페이징 성능 테스트
개요
product 검색 기능을 개발 중에 검색된 많은 product 데이터를 페이징 해야 할 일이 생겨서
대용량 데이터들은 어떤 식으로 페이징해야 좋은 성능을 낼 수 있을지 궁금해서 직접 테스트해 보기로 했다.
그중에서 가장 잘 알려진 3가지 방법(offset, no-offset, covering-index)의 페이징 방법을 테스트해 보자.
성능 테스트 데이터
product 테이블에 6700만 건 제품 데이터를 간단하게 Like로 필터링한 후 데이터를 페이징해보자
명확하게 차이를 보기 위해 6700만 건 중 검색 데이터를 약 40만 개를 페이징 하는 것으로 테스트 진행하였음
1. offset 방식
Offset 방식은 흔히들 알고 있는 LIMIT , OFFSET 키워드를 이용한 방식이다.
Offset 쿼리는 이러한 방식으로 동작한다.
- LIMIT 10 OFFSET 1000 -> 1,000개의 row를 읽고 그중에서 990개를 버리고 10개를 사용
- LIMIT 10 OFFSET 10000000 -> 10,000,000개의 row를 읽고 그중에서 9,999,990개를 버리고 10개를 사용
여기서 볼 수 있듯이 고작 10개를 페이징해서 사용하기 위해 나머지 9,999,990개의 데이터를 버리는 식의 비효율적 동작을 하는 것을 알 수 있다.
따라서 OFFSET이 커질수록 더 많은 데이터를 읽고 많이 버려야 하므로 속도가 느려질 수밖에 없다.
SELECT * FROM products
WHERE product_name LIKE 'a%'
ORDER BY product_no DESC
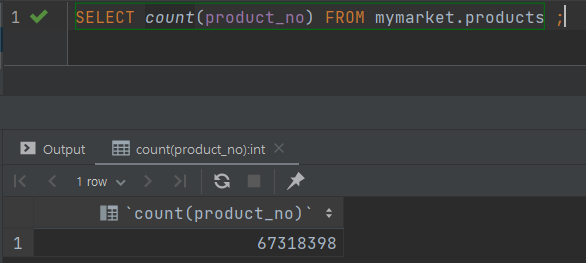
LIMIT 10 OFFSET 100000;결과
- product_name_idx 사용을 강제 하도록 한뒤에 테스트 진행
- Offset 방식의 페이징 결과를 살펴보면 평균적으로 쿼리 시간이 20m 이상으로 아주 오래걸리는 것을 알수 있다.
실행계획

- index-condition-pushdown으로 데이터를 조회한 후 filesort로 order by를 진행한다.
2. no-offset 방식
no-offset 방식은 위의 방법과 달리 OFFSET 키워드를 사용하지 않는 방식을 말한다.
예를 들면 이전 페이징 한 값 중에 가장 마지막 값인 product_no(10인 경우)를 다음 페이지에서는 product_no(10) 이후의 데이터 중에서 10개를 가져오는 방식으로 진행된다.
따라서 Offset 방식처럼 전체 데이터를 읽으면서 페이징 할 필요가 없어 속도가 매우 빠르다.
하지만 no-offset 방식은 사용할 수 있는 특정 조건이 있는데 그 이유가 다른 페이징과는 달리 이전 페이지의 값을 기준으로 페이징하기 때문에 특정 페이지로 넘어갈 수 없다.
따라서 무한 scroll 형태나 more 버튼 이 있는 형태로 페이징을 사용할 때만 사용할 수 있다.
