StringTokenizer 클래스란?
문자열을 우리가 지정한 구분자로 문자열을 쪼개주는 클래스
-> 쪼개어진 문자열을 토큰(token)이라고 함.StringTokenizer 라이브러리 import
import java.util.StringTokenizer;StringTokenizer 생성자
StringTokenizer st = new StringTokenizer(문자열);
-> 띄어쓰기 기준으로 문자열을 분리StringTokenizer st = new StringTokenizer(문자열, 구분자);
-> 구분자를 기준으로 문자열을 분리StringTokenizer st = new StringTokenizer(문자열, 구분자, true/false);
->구분자를 기준으로 문자열을 분리할 떄 구분자도 토큰으로 넣을지(true)구분자는
분리된 문자열 토큰에 포함 안시킬지(false)
※ default는 false예시>
String str = "문!자!열";
StringTokenizer st = new StringTokenizer(str, "!", true);
int i=1;
while(st.hasMoreTokens()) { // 다음 토큰이 있다면
System.out.println((i++)+"번쨰 토큰:"+st.nextToken());
}
-> 구분자가 '!'이지만, true로 설정해서 느낌표까지 토큰이 총 5개 생성
※ 구분자를 하나의 문자가 아닌 여러 문자로 구분하기
String str = "정유진-velog주소:velog.io/@dbwls8382";
StringTokenizer st = new StringTokenizer(str, ":-");
int i=1;
while(st.hasMoreTokens()) { // 다음 토큰이 있다면
System.out.println((i++)+"번쨰 토큰:"+st.nextToken());
}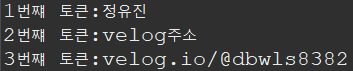
-> 하나 문자가 아닌, 여러개의 문자를 구분자로 토큰을 만들 수 있음.
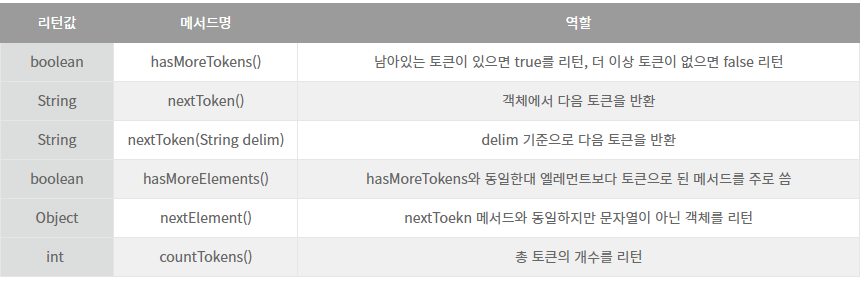
StringTokenizer 메서드
StringTokenizer와 Split
공통점 : 문자열 파싱하는데 사용 차이점:
- StringTokenizer는 java.util에 포함되어 있는 클래스,
split는 String클래스에 속해있는 메서드
- StringTokenizer는 문자 또는 문자열로 문자열을 구분한다면,
split는 정규표현식으로 구분
- StringTokenizer는 빈 문자열을 토큰으로 인식하지 않지만
split는 빈 문자열을 토큰으로 인식
- StringTokenizer는 결과값이 문자열이라면
split은 결과값이 문자열 배열
-> StringTokenizer일 경우,
전체토큰을 보고 싶다면 반복문을 이용해서 하나하나뽑을 수 밖에 없음.
- 배열에 담아 반환하는 split은 데이터를 바로바로 잘라서 반환해주는
StringTokenizer보다 뒤쳐짐 (허나, 데이터 많으면 피차일반)

개발자 준비중입니다.