최근에는 많은 기업과 조직이 MSA형식으로 애플리케이션을 개발한다.
하지만 MSA 형식으로 개발한다면, 여러 분산된 서버들이 어떻게 동작하는지 한 눈에 살펴보기 어렵고, 전체 구조를 추적하기 어렵다.
Pinpoint : 분산추적
네이버에서 만든 오픈소스 APM(애플리케이션 성능 모니터링)이다.
애플리케이션을 위한 모니터링 도구로, 서버의 트래픽 증가 등으로 인한 성능 감소, 병목 현상을 해결하기 위해 서버를 추적하여 확인할 수 있다.
특히, 분산 추적에 용이한 툴이다.
저장소는 HBase를 사용한다.
Hadoop의 HDFS위에 만들어진 분산 컬럼 기반의 비관계형 데이터베이스이다.
HBase의 Rowkey를 맞게 설계하면 데이터를 효율적으로 가져올 수 있다.
ex) 애플리케이션 이름 + 시간의 조합
Pinpoint 깃허브
https://github.com/pinpoint-apm/pinpoint
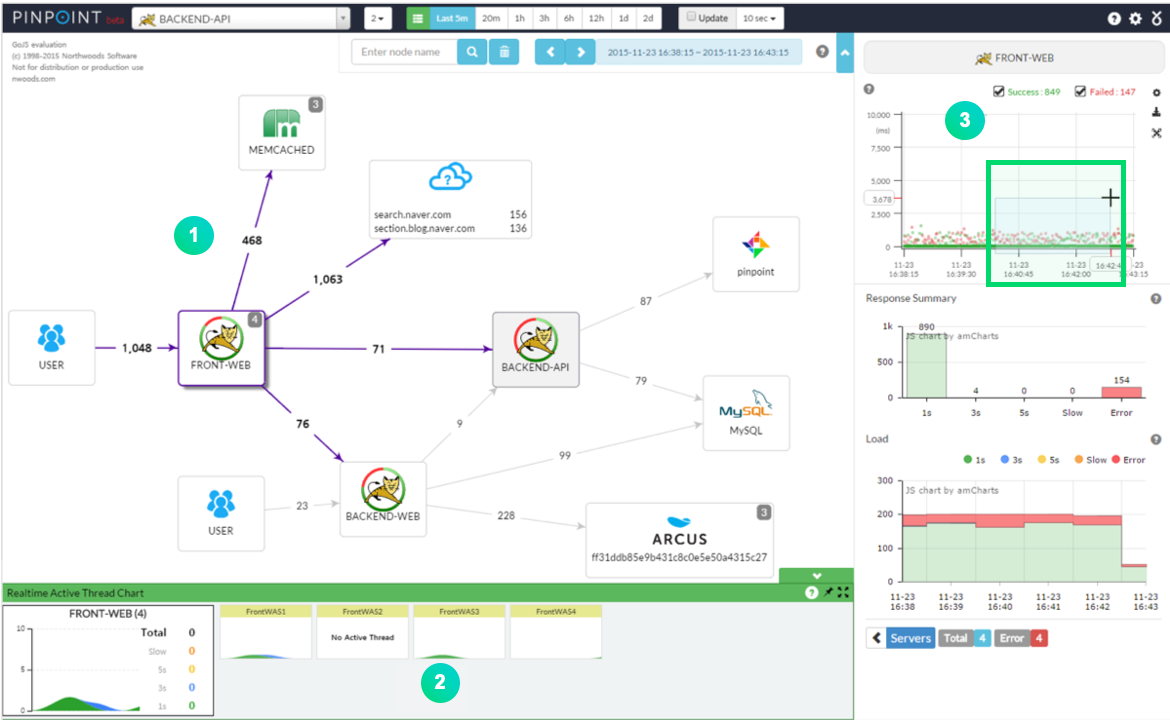
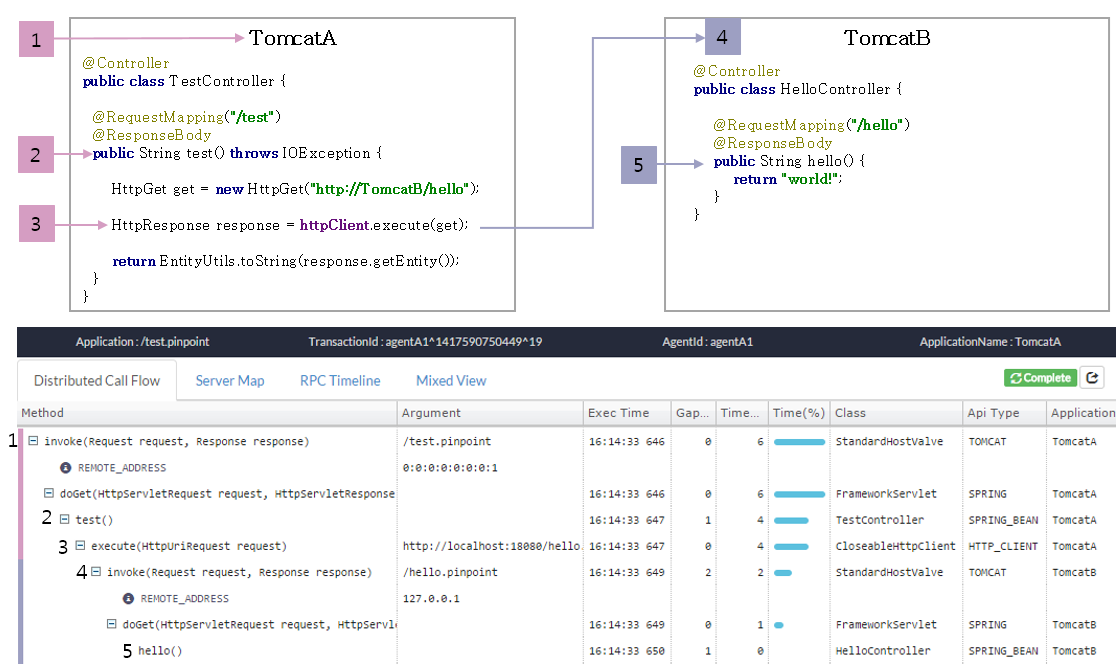
출처 https://d2.naver.com/helloworld/1194202
위와 같이 서비스 내의 요청과 정보를 확인해볼 수 있다.
이를 통해 유저가 어느 서비스에서 요청을 못 받았는지, 또는 어디서 지연이 됐는지 확인할 수 있다.