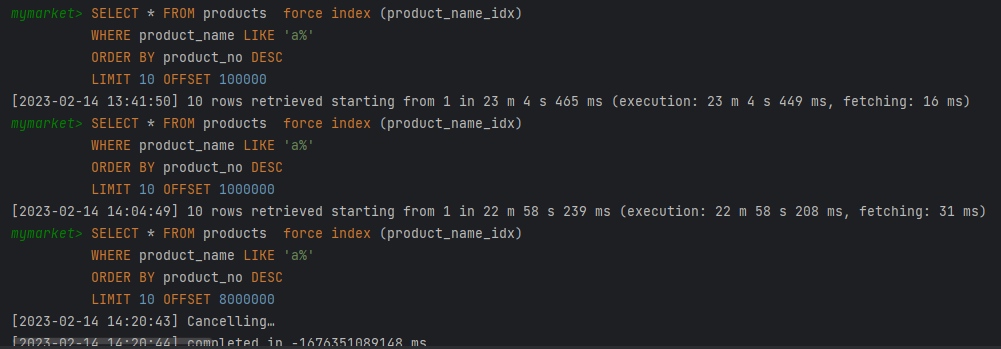
SELECT * FROM products
WHERE product_no < {이전 페이지 마지막 product_no}
AND product_name LIKE 'a%'
ORDER BY product_no DESC
LIMIT 10;결과
- no-offset 방식은 현재 쿼리에서 product_no(PK)가 이전 페이지의 마지막 PK 값보다 작은 값 들 중 10개를 select 해서 바로 리턴하기 때문에 매우 빠른 것을 확인할 수 있다. 평균 30ms 내외
실행계획

- 1964448 만개의 데이터를 가져와서 product_name LIKE 'a0%'로 필터링하는 경우 대략 12.08% 정도가 일치 할 것으로 실행계획을 통해서 예상 할수있다.
(이 값은 정확하지는 않다.)
-> Limit: 10 row(s) (actual time=0.046..0.117 rows=10 loops=1)
-> Filter: ((products.product_no < 1000000) and (products.product_name like 'a%')) (cost=398111.62 rows=237337) (actual time=0.045..0.116 rows=10 loops=1)
-> Index range scan on products using PRIMARY (cost=398111.62 rows=1964448) (actual time=0.015..0.104 rows=133 loops=1)- 실제로는 각단계에서 다음과 같이 측정되었다.
-> Filter: 예측치 rows=237337 | 실제 rows=10
-> (PK)Index range scan : 예측치 | rows=1964448 실제 rows=133
3. covering-index 방식
먼저 covering-index가 무엇인지 알아보자
covering-index란?
covering-index는 SELECT / WHERE / GROUP BY / ORDER BY에 사용되는 컬럼이 모두 인덱스일 때 효율적으로 탐색하는 방법을 말한다.
BTree는 구조상 이런 식으로 조회가 된다.
root 노드 -> ...Branch... -> leaf 노드
이때 leaf 노드에 실제로 데이터가 존재하는데
covering-index는 가장 첫 부분인 index만 조회하고 실제 데이터는 조회하지 않는다.
따라서 BTree의 leaf 노드인 데이터를 조회하지 않고 해당 index만 조회하기 때문에 LIMIT - OFFSET을 쓰더라도 index만 조회하기 때문에 더 빠르게 select 할 수 있는 것이다.
하지만 covering-index 방식도 offset 방식처럼 offset을 사용하기 때문에 뒤로 갈수록 속도가 느려진다.
(offset 방식보다는 덜하다.)
또한 실제 로직에서는 like 외에도 where 절에 여러 가지 필터링하는 칼럼들이 생기는데 이를 모두 index로 지정해야 covering-index가 되기 때문에 인덱스의 크기가 비대해진다는 점이 단점이다.
SELECT *
FROM products as p
JOIN (SELECT product_no
FROM products
WHERE product_name LIKE 'a%'
ORDER BY product_no DESC
LIMIT 10
OFFSET 100000
) as pt on p.product_no=pt.product_no결과
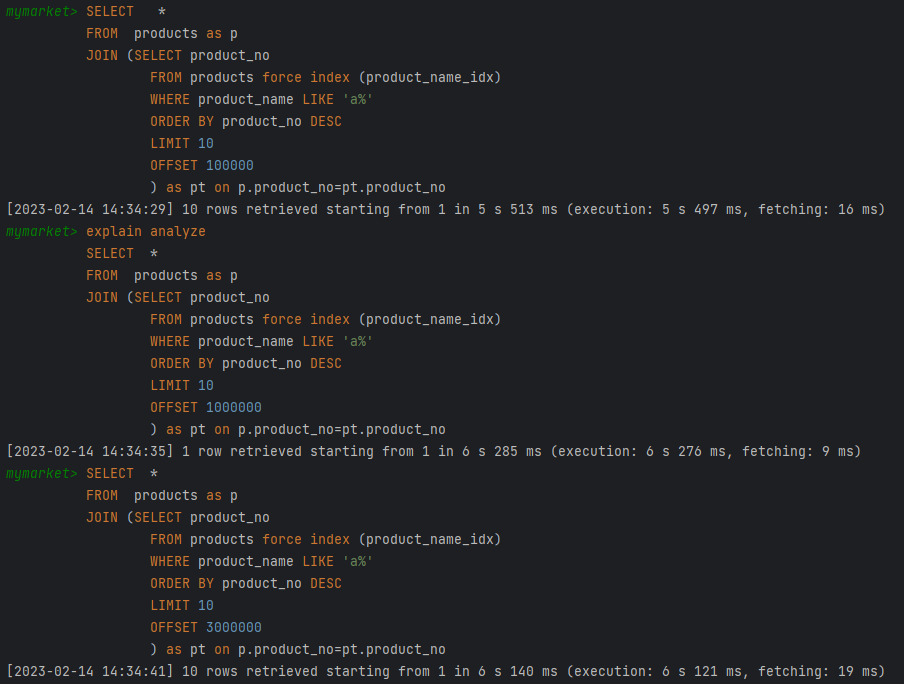
- subquery로 pk인 product_no만 조회하고(covering-index) 이를 products table에 self join 해서 속도를 증가시킨다.
