개발 배경
현재 진행중인 업무에 선착순으로 유저들의 응모를 받아야하는 기능이 필요했다. 이를 위해 정말 단순한 생각으로 이 시스템을 개발했다가, 제한 인원보다 더 많은 인원이 응모되는 사고를 치게 됐다. 그 당시 내가 만든 구조는 다음과 같다.
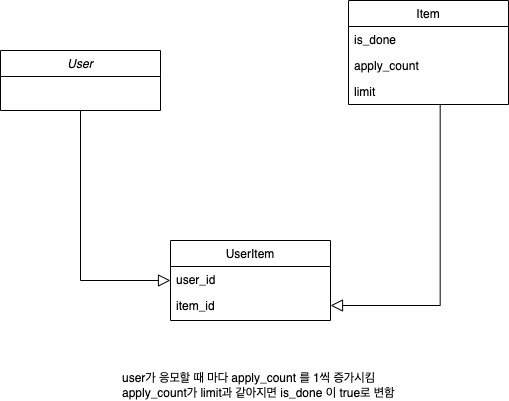
- user가 응모할 대상이 되는 item 테이블에 applyCount / limit / isDone 라는 컬럼을 추가
- user와 item 의 관계 테이블 생성 (user_item), 한 user가 하나의 item에 중복 신청하는 것을 막기 위해 user_id / item_id 에 unique constraint 설정
- user가 응모 API에 접근시 각종 검증 로직 진행
- 관계 테이블을 조회하여 중복 응모 여부 체크
- item 테이블을 조회하여 isDone 여부 체크
- 검증에 문제가 없다면 item의 applyCount를 1 증가시킴,
- 만약 applyCount를 1 증가시켰을 때 limit에 도달한다면 isDone을 true로 변경
- user_item 관계 테이블에 등록
당시 작성한 코드는 아래와 같다.
@Transactional
fun applyByItemId(itemId: Long, user: User): UserItem {
// 응모하려고 하는 대상 조회
val item = readItemById(itemId)
// 중복 응모 / 마감 여부 검증
val alreadyApplied = userItemRepo.findByUserAndItemId(user, item.id)
if (alreadyApplied != null) throw DuplicatedException("The user is already applied to this item")
if (item.isDone) throw WrongStatusException("The item is already done")
// 아이템 <> 유저 관계 테이블에 등록
val now = LocalDateTime.now()
val applied = userItemRepo.save(
UserItem(
item = item,
user = user,
createdAt = now, updatedAt = now
)
)
//
// 해당 아이템의 참가자수 + 1 (마감되면 상태를 마감으로 변경)
val editedItem = item.applyCount.let {
when {
// 마감 직전이면 -> 상태를 isDone으로 변경
(it == (item.limit - 1)) -> {
val applyCount = item.applyCount + 1
repo.save(item.copy(
applyCount = item.applyCount + 1,
isDone = true,
ratio = (applyCount.toDouble()/item.limit.toDouble())
))
}
// 마감 직전이 아니면 applyCount 만 1씩 증가 시킴
else -> {
val applyCount = item.applyCount + 1
repo.save(item.copy(
applyCount = item.applyCount + 1,
ratio = (applyCount.toDouble()/preOrder.limit.toDouble())
))
}
}
}
return applied
내가 기대한 작동 로직은 다음과 같이 정리 할 수 있다.
궁극 적으로 내가 기대한대로 작동한다면 ,
아래의 테이블 예시와 같이 UserItem 테이블의 특정 item_id를 갖는 모든 행의 갯수는 해당 Item의 limit 값과 동일했어야 한다 !!
-
기대했던 UserItem 테이블
user_id item_id 1 1 2 1 3 1 4 1 1 2 2 2 -
기대했던 Item 테이블
id is_done apply_count limit 1 true 4 4 2 true 2 2
하지만 실제 상용 환경에서의 결과 값과는 기대한바와 다르게 작동했다.
