다가 첫 번째 노드를 찾아 반환도록 설계 되어 있는데 방문 이력이 없는 노드 중에 가장 처음 해당 노드를 찾게 되면 탐색을 종료하기에 항상 첫 번째 노드가 반환됩니다.
그런데 사실 querySelector는 id도 (#id값)으로 찾을 수 있습니다.
그래서인지 getElementByid와 같은 방식으로 탐색을 수행하는데 왜 굳이getElementByid을 사용하는 걸까라는 생각이 들게 됩니다.
그런데 이러한 깊이 우선 탐색이 시간 복잡도가 최악의 경우엔 모든 노드를 다 방문하기에 결코 빠르다가 볼 수 없는데 getElementByid는 깊이 우선 탐색을 하기 이전에 id와 그의 대응되는 노드가 저장되어 있는 해시 테이블을 사용하기에 찾는 속도가 훨씬 빠릅니다.
그래서 querySelector가 class, id 등등 여러 범용성을 가지고 있지만 시간만 놓고 봤을 땐 getElementByid가 훨씬 좋은 메서드라고 할 수 있습니다.
그렇기 때문에 상황에 맞게 두 메서드 모두 활용하는 것이 좋습니다.
