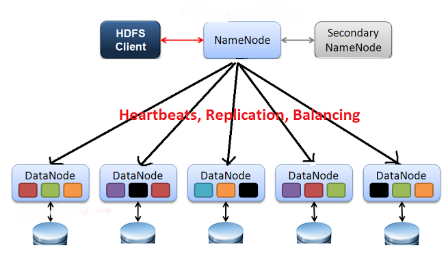
HDFS
- HDFS는 Hadoop Distributed File System의 약자이다.
- 배치처리를 위해 설계되었기에 빠른 데이터 응답시간이 필요한 작업에는 적합하지 않다.
- 그리고 namenode가 단일 실패 지점(SPOF)이 되기 때문에 namenode 관리가 중요하다.
특징
-
블록 단위 저장
- 데이터를 블록 단위로 나눠서 저장함.
- 블록 사이즈보다 작은 파일은 기존 파일의 사이즈로 저장하고, 블록 사이즈보다 큰 크기의 데이터 파일은 블록 단위로 나누어 저장하기 때문에 단일 disk의 데이터보다 큰 파일도 저장할 수 있다.
ex) 블록단위가 256MB일 때, 1G 파일은 4개의 블록으로 나누어 저장되고, 10MB 파일은 하나의 블록으로 저장된다.
-
블록 복제를 이용한 장애 복구
- HDFS는 장애 복구를 위해서 각 블록을 복제하여 저장한다.
- 하나의 블록은 3개의 블록으로 복제되고, 같은 Rack의 서버와 다른 Rack의 서버로 복제되어 저장된다.
- 블록에 문제가 생기면 복제한 다른 블록을 이용해서 데이터를 복구한다.
ex) 1G 데이터를 저장할 때 데이터가 복제되어 3G의 저장공간이 필요하다.
-
읽기 중심
- HDFS는 데이터를 한 번 쓰면 여러 번 읽는 것을 목적으로 한다.
- 파일의 수정은 지원하지 않는다.
- 파일의 수정을 제한하여 동작을 단순화하고 이를 통해 데이터를 읽을 때 속도를 높인다.
-
데이터 지역성
- MapReduce는 HDFS의 데이터 지역성을 이용해서 처리 속도를 증가시킨다.
- 처리 알고리즘이 있는 곳에 데이터를 이동시키지 않고, 데이터가 있는 곳에서 알고리즘을 처리하여 네트워크를 통해 대용량 데이터를 이동시키는 비용을 줄인다.
architecture
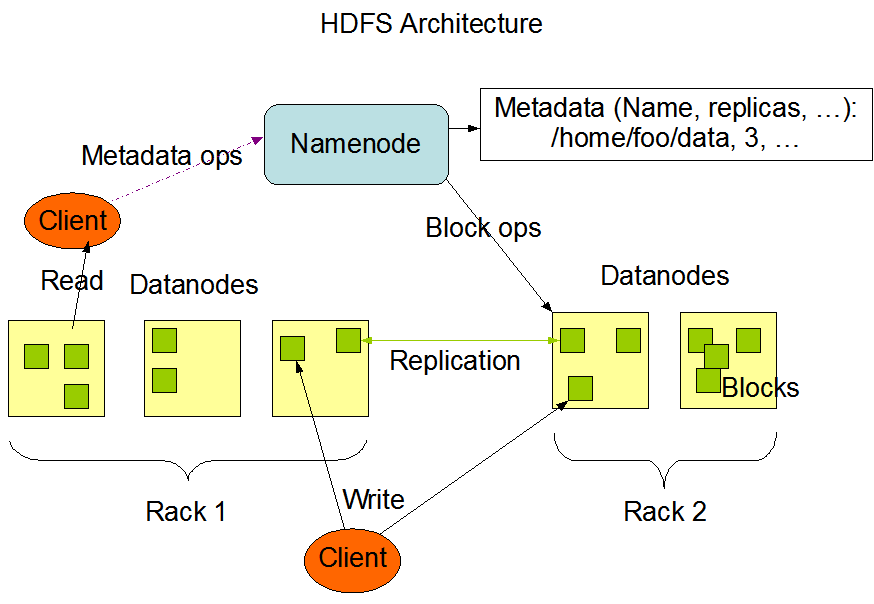
- HDFS는 master-slave 구조로 하나의 namenode와 여러개의 datanode로 구성된다.
namenode
- metadata관리와 datanode의 관리가 주요 역할이다.