Scatter Chart
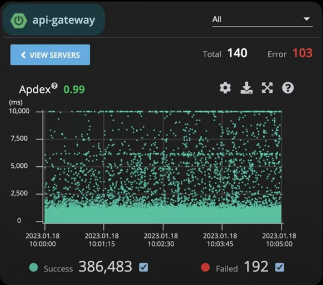
PinPoint에서 확인할 수 있는 Scatter Chart이다.
해당 점은 외부에서 들어온 서비스 요청을 뜻한다.
각 점을 선택하면 시작 시간, Path, IP, TransactionID등 정보를 볼 수 있다.
Rowkey를 적절하게 설계했다면, 효율적으로 많은 데이터를 가져올 수 있다.
테이블에는 두 가지의 ColumnFamily가 있다.
1. Index ColumnFamily
ScatterChart에서 점을 표현할 수 있는 정보를 가지고 있다. 이를 이용하여 Scatter Chart를 그리게 된다.
2. Meta Column Family
각 요청에 대한 정보들을 모아놓는다.
TransactionId는 요청을 받은 ApiGatway에서 만든다.
이 요청에 의해서 파생된 요청은 동일한 TransactionId를 가지게 된다.
TransactionId는 Meta ColumnFamily의 Qualifer에 TransactionId를 저장한다.
이 TransactionId를 통해서 특정 시간의 요청을 조회하고, 동일한 TransactionId를 기준으로 유저 서비스가 호출된 요청을 찾아낼 수 있다.
이를 이용해서 요청 중간에 불필요한 요청을 추적하여 불필요한 시간을 줄일 수 있다.
