📍 의사결정나무 (Decision Tree)
의사결정나무는 주로 불연속 데이터를 다루며 노이즈가 발생해도 중단되거나 엉뚱한 결과를 보여주지 않는 매우 강건한 모델이다.
- 의사결정나무는 데이터에 존재하는 패턴을 예측 가능한 규칙들의 조합 형태로 나타내며, 그 모양이 나무와 같기 때문에 '의사결정나무'라고 불린다.
- 분류와 회귀가 모두 가능한 알고리즘이다.
👉 범주나 연속형 수치 모두 예측할 수 있다는 것! - 쉽게 말해 결정을 위해 스무고개와 같은 예/아니오의 질문을 반복 학습한다.(=질문을 던져서 맞고 틀리는 것에 따라 우리가 생각하고 있는 대상을 좁혀나감)
🏝 분류 나무
목표 변수: 이산형(범주형)
순수도 측정: 지니계수, 엔트로피 지수, 카이제곱 통계량의 p-value
👉 모두 작을수록 순수도가 높음
🏝 회귀 나무
목표 변수: 연속형
순수도 측정: 분산분석 F-통계량의 p-value,분산의 감소량
👉 분산분석 F-통계량의 p-value 작을수록,분산의 감소량이 높을수록 순수도가 높음
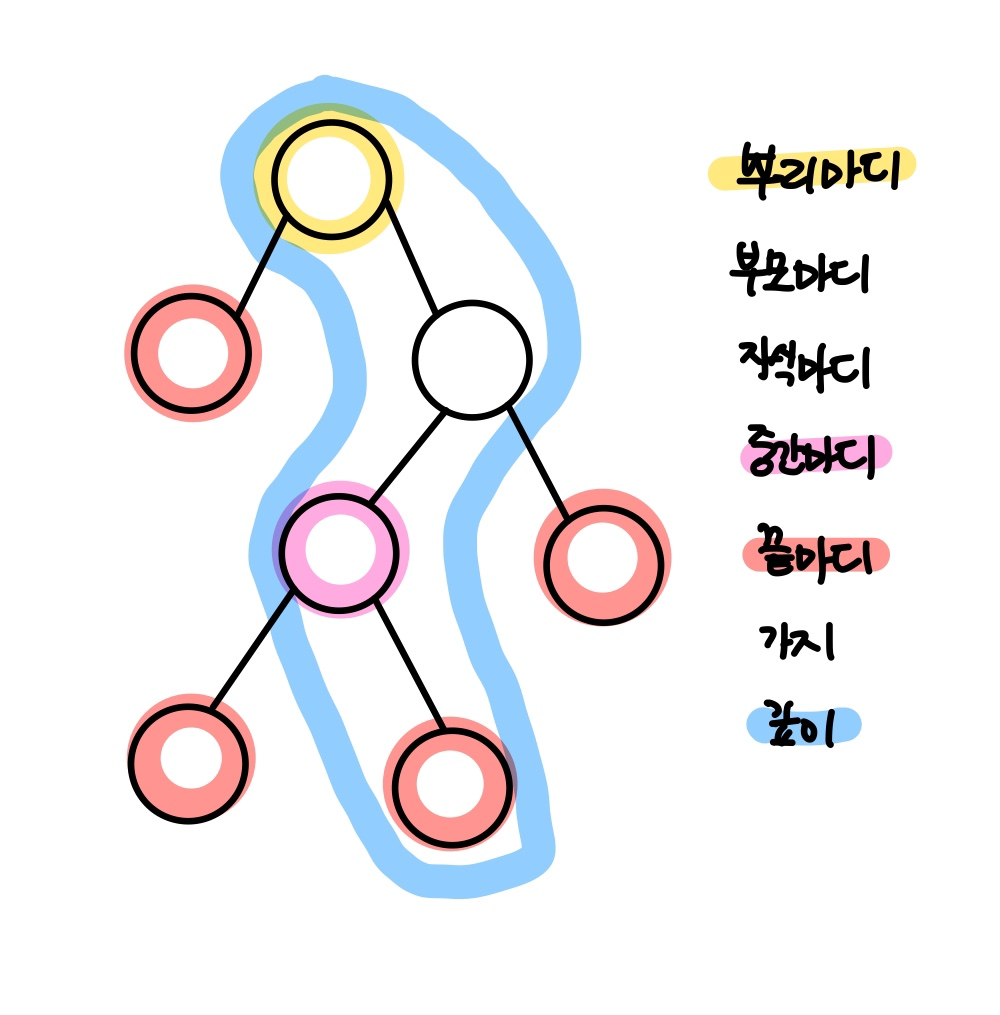
| 마디 종류 | 설명 |
|---|---|
| 뿌리마디(root node) | 시작되는 마디 |
| 부모 마디(parent node) | 주어진 마디의 상위마디 |
| 자식마디(child node) | 하나의 마디에서 분리된 2개 이상의 마디들 |
| 중간마디(internal node) | 부모마디와 자식마디가 있는 마디 |
| 끝마디(terminal node)/잎(leaf) | 자식마디가 없는 마디 |
| 가지(branch) | 뿌리마디부터 끝마디까지 연결된 마디 |
| 깊이(depth) | 가장 긴 가지의 크기(마디의 개수) |
이 깊이(depth)가 너무 깊어지면 과대적합, 이 깊이가 너무 작으면 과소적합 문제가 일어남!
