저번 글에서는 분류의 종류에 대한 간략한 소개와, 그 중에서도 결정트리에 관해 소개했었다. 이번에는 앙상블 학습의 유헝과 그 중에서 대표적인 몇 가지 방법에 대해 알아보도록 할 것이다.
앙상블 학습의 유형은 전통적으로 보팅(Voting), 배깅(Bagging), 부스팅(Boosting)의 세 가지로 나눌 수 있으며, 이외에도 스태킹을 포함한 다양한 기법들이 있다.
오늘은 배깅의 대표적 방법인 Random Forest와 부스팅 중 하나인 GBM에 대해 더 자세히 공부할 것이다.(목차는 저번 CH4.분류의 소분류와 이어진다.)
03. 앙상블 학습
1. 앙상블 학습 개요
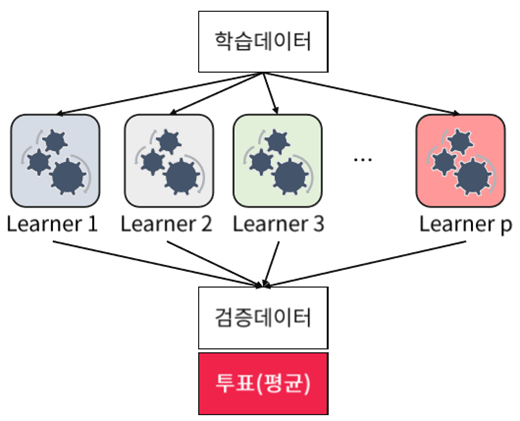
- Ensemble Learning: 여러 개의 분류기(Classifier)를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도축하는 기법
- 마치 집단 지성으로 어려운 문제를 쉽게 해결하는 것처럼
-
목표: 다양한 분류기의 예측 결과를 결합 -> 단일 분류기보다 신뢰성이 높은 예측값 얻는 것
-
대부분의 정형 데이터 분류 시 뛰어난 성능 보임 (이미지, 영상, 음성 등의 비정형 데이터의 분류는 딥러닝이 더 뛰어난 성능)
-
대표적인 앙상블 알고리즘: Random Forest, Gradient Boosting
⇒기존의 Gradient Boosting을 뛰어넘는 새로운 알고리즘 개발
- XGBoost
- LightGBM (XGBoost보다 훨씬 빠른 수행 속도)
- Stacking (여러 가지 모델의 결과를 기반으로 메타 모델을 수립)
-
Ensemble Learning 유형: 전통적으로 Voting, Bagging, Boosting 3가지 + Stacking을 포함한 다양한 앙상블 방법
- Bagging, Boosting은 결정 트리 알고리즘 기반, Voting과 Stacking은 서로 다른 알고리즘을 기반(Ensemble의 한 개념)
- Voting과 Bagging: 여러 개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식
Voting은 서로 다른 알고리즘을 가진 분류기 결합, Bagging은 각각의 분류기가 모두 같은 유형의 알고리즘 기반이지만, 데이터 샘플링을 서로 다르게 가져가면서 학습을 수행해 Voting을 수행하는 것이다. (대표적인 Bagging: Random Forest)
-
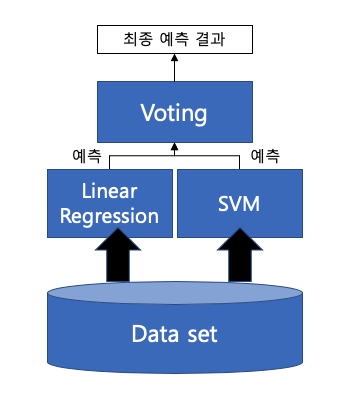
Voting: 다른 ML 알고리즘이 같은 데이터 세트에 대해 학습하고 예측한 결과를 가지고 보팅을 통해 최종 예측 결과 선정
-