-
실제 작동한 UserItem 테이블
user_id item_id 1 1 2 1 3 1 4 1 5 1 6 1 7 1 1 2 2 2 3 2 4 2 5 2 -
실제 작동한 Item 테이블
id is_done apply_count limit 1 true 4 4 2 true 2 2
item_id 1에 대해 4개의 행이 UserItem 테이블에 등록되었다면, apply_count는 4가되어, is_done 플래그를 true로 바꾸고 user_id 5번 이후의 유저의 응모에 대해서는 WrongStatusException를 리턴했어야 하는데, 그러지 못하고 모든 응모를 다 받아버린 것이다.
선착순 처리의 어려움을 알게 된 나는 부랴부랴 해법을 찾기 시작했다.
왜 이런일이 일어난걸까?
당시 이 서버는 선착순 이벤트를 대비하며 4개의 인스턴스를 띄워놨고, AutoScailing에 의해 최대 12개 까지 증가될 수 있도록 설정해두었다.
그리고 각각의 인스턴스는 내장 서블릿 컨테이너인 TomCat에 의해 최대 200 ~ 최소 10개의 쓰레드풀을 유지하며 다중 요청을 처리하고있다.
// org/springframework/boot/autoconfigure/web/ServerProperties.java
/**
* Tomcat thread properties.
*/
public static class Threads {
/**
* Maximum amount of worker threads.
*/
private int max = 200;
/**
* Minimum amount of worker threads.
*/
private int minSpare = 10;
...
}즉 단순히 계산한다면, AWS에서 서버가 돌면서 동시에 처리할 수 있는 요청은 최대 12개 인스턴스 * 200 = 2400개인 것이다.
이 때 별도의 처리 없이 다중 스레드/여러 인스턴스에서 동시에 하나의 DB에 접근하게 되면, 자연스레 경쟁상태가 발생하고, 데이터의 원자성이 깨지게 된다.
그림으로 표현하면 다음과 같다.
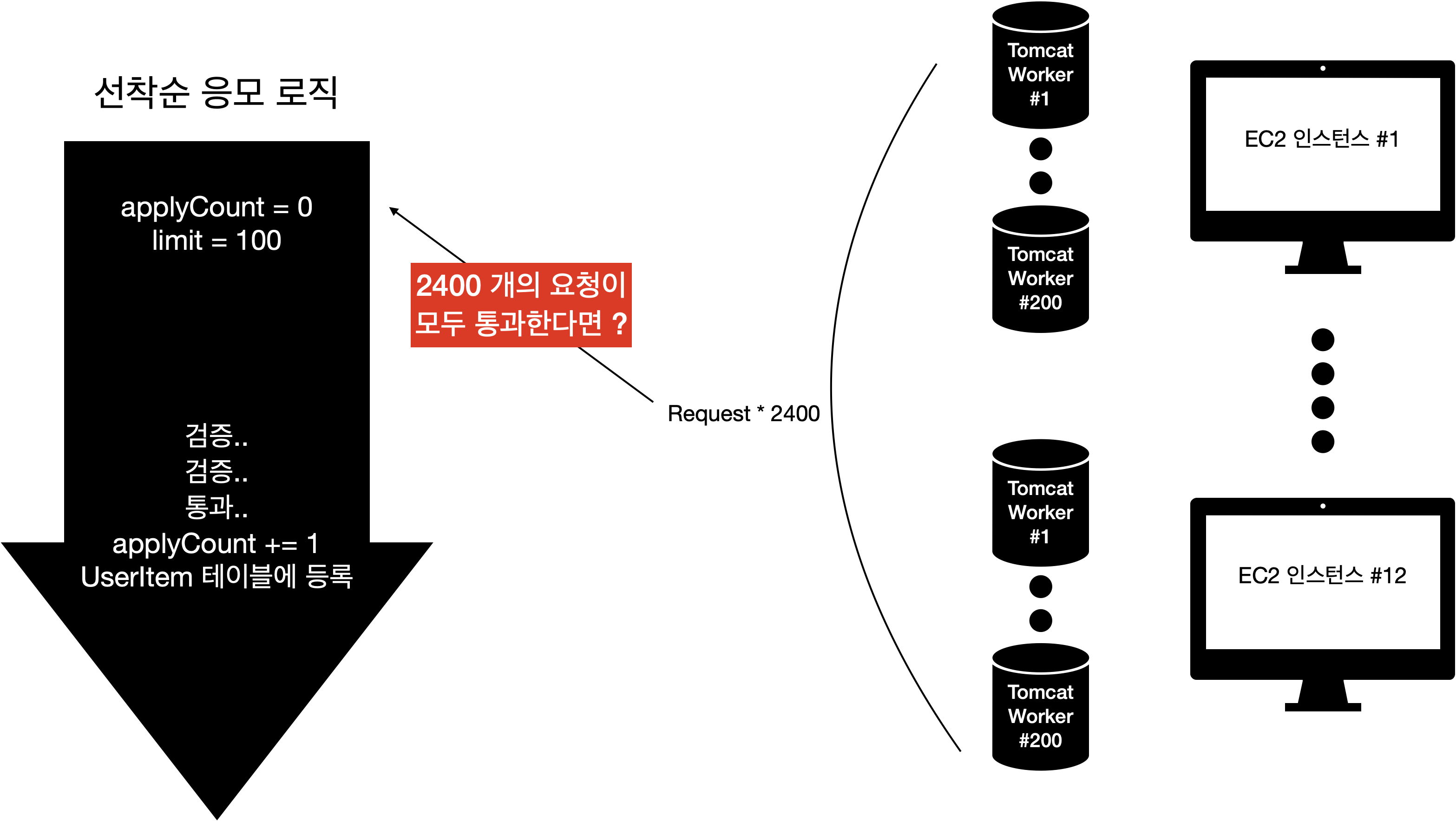
동시에 100개 이상의 요청이 오는 상황을 가정해보자.
요청"들"이 왔을 때 applyCount는 0일 것이고, 모든 요청들이 검증을 통과하여 UserItem 테이블에 등록될 것이다.
이처럼 여러 스레드/프로세스에서 하나의 데이터를 가지고 작업을 할때 결과값이 기대한 바와 다른 원인은 "경쟁상태"에서 기인한다.
