이번 포스트에서는 'An Introduction to Kernel-Based Learning Algorithms' 라는 Paper를 리뷰하며 머신러닝에서 널리 사용되는 커널 이론의 원리와 배경에 대해 알아보고자 한다. 이번 장에서는 먼저 커널 함수가 대표적으로 이용되는 서포트 벡터 머신을 간단하게 살펴볼 것이다,
분류 이론의 기초
서포트 벡터 머신은 회귀 문제에도 사용되지만, 대표적인 분류 문제를 해결하기 위한 머신러닝의 지도학습, 비지도학습 중에서 분류 문제는 Input Space 의 각 원소에 대한 클래스(y) 값을 예측하는 것이다. 만약 주어진 문제에서 입력 데이터가 N차원 벡터로 주어지고, 그 값은 모두 실수를 가지며 분류해야 할 클래스가 두개라면, 해당 분류문제는
에 해당하는 함수 를 추정하는 것이라고도 볼 수 있다.
이때 인 Space를 두면 각각의 , 에 대해
인 확률분포를 생각할 수 있다.
이를 바탕으로, 임의의 손실함수 에 대해 위험함수
를 최소화하는 함수 f를 추정하면 될 것이다.
그러나, 일반적인 경우에서는 확률분포 를 직접 구할 수 없으므로, n개의 표본으로부터 구할 수 있는 실험적 위험empirical risk
을 최소화하는 방법을 고려하게 된다.
이때 표본 수 n이 커질수록 대수의 법칙에 의해 실험적 위험은 위험함수에 확률수렴하게 된다. 하지만 이와 동시에 과적합overfitting 문제가 발생할 수 있으므로 함수의 복잡성을 제어할 방법이 필요하다.
복잡성 규제Complexity Regularization
앞서 말한 것과 같이, 함수의 복잡성을 제어하기 위해서는 규제가 필요하다. 분류 문제에서 함수 를 추정한다고 하자. 아때, 우리가 어떤 함수를 추정한다는 것은 함수들의 집합, 즉 함수족function class 에 포함되어 있는 원소인 어떤 함수 를 선택하는 행위와 동치이다. 함수족 의 복잡성을 제한하기 위한 방법으로는 여러가지가 존재하는데, 대표적으로 규제항regularization term을 추가하는 방법이 있다. 규제와 관련한 자세한 내용은 별도의 주제로 $$다루도록 하겠다.
커널특성공간Kernel Feature Space
데이터 표현Data Representation
어떤 학습 문제에서 이 분석 대상이 되는 n개의 대상이라고 하자. 또한, 각각의 관찰된 벡터는 집합 의 원소라고 하자.
예를 들어 픽셀의 이미지들을 분류하는 문제를 처리한다고 가정하자(e.g. Mnist Problem), 이때 관측된 개개의 벡터 (여기서는 행렬)은 의 개별 이미지일 것이다. 또한 이 개별 이미지들은 행렬이고 그 성분이 에 속한 임의의 실수라고 하면 로 표현 가능하다.
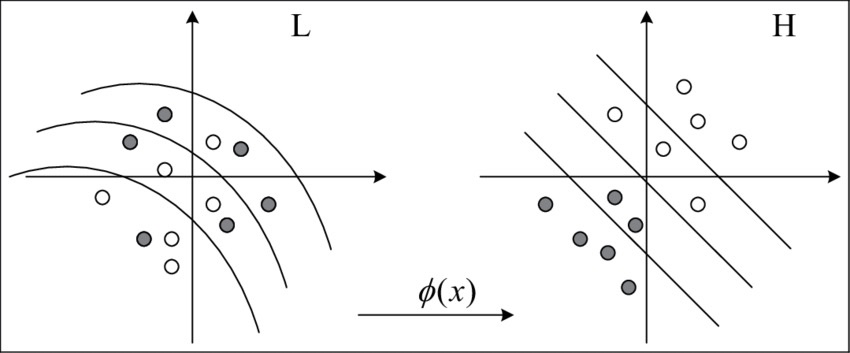
하지만 관측값들이 위 예시와 같이 처리하기 쉬운 형태가 아닐 경우 머신러닝 연산에 유용한 형태로 변형이 필요하다. 우리는 이러한 변형을 로 표현한다. 여기서 는 특성 공간feature space으로, 앞서 설명한 예를 이용하면 행렬을 연산에 쉬운 형태인 실벡터로 표현하는 것은 각각의 행렬을 특성공간 의 원소로 대응시키는 것과 동치이다.