실행계획

- 커버링 인덱스를 구하는 데이터는 서브쿼리로 파생테이블이 만들어진다. 실제 쿼리가 실행되는순서는 다음과 같다.
8번 -> Nested loop inner join (actual time=5857.306..5857.460 rows=10 loops=1)
6번 -> Table scan on pt (actual time=0.001..0.002 rows=10 loops=1)
5번 -> Materialize (actual time=5856.274..5856.276 rows=10 loops=1)
4번 -> Limit/Offset: 10/100000 row(s) (actual time=5856.258..5856.259 rows=10 loops=1)
3번 -> Sort: products.product_no DESC, limit input to 100010 row(s) per chunk (cost=1996232.63 rows=8063538) (actual time=5849.450..5853.619 rows=100010 loops=1)
2번 -> Filter: (products.product_name like 'a%') (actual time=0.045..4664.499 rows=4206750 loops=1)
1번 -> Index range scan on products using product_name_idx (actual time=0.043..4382.446 rows=4206750 loops=1)
7번 -> Single-row index lookup on p using PRIMARY (product_no=pt.product_no) (cost=1.00 rows=1) (actual time=0.118..0.118 rows=1 loops=10)
해석
-
name_idx index로 products 테이블에 대한 index range scan : 이 단계는 제품 테이블의 name_idx index를 scan하여 쿼리에 지정된 필터 조건과 일치하는 행을 찾는다.
여기서 product_name 열은 "a"로 시작
실제 rows의 수는 4206750개 이다. -
Filter: 이 단계는 쿼리에 지정된 조건을 기반으로 1단계에서 반환된 행을 필터링한다.
여기서 product_name 열은 "a"로 시작 -
정렬: 이 단계는 2단계의 결과를 다음과 같이 정렬한다.
product_no 열을 내림차순으로 표시하고 input 청크당 100,010개 행으로 제한합니다.
실행계획 예측 rows=8063538 실제 rows=100010 -
Limit/Offset 10/100000 row(s) : 이 단계에서는 반환되는 행 수를 100,000번째 행부터 시작하여 10개로 제한한다.
-
구체화: 이 단계는 이전 단계의 결과를 보관할 임시 테이블을 생성하는 단계이다.
-
pt에 대한 table scan : 이 단계는 "pt" 테이블을 full table scan을 수행하고 최대 10개의 행을 반환한다.
-
PRIMARY를 사용하여 "p" 테이블에 대한 단일 행 인덱스 조회: 이 단계에서는 pk를 사용하여 제품 테이블의 "pt" 테이블의 product_no 열과 일치하는 행을 검색합니다.
참고로 6단계에서 반환되는 각 행에 대해 수행된다. -
Nested loop inner join: 6단계와 7단계의 결과를 결합하는 데 사용된다.
6단계의 결과를 가져오고 각 행에 대해 인덱스를 사용하여 products 테이블(7단계)에서 일치하는 행을 찾아서 반환한다.
쿼리 속도 결과
no-offset 모든 쿼리의 속도가 일정하기 때문에 비교하기는 무리가 있지만 그래도 비교해보자면 아래와 같다.
no-offset > covering-index >>>> offset
| 비고 | 1차 100000 ~ | 2차 1000000 ~ | 3차 3000000 |
|---|---|---|---|
| offset | 23m 4s 449ms | 22m 58s 208ms | 측정x |
| covering-index | 5s 497ms | 6s 285ms | 6s 140ms |
| no-offset | 26ms | 32ms | 34ms |