결국 1번의 apply에서는
- item의 applyCount 를 1 증가시키고, isDone 여부 체크
- UserItem 테이블에 등록
두 작업이 각각 1번 진행되어야 하지만,
경쟁상태가 발생하여 item이 isDone이 되기 전에 요청된 건들에 대해 모두 UserItem 테이블에 등록되지만,
Item 테이블의 applyCount는 limit이 되면 isDone = true 로 만들기 때문에, 실제 등록된 UserItem의 갯수보다 적어지는 것이다.
해결방법
결국 다중요청시에도 데이터의 원자성을 지키기 위해, 경쟁상태가 일어나지 않도록 해야한다.
이를 위해서는 아무리 많은 요청이 동시에 오더라도, 선착순 응모 로직은 동시에 1개의 요청만 처리할 수 있도록 해줘야한다. 그렇지 않으면 결국 경쟁상태가 발생하고 데이터의 원자성이 꺠지기 떄문에다.
나는 redis를 통한 distributed lock을 도입하여 이 문제를 해결했다.
분산락(Distributed Lock)이란
- 여러 프로세스가 공유되는 하나의 자원을 다루는데, 상호 배타적으로 이를 처리해야하는 경우 (applyCount/limit/isDone 프로세스 처럼 동시에 공유되는 데이터를 처리해야하는 경우)
- 특정 순간에 "한 클라이언트에게만" 락 권한을 주고, 락이 없는 다른 클라이언트의 접근은 락을 가지고있는 한 클라이언트가 락을 반환할 때 까지 접근을 막는 개념
분산락에 대해서는 다음의 블로그에서 자세히 설명되어있다. 링크
kotlin을 사용한 spring boot 환경 셋팅
준비물은 다음과 같다.
- 단일 redis 인스턴스 => aws elasticache 사용 (redis 인스턴스가 다중인스턴스로 돈다면, 상호 배제성의 락을 구현하기 어려워진다.)
- spring boot 환경에서 redis를 다룰 수 있는 클라이언트 => redisson client 사용
아래와 같이 spring boot 에서 설정해주었다.
# application.yml
spring:
redis:
host: localhost # elasticache의 redis 인스턴스 엔드포인트
port: 6379// build. gradle.kts
dependencies {
...
implementation("org.redisson:redisson-spring-boot-starter:3.16.4")
...