Bagging: 단일 ML 알고리즘이 Bootstrapping 방식으로 샘플링된 데이터 세트에 대해서 학습을 통해 개별적인 예측을 수행한 결과를 보팅을 통해 최종 예측 결과 선정
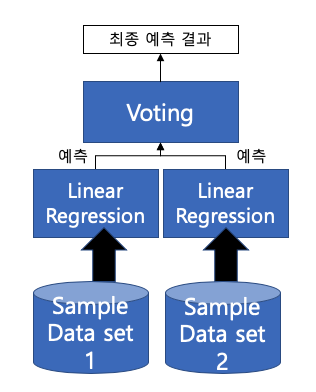
- Bootstrapping 분할 방식: 개별 분류기에게 데이터를 샘플링해서 추출하는 방식, 여러 개의 데이터 세트를 중첩되게 분리하는 것 (Voting 방식과 다름)
- 교차 검증이 데이터 세트 간에 중첩 허용하지 않는 것과 다르게, Bagging은 중첩 허용
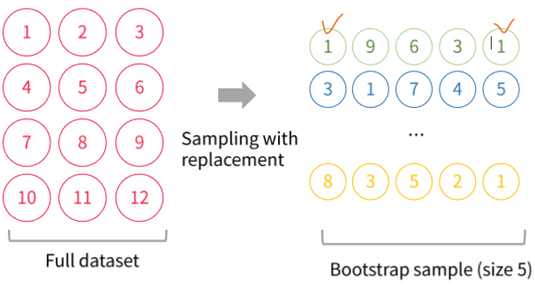
5 size만큼 Bootstrap 실행 (중복 허용, 복원 추출 개념)
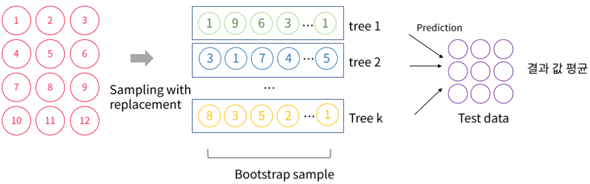
각 분류기 k개만큼 데이터를 샘플링 -> 개별적인 예측을 보팅(결과 값 평균)을 통해 최종 예측 결과 선정
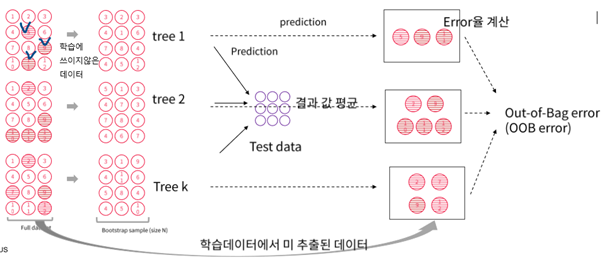
OOB error(Out-of-Bag error): 학습데이터에서 미 추출된 데이터에 대해 각각의 분류기가 예측하고 Error율 계산해서 평균 냄 -> 학습데이터 내에서 미 추출된 데이터를 검증 데이터로 써서 검증데이터에 대한 성능지표를 계산할 수 있는 장점
-
Bagging과 Tree의 차이점
-
Tree: 쉽고 직관적인 분류 기준을 가지고 있지만, Low Bias(정답과 예측값의 거리), High Variance(모델별 예측값 간의 거리) => overfitting 발생
-
Bagging: 위와 같은 문제를 해결하기 위해 모델이 예측한 값의 평균을 사용하여 bias를 유지하고 Variance를 감소, 학습데이터의 noise에 강건해짐, 모형해석의 어려움(단점)
=> 결정 트리 알고리즘의 장점은 그대로 취하고 단점은 보완하면서 bias-variance trade-off의 효과를 극대화할 수 있음
-
- Boosting: 여러 개의 분류기가 순차적으로 학습을 수행하되, 앞에서 학습한 분류기가 예측이 틀린 데이터에 대해서 올바르게 예측할 수 있도록 다음 분류기에게 가중치(weight)를 부여하면서 학습과 예측 진행
- 예측 성능이 뛰어나 앙상블 학습을 주도
- 대표적인 Boosting 모듈: Gradient Boost, XGBoost(eXtra Gradient Boost), LightGBM(Light Gradient Boost)
- Stacking: 여러 가지 다른 모델의 예측 결과값을 다시 학습 데이터로 만들어서 다른 모델(메타 모델)로 재학습시켜 결과를 예측
2. 보팅 유형 – 하드 보팅(Hard Voting)과 소프트 보팅(Soft Voting)
-
하드 보팅: 예측한 결과값들 중 다수의 분류기가 결정한 예측값을 최종 보팅 결과값으로 선정 (다수결 원칙과 비슷)!
