조회수,좋아요의 일관성 문제!
문제(게시글)의 조회수 및 좋아요는 문제 조회가 일어날 때마다 Update가 이뤄져야 데이터의 일관성을 맞출 수 있다!!! -> 지속적인 DB Traffic의 발생!
어떻게 DB Traffic을 줄일 것인가??
효율적인 DB Traffic을 줄이고 빠르게 데이터를 가져올 방법을 고안 해보는 과정에서 기존 RDBMS의 접근을 최소화하기 위한 Cache시스템을 구상했고 아래의 2가지 Storage를 생각했습니다.
1. Redis(InMemory)
2. Cache(Spring boot Cache)
필자는 Redis를 택하였고, 그에 대한 이유는 글을 이어가며 설명하겠습니다.
왜 Redis인가??
Redis를 택한 이유는 너무나도 많습니다. 하지만 크게 세가지 이유로 정리해보겠습니다.
1. Global Cache를 사용해야했습니다.
- 조회수 및 좋아요는 모든 사용자의 요청으로 Count되야하며, 모든 서버에서 접근이 가능해야하기 때문에 Local Cache가 아니라 Global하게 관리되어야 했습니다. Spring Boot Cache는 WAS의 Cache에 저장되며, Local로 활용되기 때문에 Redis가 적합하다 생각했습니다.
- 다양한 자료형을 지원합니다.
- 이전에 Redis에 간략하게 설명했던 글이 있습니다. 그 글을 보면 Redis는 Set,HashSet,List,Sorted set, String 등 다양한 자료형을 지원하기에 활용범위가 더 넓습니다.
- 좋아요와 조회수를 Hash로 같은 KEY를 가져야하기에 Set으로만 지원하는 Cache보단 Redis를 택했습니다.
- Atomic을 보장해줍니다.
- Redis는 NoSQL DB 처럼 Single Thread로 동작하기에 Atomic성을 어느정도 보장해줍니다.
- 물론 동시성 이슈를 100%해결하지는 못합니다.(추후에 정리할 주제입니다.)
Spring Boot에서 Redis를 써보기
Redis를 활용하기로 택하였고 이제부터 필자가 Spring Boot에서 Redis를 어떻게 썼는지 보여주고자 한다. Spring boot는 3.0.x 버전, java = 17jdk.
1. 가장 먼저 해야할 것은 Redis 설치이다.
필자는 Docker를 통해 Redis를 설치하였습니다.docker run --name redis -d -p 6379:6379 redisTerminal에서 6379포트로 열고 name = redis로 설정하여 image를 설치하고 run을 시켜 Redis서버를 실행시켰습니다.
2. Spring boot에서 application.properties와 dependency 설정을 완료합니다.
- application.properties
spring.data.redis.host=127.0.0.1 spring.data.redis.port=6379 spring.data.redis.timeout=10
- build.gradle
//Redis를 위한 의존성 추가 implementation 'org.springframework.boot:spring-boot-starter-web' implementation 'org.springframework.boot:spring-boot-starter-data-redis'
- RedisConfiguration 클래스를 작성해줍니다.
@Configuration @RequiredArgsConstructor public class RedisConfig{ @Value("${spring.data.redis.host}") public String host; @Value("${spring.data.redis.port}") public int port; @Value("${spring.data.redis.timeout}") private Long timeout; @Bean public LettuceConnectionFactory lettuceConnectionFactory() { final SocketOptions socketoptions = SocketOptions.builder().connectTimeout(Duration.ofSeconds(10)).build(); final ClientOptions clientoptions = ClientOptions.builder().socketOptions(socketoptions).build(); LettuceClientConfiguration lettuceClientConfiguration = LettuceClientConfiguration.builder().clientOptions(clientoptions) .commandTimeout(Duration.ofMinutes(1)) .shutdownTimeout(Duration.ZERO) .build(); RedisStandaloneConfiguration redisStandaloneConfiguration = new RedisStandaloneConfiguration(host, port); redisStandaloneConfiguration.setDatabase(0); return new LettuceConnectionFactory(redisStandaloneConfiguration, lettuceClientConfiguration); } @Bean(name="redisTemplate") public RedisTemplate<String, Object> redisTemplate() { RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>(); redisTemplate.setConnectionFactory(lettuceConnectionFactory()); redisTemplate.setKeySerializer(new StringRedisSerializer()); redisTemplate.setValueSerializer(new Jackson2JsonRedisSerializer<>(Object.class)); redisTemplate.setHashKeySerializer(new StringRedisSerializer()); redisTemplate.setHashValueSerializer(new Jackson2JsonRedisSerializer<>(Object.class)); redisTemplate.afterPropertiesSet(); return redisTemplate; } }위의 코드를 잠시 설명하자면 @Value를 통해 host의 port번호와,Redis 서버의 Port 번호를 받아옵니다. 그리고 추가적으로 timeout을 통해 Redis의 서버 접속 시도를 일정시간이 지나도록 접속이 안된다면 멈추겠다는 뜻입니다.
첫 번째 @Bean은 Redis와의 Connection을 위한 Bean입니다.
두 번째 @Bean은 이제 Spring boot에서 Redis를 활용하기 위한 Redis를 선언하며 각각 자료형에 대해 선언합니다. 그리고 Serializer을 통해 Redis가 Spring boot 자료형을 인식할 수 있도록 합니다. Serializer에 대해 간단히 설명하자면!!