비동기 방식 처리
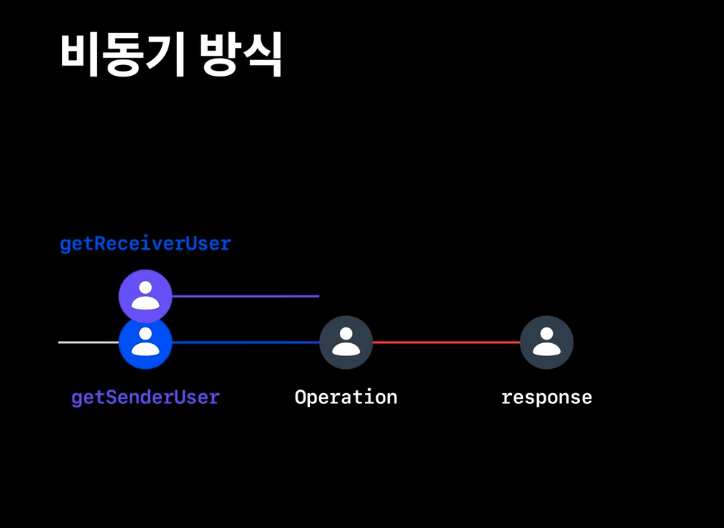
서버의 요청을 동기 방식으로 처리하는 것 보다, 비동기 방식으로 처리해서 서버에 머무르는 시간을 줄일 수 있고, 동시에 여러 연산을 처리할 수 있다.
이의 경우는 해당 요청이 동기 방식을 통해서 데이터의 return이 필요한지, 확인 과정을 거쳐야 하는지 판단해서 처리하는 것이 좋을 것이다.
코틀린의 경우, Coroutine을 이용해서 효율적인 비동기 방식의 요청을 할 수 있다.

https://developer.android.com/kotlin/coroutines?hl=ko
발표에선 코루틴이 PinPoint가 코루틴을 지원하지 않기 때문에, AsyncRestTemplate라이브러리와 ListenableFuture를 연결시켜 플러그인을 만들었지만, Spring 5.0 버전에서부턴 AsyncRestTemplate를 지원하지 않는다.
따라서, WebClient를 통해 비동기 REST 를 보내는 예제를 살펴보자.
import org.springframework.http.HttpMethod;
import org.springframework.web.reactive.function.client.WebClient;
import reactor.core.publisher.Mono;
public class MyAsyncRestClient {
WebClient client = WebClient.create();
// 비동기 GET 요청 보내기
Mono<String> responseMono = client
.method(HttpMethod.GET)
.uri("https://api.example.com/data")
.retrieve()
.bodyToMono(String.class);
// 비동기 응답 처리
responseMono.subscribe(
response -> {
// 응답 받은 데이터 처리
System.out.println(response);
},
error -> {
// 오류 처리
System.err.println("Error: " + error.getMessage());
}
);
}
Web Client를 이용하여 비동기 요청을 구성하고, subscribe 메서드를 통해 비동기 응답을 처리할 수 있다.
스레드 풀 Thread Pool
스프링 내부에서는 스레드 풀(Thread Pool)을 사용하여 비동기 처리와 관련된 작업을 수행한다.
스레드 풀을 이용해서 스레드를 관리하고 재사용하여 성능을 향상시킬 수 있다.
스프링에서 제공하는 TaskExcutor 인터페이스를 이용하여 태스크들을 비동기적으로 실행할 수 있다.
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
@Configuration
@EnableAsync //비동기 작업 수행 설정
public class AppConfig {
@Bean
public ThreadPoolTaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(10); //Core Pool Size 조절
executor.setMaxPoolSize(50); //Max Pool Size 조절
executor.setQueueCapacity(100); //Queue 용량 조절
executor.setThreadNamePrefix("ThreadPool-"); //스레드 접두사
executor.initialize();
return executor;
}
}
@EnableAsync 어노테이션을 통해서 비동기 작업이 사용될 수 있도록 설정하고,
@Async 어노테이션을 이용하여 비동기적으로 실행되는 메서드를 지정할 수 있다.
이렇게 직접 설정해줄 수 있지만, 스프링 부트는 기본적으로 스레드 풀을 기본적으로 제공한다.
- properties
# 코어 스레드 수
spring.task.execution.pool.core-size=10
# 최대 스레드 수
spring.task.execution.pool.max-size=50
# 작업 큐 용량
spring.task.execution.pool.queue-capacity=100
# 스레드 이름 접두사
spring.task.execution.pool.thread-name-prefix=MyThreadPool-
- yml
spring:
task:
execution:
pool:
core-size: 10
max-size: 50
queue-capacity: 100
thread-name-prefix: ThreadPool-
- core size : 풀 내에서 항상 유지되는 최소 스레드 수
- max-size : 풀이 동시에 가질 수 있는 최대 스레드 수
- queue-capacity : 대기열에 저장할 수 있는 작업의 최대 개수
- thread-name-prefix : 생성된 스레드 이름의 접두사
스프링 부트는 기본적으로 스레드 풀을 지원하기 때문에, 이와 같이 스레드 풀을 설정해서 사용할 수도 있다.