-
소프트 보팅: 분류기들의 레이블 값 결정 확률을 모두 더하고 이를 평균해서 이들 중 확률이 가장 높은 레이블 값을 최종 보팅 결과값으로 선정 (일반적인 보팅 방법)
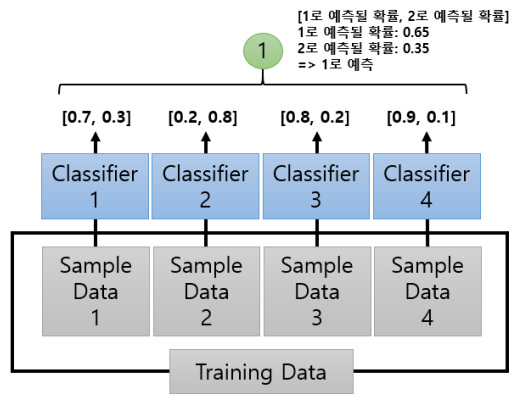
⇒ 일반적으로 하드 보팅보다는 소프트 보팅이 예측 성능이 좋아서 더 많이 사용됨.
04. Random Forest
1. 랜덤 포레스트의 개요 및 실습
- Bagging의 대표적인 알고리즘 Random Forest; 비교적 빠른 수행 속도 + 높은 예측 성능
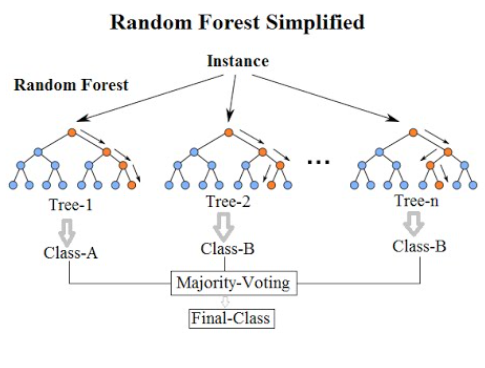
- 여러 개의 결정 트리 분류기가 전체 데이터에서 bagging 방식으로 각자의 데이터를 샘플링 -> 개별적으로 학습 수행 후 최종적으로 모든 분류기가 voting을 통해 예측 결정

-
(X+Y)의 분산이 X와 Y 각각의 분산을 더한 것보다 더 크기 때문에 Bagging Model 자체의 분산이 커질 수 있음
-
공분산이 0이면, 두 변수는 서로 독립적인 관계
-
따라서 Random Forest는 기본 Bagging과 다르게 데이터뿐만 아니라, 변수도 random하게 뽑아서 다양한 모델 만듦 (각 분류기간의 공분산을 줄이는 게 목표)
-
모델의 분산을 줄여 일반적으로 Bagging보다 성능이 좋음
-
뽑을 변수의 수는 hyper parameter(일반적으로 √p 사용, p는 변수 개수)
-
개별적인 분류기의 기반 알고리즘은 결정트리이지만, 개별 트리가 학습하는 데이터세트는 전체 데이터에서 일부가 중첩되게 샘플링된 데이터 세트 (Bootstrapping 방식)
- Bagging: bootstrap aggregating의 줄임말
-
랜덤 포레스트의 Subset 데이터는 Bootstrapping 방식으로 데이터가 임의로 만들어짐
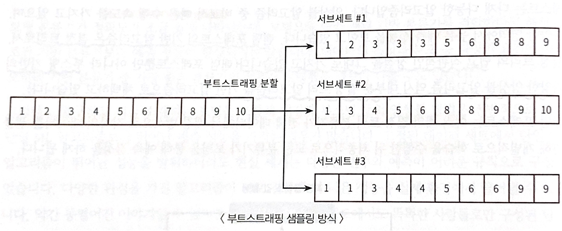
- Subset 데이터의 건수는 전체 데이터의 건수와 동일하지만, 개별 데이터가 중첩되어 만들어짐
- 데이터가 중첩된 개별 데이터 세트에 결정 트리 분류기를 각각 적용 ⇒ 랜덤 포레스트!