| 알고리즘 | 평가지수 |
|---|---|
| ID3 | Entropy |
| C4.5 | Information Gain |
| CART | Gini Index,분산의 차이 |
| CHAID | 카이제곱,F검정 |
ID3 알고리즘
- 반복적으로 이분하는 알고리즘
- 연속형 변수 사용 불가 !❌
재귀적 분할 알고리즘
1) CART (Classification And Regression Tree)
2) C4.5
3) CHAID (Chi - square Automatic Interation Detection)
CART (Classification And Regression Trees)
- Binary Split 형태를 따른다.
ex) age-> youth,middle,senior로 나누지 않고, age-> youth,그 외 것들 이렇게 2개의 가지만 뻗는다. - 분류와 회귀 모두 가능하다.
- CART의 목적은 정보이득(IG)를 최대화하는 것임
C4.5
- 연속형, 이산형 변수 둘 다 가능한 알고리즘이다.
의사결정나무 기반 분류
각 영역의 순도가 증가, 불순도(불확실성)이 최대한 감소하는 방향으로 학습을 진행한다. 이 개념을 이해하기 위해서 먼저 알아야할 개념들이 있다.
불순도 (Impurity)
 그림으로 바로 이해할 수 있다. A와 B중 B는 빨간색과 파란색이 섞여 있으며, 불순도가 높은 상태라고 할 수 있다.
그림으로 바로 이해할 수 있다. A와 B중 B는 빨간색과 파란색이 섞여 있으며, 불순도가 높은 상태라고 할 수 있다.
이러한 불순도를 수치화한 지표가 바로 엔트로피와 지니계수이다.
ID3와 C4.5는 불순도 알고리즘으로 Entropy를 사용한다.
두 알고리즘이 가장 큰 차이는 연속형 변수를 사용할 수 있느냐와 없느냐이다.
엔트로피 (Entropy)
엔트로피란?
- 불순도를 측정하는 지표로서, 정보량의 기댓값이다.
- 엔트로피 값이 높을수록 불순도가 높다.
- 엔트로피 지수의 최대 값은 1이다.수식 설명
log2 = 컴퓨터는 0과 1인 즉 bit로 구성되어 있기 때문에 log2에 값을 넣어 계산을 하게 된다.
(-) = 전체 개수 중에 속해 있는 개수를 구하기 때문에 Pk가 항상 분수 형태가 되고, 로그를 붙이면 항상 음수가 나오기 때문에 (+)로 전환시켜주기 위해 필요하다.