따라서, 데이터셋 은 특성공간 에서
으로 표현된다.
커널 알고리즘
커널 알고리즘은 데이터 표현 방법과는 결이 다른 알고리즘이다. 커널과 무관한 분석 알고리즘은 앞서 설명한 것과 같이 Raw data를 처리하기 쉬운 형태로 표현하여 이를 기반으로 학습을 수행한다. 반면, 커널 알고리즘은 데이터 표현 사상 대신에 커널 함수 을 이용한다. 따라서 데이터셋을 라고 할 때 이에 커널 함수를 적용하면 행렬 가 도출되고, 각 원소 는 i번째 관측벡터와 j번째 관측벡터의 커널 값인 이다. 따라서, 이 커널 값을 일종의 비교comparison의 결과로 볼 수 있는데, 두 관측치를 커널을 통해 비교한 것으로 생각할 수 있기 떄문이다.
일반적인 커널 함수의 정의
Def 함수 가 대칭적symmetric이고 positive definite일 떄, 함수 를 positive definite kernel 라고 한다. 즉, 다음 두 조건을 만족한다.
- 임의의 에 대해
- 임의의 n개의 관측치 와 임의의 실수 에 대해서
이제 이렇게 정의된 커널의 특성들을 살펴보자. 우선, 분석 대상이 되는 데이터셋이 유클리드 공간 에서의 벡터로 주어진다고 생각하자. 이때, 는 내적공간Inner product space이고, 일반적으로 사용되는 내적은
으로 정의되는 것을 알고 있다. 내적은 앞서 정의한 커널함수의 두 가지 조건을 모두 만족하는데, 이를 통해 유클리드 공간에서의 내적은 커널함수임을 알 수 있다.
더 나아가, 앞서 설명한 Data Representation을 고려하면, 일반적인 데이터 공간에서의 는 로 표현되고 이는 유클리드 공간의 원소이므로
로 정의된 함수는 커널 함수임을 알 수 있다.
힐베르트 공간Hilbert Space을 생각하면, 이는 내적공간이므로 앞서 언급한 유클리드 공간을 힐베르트 공간으로 대신해 생각할 수 있다. 이로부터 다음 정리를 얻을 수 있다.
정리 데이터 공간 의 어떤 커널함수 에 대해 힐베르트공간 와 사상 가 존재하여 임의의 에 대해 다음을 만족한다.
유사성의 측도로서의 커널 함수
커널 함수는 형태로 주어지므로, 정의역에 포함되는 데이터 쌍 의 관계를 측정하는 함수로 해석가능하다. 서포트 벡터 머신에서 자주 사용되는 가우시안 방사기저함수Gaussian Radial basis function 커널을 고려해보자.
Gaussian RBF kernel
데이터 공간이 , 즉 유클리드 공간일 경우에 다음가 같이 정의된다.
이때 는 유클리드공간에서의 거리이며, 는 모수이다. 즉, RBF 커널은 유클리드 거리를 기반으로 하기 때문에 이는 데이터 쌍의 유사성을 측정하는 것과 관련있다. 데이터 상의 유클리드 거리가 가까울수록 커널의 값이 커지게 되며, 추후에 살펴볼 것과 같이 결국 이러한 이유로 RBF 커널을 이용한 서포트 벡터 머신은 거리가 가까운 유사한 그룹을 분류해내는 데 사용된다.
커널함수를 이용한 함수공간 생성
커널함수 가 데이터 공간 에서 주어질 때, 함수공간(힐베르트공간) 에서의 노음은 커널의 관점에서 정의될 수 있다. 커널을 이용해 함수공간을 구성하는 방법을 살펴보면 다음과 같다. 우선, 함수공간 를 다음 형태로 정의되는 함수들의 집합이라고 정의하자.
이떄, 데이터 들은 유한개로 정의된다고 하자. 또한, 이때 함수 의 노음을 다음과 같은 가중합으로 정의할 수 있다.
또한, 에서의 함수 , 의 내적은 다음과 같이 정의할 수 있다.
이러한 방식으로 커널을 통해 정의한 함수공간이 힐베르트공간임을 알 수 있다.
References
- An Introduction to Kernel-Based Leaning Algorithms, K.R. Muller et al.
- A primer on kernel methods, J.Philippe Vert et al.
