스프링 데이터 JPA를 사용하면, JpaRepository 인터페이스를 상속받아서 새로운 인터페이스를 만들어 쿼리 메서드를 상황에 맞춰 만드는 것만으로도 기능이 잘 동작한다.
public interface MemberRepository extends JpaRepository<Member, Long> {
...
}위의 코드는 JpaRepository 인터페이스를 상속받아 만든 리포지토리를 MemberRepository이다. 물론 잘 동작하는 리포지토리이다. 근데 @Repository 어노테이션을 붙여서 스프링 빈으로 등록해주지도 않았고, 구현체에 대해선 일절 건드리지 않았다.
스프링 데이터 JPA의 구현체
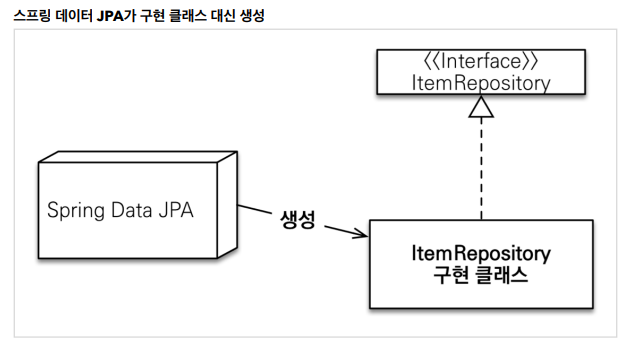
어떻게 잘 동작할 수 있을까? 이유는 스프링 데이터 JPA가 사용자가 JpaRepository 인터페이스를 상속받는 리포지토리 인터페이스를 만나면, 이를 구현한 클래스를 동적으로 생성하고 생성한 클래스를 빈으로 등록하여 의존성 주입을 해주기 때문 이다.
직접 출력해보자.
@Autowired MemberRepository memberRepository;
@Test
public void test() {
System.out.println(memberRepository.getClass());
}class com.sun.proxy.$Proxy138실제로 프록시 객체가 주입된 것을 확인할 수 있다. 이는 SimpleJpaRepository 클래스를 기반으로 생성된 프록시 객체이다.
결론은, 스프링 데이터 JPA가 JpaRepository 인터페이스를 상속받는 리포지토리 인터페이스를 만나면 SimpleJpaRepository 클래스를 기반으로 동적으로 프록시를 생성해서 잘 동작할 수 있었던 것이다.
SimpleJpaRepository 클래스
@Repository
@Transactional(readOnly = true)
public class SimpleJpaRepository<T, ID> implements JpaRepositoryImplementation<T, ID> {
private final EntityManager em;
@Override
public List<T> findAll() {
return getQuery(null, Sort.unsorted()).getResultList();
}
@Transactional
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null.");
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}
...
}SimpleJpaRepository 클래스의 내부를 살펴보면, 이는 결국 EntityManager를 기반으로 작성되어 있다. 즉, 내부적으로는 순수 JPA로 구현되어 있고 개발자들은 내부적인 것들을 몰라도 사용할 수 있게끔 추상화가 되어 있는 것이다.
save(S entity) 의 함정
entityInformation.isNew(entity) 가 true라면, em.persist(entity)를 수행하지만, 아니라면 em.merge(entity) 를 수행한다. entityInformation.isNew(entity)가 의미하는 바는 데이터베이스에 없는 새로운 엔티티인 것을 의미한다.
em.persist() 는 영속성 컨텍스트의 쓰기 지연 SQL 저장소에 INSERT SQL문을 저장하고, 스냅샷을 저장해둔다.
하지만, em.merge()는 DB에 있는 데이터를 가져와서, save()한 엔티티로 교체해버린다. 즉, select SQL문을 실행해서 em.persist()에 비해 굉장히 비효율적으로 동작하게 된다.
- 새로운 엔티티라면
em.persist()호출 - 새로운 엔티티가 아니라면
em.merge()호출
새로운 엔티티를 판단하는 기본전략
- 식별자가 객체(Integer, String, Long ...)일 때 null로 판단
- 식별자가 자바 기본 타입(int, long, char ...)일 때 "0"으로 판단
- 추가로, 개발자가 직접 "Persistable" 인터페이스를 구현해서 판단 로직 변경하는 것도 가능
첫번째 예제>
@Entity
@Getter
public class Item {
@Id @GeneratedValue
private Long id;
} @Test
public void save() {
Item item = new Item();
itemRepository.save(item);
}디버깅해보면 위의 상황에서는 em.persist()로 동작한다.
두번째 예제>
@Entity
@Getter
public class Item {
@Id
private String id;
public Item(String id) {
this.id = id;
}
} @Test
public void save() {
Item item = new Item("A");
itemRepository.save(item);
}직접 디버깅해보면 위의 상황에서는 em.merge()로 동작한다. 왜? null이 아니기 때문이다. 데이터베이스에 해당 PK가 없음에도 말이다.
아까 말했듯, em.merge() 로 동작하게 되면 select SQL문이 실행되어 em.persist()에 비해 성능상 비효율적이다.
정리하자면, JPA 식별자 생성 전략이 첫번째 예제 처럼@GeneratedValue를 쓰면 save() 호출 시점에 식별자가 없으므로, 새로운 엔티티로 인식해서 정상 동작한다.
그런데 JPA 식별자 생성 전략이 @Id 만 사용해서 직접 할당 방식이라면, 이미 식별자 값이 있는 상태로 save()를 호출한다.
그렇게 되면 em.merge()가 호출된다. merge()는 우선 DB를 조회해서 값을 확인하고, 값이 없으면 새로운 엔티티로 인지하므로 persist()에 비해 성능 상 비효율적이다.
따라서, 식별자를 직접 할당하는 방식은 Persistable 인터페이스를 구현해서 새로운 엔티티 확인 여부를 직접 구현하는게 효과적이다. 참고로 등록시간을 조합해서 사용하면 이 필드로 새로운 엔티티 여부를 편리하게 확인할 수 있다. 아래의 예제를 보자.
@Entity
@Getter
@EntityListeners(AuditingEntityListener.class)
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Item implements Persistable<String> {
@Id
private String id;
@CreatedDate
private LocalDateTime createdDate;
public Item(String id) {
this.id = id;
}
@Override
public boolean isNew() {
return createdDate == null;
}
}
위처럼 createdDate 필드의 null 여부로 새로운 엔티티인지 확인하는 로직을 오버라이딩해주면 persist() 함수에서도 의도치 않은 성능상 저하를 막을 수 있다.
@CreatedDate어노테이션으로 생성되는 생성날짜는em.save()메서드 이후에 호출되기에 이렇게 새로운 엔티티인지를 체크할 수 있다.