Redis의 데이터는 Byte로 저장됩니다. 그러면 어떻게 java의 String, Long, Int 등 다양한 자료형을 가지고가서 나중에 보여주는 것인가??? 그것을 가능케 하는 기법이 serializer입니다. Serializer은 데이터의 자료형을 가지고 함께 가는 것입니다. 그래서 그것을 다시 역Serializer을 해서 읽을 때 자료형을 알 수 있는 것입니다.
Redis의 활용
지금부터는 필자는 어떻게 조회수,좋아요를 카운트하고 DB의 트래픽을 줄였는지 Service로직을 짰는지 보여주고자 합니다.
@Transactional @Override public void addLikesCntToRedis(Long problemId){ HashOperations<String, String, Object> hashOperations = redisTemplate.opsForHash(); String key = "problemId::" + problemId; String hashkey = "likes"; if(hashOperations.get(key,hashkey) == null){ hashOperations.put(key,hashkey,problemRepository.getLikesCnt(problemId)); hashOperations.increment(key,hashkey,1L); System.out.println(hashOperations.get(key,hashkey)); }else {hashOperations.increment(key,hashkey,1L); System.out.println(hashOperations.get(key, hashkey));} }위의 코드는 게시글에 대한 상세조회가 요청이 들어왔을 때 Redis에게 count + 1 이 이뤄지는 Service Logic입니다.
HashSet을 통해 자료형을 구현했고, Key는 ProblemId인 고유 키로 확인합니다. hashkey는 views로 좋아요와 구별하기위해 설정합니다.
- 그리고 만약 해당 key와 hashkey로 조회했을 때 value가 없다면 DB에서 값을 가져오는 동시에 increment의 메소드를 통해 count를 하나 추가해줍니다.
- 반대로 value가 존재한다며 DB에 가지않고 바로 Redis의 값을 하나 증가 시킵니다.
@Scheduled(fixedDelay = 1000L*18L) @Transactional @Override public void deleteViewCntToRedis(){ String hashkey = "views"; Set<String> Rediskey = redisTemplate.keys("problemId*"); Iterator<String> it = Rediskey.iterator(); while (it.hasNext()) { String data = it.next(); Long problemId = Long.parseLong(data.split("::")[1]); if (redisTemplate.opsForHash().get(data, hashkey) == null){ break; } Long viewCnt = Long.parseLong((String.valueOf(redisTemplate.opsForHash().get(data, hashkey)))); problemRepositoryImp.addViewCntFromRedis(problemId, viewCnt); redisTemplate.opsForHash().delete(data, hashkey); } System.out.println("views update complete"); }위의 코드는 Redis에 기록된 정보들을 DB에 업데이트를 진행하면서 데이터의 일관성을 유지하고, Redis의 저장된 정보들을 초기화 합니다.
- Reids의 존재하는 Key들을 전부 불러와 Set에 저장합니다.
- Iterator를 통해 Key를 하나씩 읽어 각 Key에 저장된 정보들을 DB에 저장합니다.
- 하지만 만약 Redis가 아직 비어있다면, null값이 들어올 수 있기에 예외처리를 진행해줍니다.
- 여기서 또 중요한 것은 Redis가 DB의 업데이트를 일정시간마다 실행될 수 있도로 Spring Boot Scheduled를 활용하여 자동화를 시켜놓은 것을 알 수 있습니다.
결과 Log
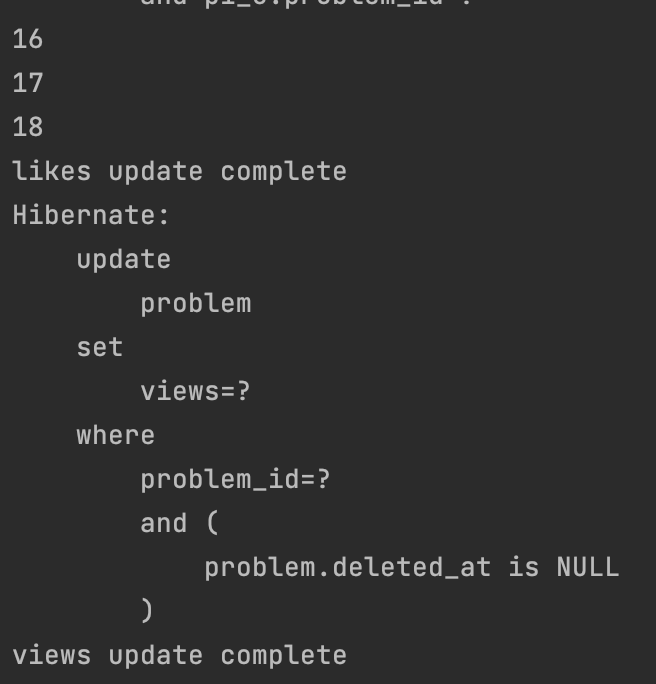
위의 요청을 보면 조회수가 Update 쿼리문 없이 증가하는 것을 볼 수 있습니다. 그리고 일정시간을 지나면 update가 이뤄지면서 쿼리문이 나오며 update complete라는 결과를 볼 수 있습니다.
글을 마치며
어떻게하면 DB의 트래픽을 줄이고 응답속도를 높이며 최적화 시킬 수 있는지 고민하는 시간이였다. 그 과정에서 Redis와 Cache에 대한 공부를 진행할 수 있었습니다. BackEnd 및 서버 개발자라면 이런 사고를 기본적으로 가져야한다고 생각합니다.