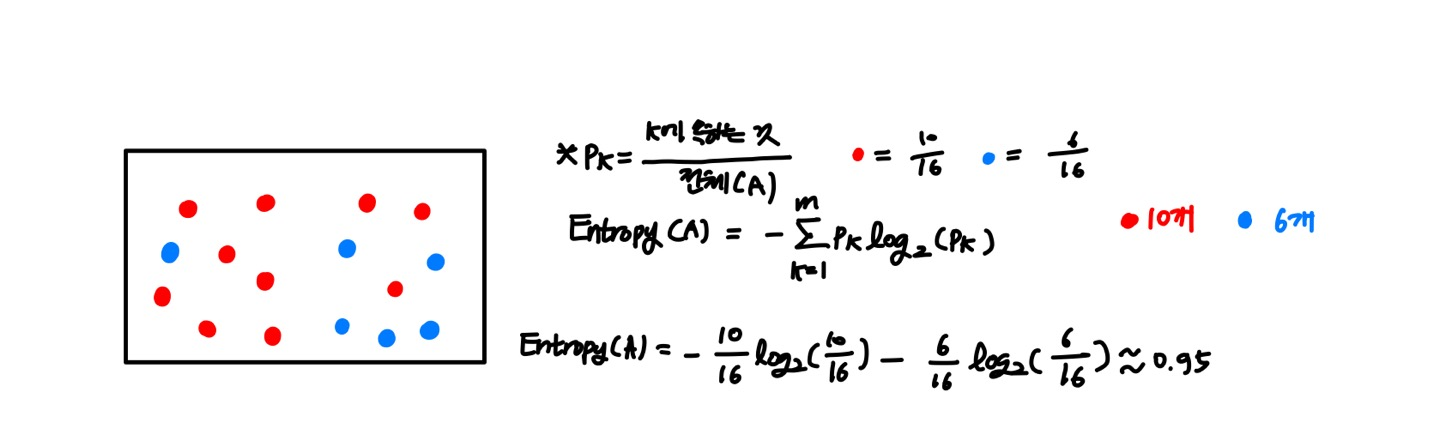

엔트로피가 감소?
👉 불확실성 감소 👉 순도 증가 👉 정보획득 !
정보획득 (Informatin Gain)
- 분할 전 Entropy와 분할 후 Entropy의 차이
- 부모노드 보다 자식 노드에서 불순도가 감소됐을 때 불순도의 차이를 말함
- 정보획득량이 크다는 것은?
👉 어떤 속성으로 분할했을 때 불순도(불확실성)가 줄어들었다는 것 !
👉 정보획득(IG) 값이 클 수록 좋다 !
지니 계수 (Gini Index)
- 지니 계수는 불확실성을 의미한다.
- 얼마나 불확실한가? = 얼마나 많은 것들이 섞여있는가?
- Gini Index = 0, 불확실성이 0으로 같은 특성을 가진 것들이 잘 모여 있다는 말 ! (순수도가 높다)
👉지니 계수가 작을수록 불순도가 낮다!
- 지니 계수의 최대 값은 0.5이다.
수식 설명
^2(제곱) = 한 번만 측정하는 것은 우연히 그 결과가 발생할 수 있다. 그렇기 때문에 최소한 두 번은 측정해야 그 결과를 정확히 알 수 있다는 의미의 제곱이다.
(통계에서의 복원 추출 개념을 사용)
💻 의사결정나무 실습
https://www.youtube.com/watch?v=YEt0ViG_VXk
다음 강의를 참고하여 실습을 진행했습니다.
import pandas as pd
import numpy as np
import graphviz
import multiprocessing
import matplotlib.pyplot as plt
plt.style.use(['seaborn-whitegrid'])
from sklearn.datasets import load_iris
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import cross_val_score
from sklearn.pipeline import make_pipelineiris = load_iris()
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
iris_df['target']= iris.target
iris_df.head(3) 
# 전처리 전
model = DecisionTreeClassifier()
cross_val_score(
estimator = model,
X = iris.data, y= iris.target,
cv=5,
n_jobs = multiprocessing.cpu_count()
) 
의사결정나무는 규칙을 학습하는 것이기 때문에 전처리에 큰 영향을 받지 않는다!
model = make_pipeline(
StandardScaler(),
DecisionTreeClassifier()
)
cross_val_score(
estimator = model,
X = iris.data, y= iris.target,
cv=5,
n_jobs = multiprocessing.cpu_count()
)
model = DecisionTreeClassifier()
model.fit(iris.data, iris.target)
dot_data = tree.export_graphviz(decision_tree=model,
feature_names = iris.feature_names,
class_names = iris.target_names,
filled=True,rounded=True,
special_characters = True)
graph = graphviz.Source(dot_data)
graph