}redisson client 로 분산락 걸기
import org.springframework.stereotype.Service
import org.redisson.api.RLock
import org.redisson.api.RedissonClient
@Service
class ItemService(
// 의존성 주입
private val repo: PreOrderRepository,
private val redissonClient: RedissonClient,
private val transactionManager: PlatformTransactionManager,
)
{
fun applyByItemId(itemId: Long, user: User): UserItem {
// itemId를 키로 하는 Lock을 조회
val lock: RLock = redissonClient.getLock("$itemId")
// 5초간 Lock 획득을 시도한다. 그 Lock을 획득하면 6초간 Lock을 유지하게 된다.
val isLocked = lock.tryLock(5, 6, TimeUnit.SECONDS)
// @Transactional 대신 코드내에서 직접 트랜잭션 관리
val status = transactionManager.getTransaction(DefaultTransactionDefinition())
try {
// Lock 획득에 실패한 경우이다. 5초 이상 기다렸는데 앞사람들의 작업이 끝나지 않았다면 이 로직이 수행될 것이다.
if (!isLocked) {
throw MsgException("failed to get RLock")
}
try {
/*
/* ...
/* ...
/* 비즈니스 로직 수행
/* ...
/* ...
*/
// 성공적으로 비즈니스 로직이 수행됐다면 트랜잭션을 커밋해준다.
transactionManager.commit(status)
return 응모정보
} catch (e: RuntimeException) {
// 비즈니스 로직 수행중 예외가 발생한 경우 트랜잭션을 롤백해준다.
transactionManager.rollback(status)
throw Exception(e.message.toString())
}
} catch (e: InterruptedException) {
// 쓰레드가 작동전 interrupt 될 경우에 대한 예외처리
throw Exception("Thread Interrupted")
} finally {
// 로직 수행 후 Lock을 반환한다. 다만 Lock의 주체가 이 로직을 호출한 쓰레드일 경우에만 반환할 수 있다.
if (lock.isLocked && lock.isHeldByCurrentThread) {
lock.unlock();
}
}
}
}
Check Point
1. 트랜잭션을 왜 직접관리 하는지?
- 주의해야할 점은 Distributed Lock과 @Transational은 동시 작동하지 않는다. (출처)
- 테스트 결과 RuntimeException에도 @Transactional 이 롤백을 해주지 않아, 첮아보니 Redisson 을 활용해 분산락을 적용하는 경우 직접 트랜잭션을 관리해줘야 한다고 한다.
- 에러 처리와 롤백, 커밋 타이밍등을 신경써서 코딩해주자.
2. tryLock 메서드의 역할는?
- 최대 수천개의 동시발생한 Request를 redisson이 Lock을 걸어줘, 동시에 1개만 처리하도록 해놨다.
- 그렇다면 가장 먼저 Lock을 획득한 쓰레드외에 나머지 쓰레드는 해당 비즈니스 로직을 수행할 권한을 얻지 못한다.
- 하지만 선착순인경우 가능한 "비교적 먼저온 유저"에게 Lock을 획득할 수 있도록 해주어야 한다.
- Redisson 클라이언트는 pub-sub 구조로 Lock 획득에 대한 대기열을 관리한다.
- 먼저 요청한 순서대로 pub queue에 들어오고, 앞서 Lock을 획득한 쓰레드가 Lock을 반환하면 sub queue에서 pub queue에서 대기중인 쓰레드를 꺼내와 Lock을 획득하도록 해준다.
- 그렇다면, 동시에 요청을 받은 쓰레드들은 Lock 획득을 위해 얼마나 기다려야 할까? 무한정 기다리다가는 교착상태에 빠질 수있다.
- 그렇다고 너무 짧게 기다린다면 앞선 쓰레드의 처리를 기다리다 timeout될 수 있고, 나보다 늦게 요청을 받은 쓰레드가 Lock을 획득하게 될 수 있다.
- 따라서 서비스 로직과 예상되는 트래픽에 따라 적절한 waitTime을 지정해주어야 하는데, 여러차례 테스트 결과 5초로 설정하는 것이 가장 효율적으로 판단되었다.