- user는 namenode를 통해 데이터를 읽고 쓸 수 있다.
metadata 관리
- metadata는 파일이름, 파일크기, 파일생성시간, 파일접근권한, 파일 소유자 및 그룹 소유자, 파일이 위치한 블록의 정보 등으로 구성된다.
- 각 datanode에서 전달하는 메타데이터를 받아서 전체 노드의 metadata 정보와 파일 정보를 묶어서 관리한다.
- metadata는 사용자가 설정한 위치에 보관되고, namenode가 실행 될 때 파일을 읽어서 메모리에 보관한다.
- 운영중에 발생한 수정사항은 namenode의 메모리에는 바로 적용되고, 데이터수정사항을 다음 구동시 적용을 위해서 주기적으로 edits 파일로 저장한다.
- 종류
- Fsimage 파일: namespace와 block 정보
- Edits 파일: 파일의 생성, 삭제에 대한 트랜잭션 로그, 메모리에 저장하다가 주기적으로 생성
datanode 관리
- namenode는 datanode가 주기적으로 전달하는 heartbeat(3초, dfs.heartbeat,interval)과 blockreport(6시간, dfs.blockreport.intervalMsec)을 이용하여 datanode의 동작상태, 블록상태를 관리한다.
- heartbeat를 이용하여 datanode가 동작중이라는 것을 namenode가 알 수 있다. 만일 heartbeat가 도착하지 않으면 namenode는 datanode가 동작하지 않는 것으로 간주하고, 더이상 IO가 발생하지 않도록(데이터를 저장하지 않도록) 조치한다.
- blockreport를 이용하여 HDFS에 저장된 파일에 대한 최신 정보를 유지한다. blockreport에는 datanode에 저장된 block목록과 각 block이 로컬디스크 어디에 저장되어 있는지에 대한 정보를 갖고 있다.
datanode
- datanode는 파일을 저장하는 역할을 하며 파일은 block 단위로 저장된다.
- datanode는 주기적으로 namenode에 heartbeat와 blockreport를 전달한다.
- datanode의 상태는 활성상태와 운영상태로 나뉜다.
- 활성 상태
- datanode가 live 상태인지 dead 상태인지 나타낸다.
- datanode가 heartbeat를 주기적으로 전달하여 살아있는지 확인되면 live 상태
- 지정한 시간동안(dfs.namenode.stale.datanode.interval) heartbeat를 받지 못하면 namenode는 datanode의 상태를 state 상태로 변경한다.
- 이후 일정한 시간동안 응답이 없으면 Dead node로 변경한다.
- 운영상태
- datanode의 업그레이드, 패치 같은 작업을 하기 위해 서비스를 잠시 멈추어야 할 경우 block을 안전하게 보관하기 위해 설정한다.
- 종류
- NORMAL: 서비스 상태
- DECOMMISSIONED: 서비스 중단 상태
- DECOMMISION_INPROGRESS: 서비스 중단 상태로 진행
- IN_MAINTENANCE: 정비 상태
- ENTERING_MAINTENANCE: 정비 상태로 진행중
- dfs.hosts 파일에 노드의 상태를 json 형태로 기술하여 운영중에 서비스를 잠시 멈추고 정비를 한 후 다시 진행할 수 있다.
- 활성 상태
namenode 구동 과정
- Fsimage와 Edits를 읽어서 작업을 처리하기 때문에 두 파일의 크기가 크면 구동 시작시간이 오래 걸릴 수 있다.
- Fsimage를 읽어 메모리에 적재한다.
- Edits 파일을 읽어와서 변경내역을 반영한다.
- 현재의 메모리 상태를 스냅샷으로 생성하여 Fsimage 파일 생성
- datanode로부터 blockreport를 수신하여 매핑정보 생성
- 서비스 시작.