- 정리
배깅: 같은 알고리즘으로 여러 개의 분류기를 만들어서 보팅으로 최종 결정하는 알고리즘.
배깅의 대표적인 알고리즘은 랜덤포레스트
랜덤포레스트의 장점: 1. 앙상블 알고리즘 중 비교적 빠른 수행 속도를 가지고 있음
- 다양한 영역에서 높은 예측 성능
- 결정 트리의 쉽고 직관적인 장점 그대로 가지고 있음
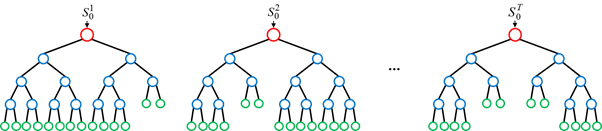
2. 랜덤 포레스트 하이퍼 파라미터 및 튜닝
하이퍼 파라미터란, 일반적으로 머신러닝에서 어떠한 임의의 모델을 학습시킬때, 사람이 직접 튜닝 (설정) 해주어야하는 변수를 말한다.
RandomForest의 단점:
1. 하이퍼 파라미터가 너무 많다
2. 시간이 많이 소모된다
3. 예측 성능이 크게 향상되는 경우가 많지 않다
→ 트리 기반 자체의 하이퍼 파라미터가 원래 많고, 배깅, 부스팅, 학습, 정규화를 위한 하이퍼 파라미터까지 추가되므로 많을 수 밖에 없다.
코드: n_estimators: 결정 트리의 개수 지정/ max_features는 결정트리에 max_features 파라미터와 같음(최적의 분할을 위해 고려할 최대 피처갯수). 기본이 sqrt(전체 피처갯수) / max_depth(트리의 최대 깊이 규정), min_samples_leaf(말단 노드가 되기 위한 최소한의 샘플 데이터 수): 과적합 개선
05. GBM
1. GBM의 개요 및 실습
부스팅 알고리즘: 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치 부여를 하고, 오류를 개선해 나가면서 학습하는 방식
에이다 부스트, GBM 과의 차이: GBM은 가중치 업데이트를 경사하강법을 이용한다.
경사하강법
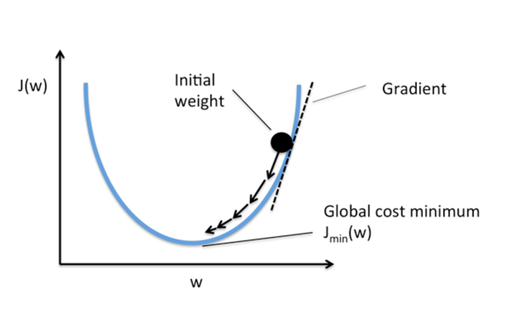
보통 GBM이 랜덤 포레스트 보다는 예측 성능이 뛰어나다. BUT, 수행시간 문제는 GBM이 극복해야할 중요한 과제.
2. GBM 하이퍼 파라미터 및 튜닝
n_estimators: 결정트리갯수/ max_depth:. Max_features: 위와 같이
loss: 경사 하강법에서 사용할 비용 함수 지정
learning_rate: weak learner가 순차적으로 오류값을 보정해 나가는데 적용하는 계수. 범위는 0과 1사이 , 기본값은 0.1, 너무 작은 값: 예측성능은 높아지지만 속도 느림. 너무 큰 값: 예측성능이 떨어지지만 속도는 빠름/
subsample: 학 습에 사용하는 데이터 샘플링 비율 (ex. 0.5 면 학습데이터 50%)
장점: 과적합에도 강한 뛰어난 예측 성능을 가진 알고리즘
단점: 수행시간이 오래걸림


{kind=link}
안녕하세요 :) 댓글남겨주셔서 놀러왔습니다. 회사에서의 제 직무가 Data Scientist & Machine Learning 개발자인데 정말 좋은 포스팅이 많으세요 !! 많이 배워가겠습니다.