- 또한 Lock을 획득한 쓰레드는 최대 6초동안 그 Lock을 유지할 권한을 갖도록 leaseTime을 설정했다. 상기한 비즈니스 로직을 6초 이내에 수행하지 못한다면 timeOut을 발생시키고, transactionManager에 의해 트랜잭션은 롤백된다.
- 이또한 예기치 못한 오류로 무한정 로직을 끝마치지 못마칠 경우 교착상태에 빠지는 것을 방지하기 위해 설정해둔 수치이다.
Test
@SpringBootTest
@AutoConfigureMockMvc
class ApplyServiceTest
@Autowired constructor(
private val applyService: ApplyService
) {
@Test
@Throws(InterruptedException::class)
fun testCounterWithConcurrency() {
val numberOfThreads = 100
val service = Executors.newFixedThreadPool(100)
for (i in 0 until numberOfThreads) {
val user = User(
id = 66000L + i,
couponCount = 1000,
email = "{${genRandomString(12)}}@asd.asd"
)
service.execute {
applyService.applyByItemId(itemId = 633, user = user)
}
}
Thread.sleep(1000)
}
private fun genRandomString(length: Int): String {
val charPool : List<Char> = ('a'..'z') + ('A'..'Z') + ('0'..'9')
return (1..length).map { kotlin.random.Random.nextInt(0, charPool.size) }
.map(charPool::get)
.joinToString("")
}
}- 100 개의 쓰레드로 가짜 유저를 만들어내 633번의 item에 선착순 응모하는 테스트 코드이다.
- 테스트 결과 15개의 입력이 수행됐고, 그 이후부터는 Lock 획득 실패 및, Redisson is shutdown 이라는 에러가 발생하며 수행되지 않았다.
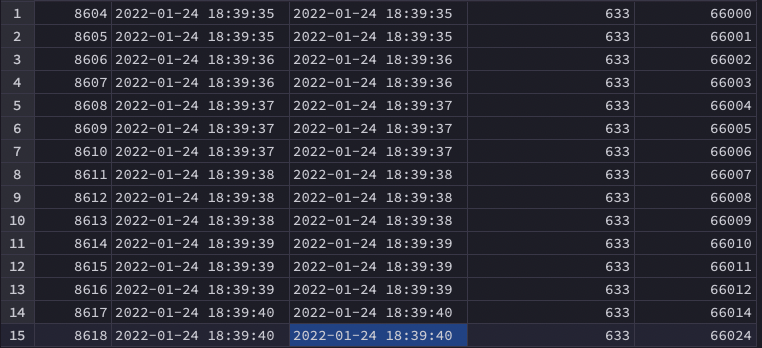
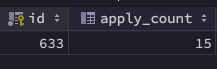
- 기존 코드였다면, 15개의 입력이 경쟁상태에 빠져 apply_count가 15개 미만으로 기록되었을 텐데, 수치를 맞춰 데이터의 원자성 확보에는 성공했다.
- 다만 100개의 요청에 100개의 입력 모두를 받을 수 있도록 해야하는데, Lock 획득 실패는 그렇다 쳐도 / Redisson is shutdown 이 발생하는 이유는 아직 찾지 못했다. 🥲🥲🥲🥲🥲🥲
- 원인을 찾고 수정하여 더 깔끔한 코드로 완성시키면 다시 업데이트 할 계획이다.. !!!!
결론
멀티쓰레드/프로세스에서 하나의 데이터를 처리하는 경우 필연척으로 경쟁상태에 빠져 원자성을 보장할 수 없다. 선착순이나 장바구니 등 한정된 자원을 처리해야하는 로직에서 문제가 발생할 수 있다. 이때 효율적으로 원자성을 보장하는 방법으로 redis 를 활용한 분산락을 도입했고, 원자성을 지킨채 선착순 로직을 성공적으로 서빙할 수 있었다.
하지만 여러 셋팅값등의 문제로 100개의 동시 요청에 100개의 결과 모두를 수행하는데에는 실패했다. 좀 더 공부하고 코드를 다듬어 100개의 요청 모두 문제없이 받을 수 있는 상태로 업데이트 해볼 계획이다.
Fast API로도 같은 기능을 구현해봐야겠다.
그럼이만