파일 읽기
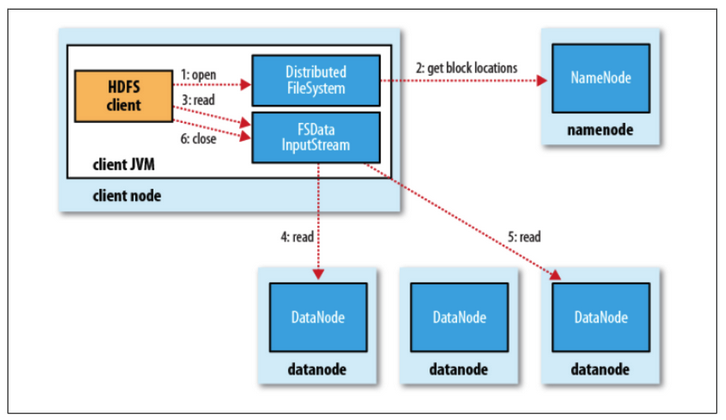
1. namenode에 파일이 보관된 block 위치 요청
2. namenode가 block 위치 반환
3. 각 datanode에 파일 block을 요청 - 노드의 블록이 깨져있으면 namenode에 이를 통지하고 다른 block 확인.
파일 쓰기
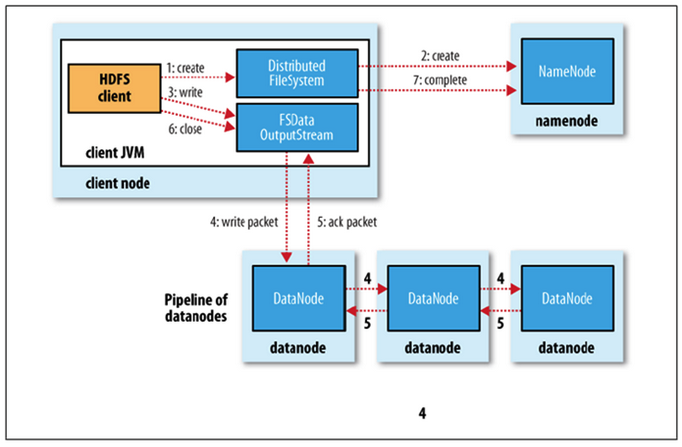
1. namenode에 파일 정보를 전송하고, 파일의 block을 써야할 노드 목록 요청
2. namenode가 파일을 저장할 목록 반환
3. datanode에 파일 쓰기 요청 - datanode간 복제가 진행.
block
- HDFS 파일은 지정한 크기의 block으로 나누어지고, 각 block은 독립적으로 저장된다.
- HDFS의 block은 128MB 단위로 단위가 큰 이유는 탐색비용을 최소화하기 때문이다.
- block이 크면 하드디스크에서 block의 시작점을 탐색하는데 걸리는 시간을 줄일 수 있고, 네트워크를 통해 데이터를 전송하는데 더 많은 시간을 할당할 수 있다.
- 여러 개의 block으로 구성된 대용량 파일을 전송하는 시간은 디스크 IO속도에 크게 영향을 받는다.
특징
- 블록 크기 파일 분할
- 기본 block 크기를 넘어서는 파일은 block 크기로 분할하여 저장한다.
- block 크기보다 작은 파일은 단일 block으로 저장
- 실제 파일 크기의 block이 된다.
- block 단위로 나누어 저장하기 때문에 disk 사이즈보다 더 큰 파일을 보관할 수 있다.
- block 단위로 파일을 나누어 저장하기 때문에 700G * 2 = 1.4T 크기의 HDFS에 1T의 파일이 저장가능하다.
- 블록 추상화의 이점
- HDFS도 큰 파일을 block 단위로 나누어서 단일 disk의 용량보다 더 큰 파일을 저장할 수 있다.
- 파일 단위보다 block 단위로 추상화를 하면 storage의 서브시스템을 단순하게 만들 수 있다.
- 파일 탐색 지점이나 메타정보를 저장할 때 사이즈가 고정되어 있으므로 구현이 좀 더 쉽다.
- 내고장성을 제공하는데 필요한 replication(복제)를 구현할 때 매우 적합
- block 단위로 복제를 구현하기 때문에 데이터 복제에도 어려움 없이 처리할 수 있다.
- 같은 노드에 같은 block이 존재하지 않도록 복제하여 노드가 고장일 경우 다른 노드의 block으로 복구할 수 있다.
- 블록 지역성
- MapReduce를 이용한 분산 컴퓨팅은 블록의 지역성을 이용해 성능을 높인다.
- MapReduce를 처리할 때 현재 노드에 저장되어 있는 block을 이용하는 block locality를 통해 성능을 높일 수 있다.
- network를 이용한 데이터 전송 시간 감소
- 대용량 데이터 확인을 위한 디스크 탐색 시간 감소
- 적절한 단위의 블록크기를 이용한 CPU 처리시간 증가
- 클라우드 저장공간을 이용하는 경우 HDFS를 이용하는 경우보다 속도가 느리다. 하지만 클라우드를 이용하는 경우 영구적인 데이터 보관 및 HDFS 관리비 절감에 따른 장점이 있다.
- 블록 작업 순서
- 블록 지역성을 위한 작업 우선 순위는 다음과 같다.
- 같은 node에 있는 데이터
- 같은 Rack의 node에 있는 데이터
- 다른 Rack의 노드에 있는 데이터
- 블록 스캐너
- 데이터 노드는 주기적으로 블록 스캐너를 실행하여 block의 checksum을 확인하고 오류를 발생하면 수정한다.
- 블록 캐싱
- datanode에 저장된 데이터 중 자주 읽는 block은 block cache라는 datanode의 메모리에 명시적으로 caching할 수 있다.
- 파일 단위로 caching할 수도 있어서 조인에 사용되는 데이터들을 등록하여 읽기 성능을 높일 수 있다.
secondary namenode
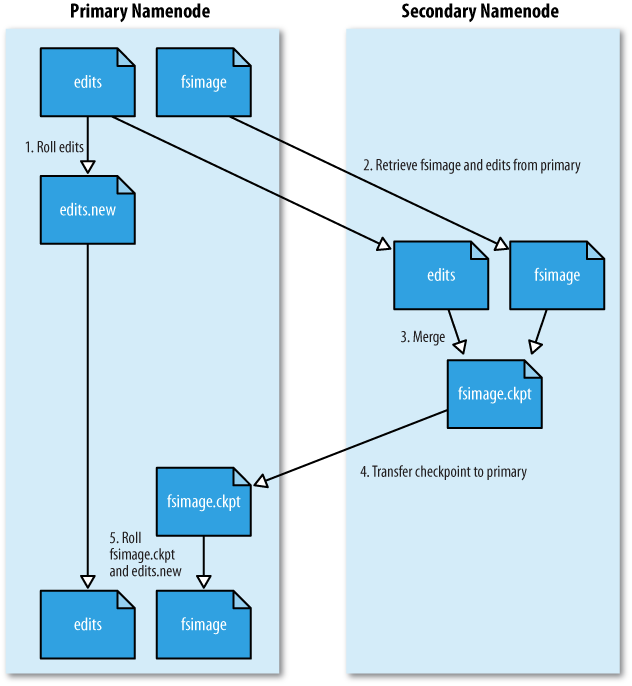
- namenode가 구동되고 나면 Edits 파일이 주기적으로 생성된다.
- namenode의 트랜잭션이 빈번하면 빠른 속도로 Edits 파일이 생성된다.
- 이는 namenode의 disk 부족 문제를 생성할 수 있고, namenode가 재구동 되는 시간을 느려지게 할 수 있다.
- secondary namenode는 Fsimage와 Edits 파일을 주기적으로 merge하여 최신 블록의 상태로 파일을 생성한다.
- 파일을 merge하면서 Edits 파일을 삭제하기 때문에 디스크 부족 문제도 해결할 수 있다.

Github - https://github.com/dddwsd