
Redis(Remote Dictionary Server)
Redis는 Remote(원격)에 위치하고 프로세스로 존재하는 In-Memory 기반의 Dictionary(Key-Value) 구조 데이터 관리 Server 시스템이다.
Key-Value 구조 데이터란, Mysql 같은 관계형 데이터가 아닌 비 관계형 구조로서 데이터를 키-값 형태로 단순하게 저장하는 구조를 말한다. 관계형 데이터 베이스와 같이 쿼리 연산을 지원하지 않지만, 데이터의 고속 읽기와 쓰기에 최적화 되어 있다. Redis는 NoSQL로 분류되기도 한다.
Redis는 인 메모리(In-Memory) 솔루션으로 분류되기도 하는데, 다양한 데이터 구조체를 지원함으로써 DB, Cache, Message Queue, Shared Memory 용도로 사용될 수 있다. 일반 데이터베이스같이 디스크(ssd)에 데이터를 쓰는 구조가 아니라 메모리(dram)에서 데이터를 처리하기 때문에 작업 속도가 상당히 빠르다.
| 메모리 | RAM | CPU에서 이루어진 연산을 기록하는 메모리 CPU와 하드디스크를 연결시켜주는 장치 |
| 외부 저장 장치 | HDD, SDD | 컴퓨터의 정보, 문서, 자료 등을 저장하고 읽을 수 있는 장치 |
Redis 특징
| Redis 특징 |
|---|
NoSQL DBMS로 분류되며, In Memory 기반의 Key-Value 구조를 가진 데이터 관리 시스템 |
| 메모리 기반이라 모든 데이터들을 메모리에 저장하고 조회에 매우 빠르다. 리스트형 데이터 입력과 삭제가 MySQL에 비해서 10배 정도 빠르다. |
메모리에 상주하면서 서비스의 상황에 따라 데이터베이스로 사용될 수 있으며, Cache로도 사용될 수 있다. |
다양한 자료구조를 지원한다. Strings, Set, Sorted-Set, Hashes, List ... |
| 쓰기 성능 증대를 위한 클라이언트 측 샤딩(Sharding)을 지원한다. ✅ Sharding : 같은 테이블 스키마를 가진 데이터(row)를 다수의 데이터베이스에 분산하여 저장하는 방법 |
메모리 기반이지만 Redis는 영속적인 데이터 보존(Persistence)이 가능하다. |
스냅샷 기능을 제공해 메모리 내용을 *.rdb 파일로 저장하여 해당 시점으로 복구할 수 있다. |
[원자성], 여러 프로세스에서 동시에 같은 Key에 대한 갱신을 요청하는 경우, 데이터 부정합 방지 Atomic 처리 함수를 제공한다. |
Redis는 기본적으로 1개의 싱글 쓰레드로 수행되기 때문에, 안정적인 인프라를 구축하기 위해서는 Replication(Master-Slave 구조)이 필수이다. |
Redis 활용 - 캐시(Cache)
캐시(Cache)란 ❓
Cache란 한번 조회된 데이터를 미리 특정 공간에 저장해놓고, 똑같은 요청이 발생하게 되면 서버에게 다시 요청하지 말고 저장해놓은 데이터를 제공해서 빠르게 서비스를 제공해 주는 것을 의미한다.
즉, 미리 결과를 저장하고 나중에 요청이 오면 그 요청에 대해서 DB 또는 API를 참조하지 않고 Cache를 접근하여 요청을 처리하는 기법이다.
서비스를 처음 운영할 때는 WEB-WAS-DB 정도로 작게 인프라를 구축하는데, 사용자가 늘어나면 DB에 무리가 가기 시작한다. DB는 데이터를 물리 디스크에 직접 쓰기 때문에 서버에 문제가 발생해도 데이터가 손실되지는 않지만, 매 트랜잭션마다 디스크에 접근해야 하므로 부하가 많아지면 성능이 떨어진다. 그래서 사용자가 늘어나면 DB를 스케일 업 또는 스케일 아웃하는 방식 외에도 캐시 서버를 검토하게 된다.
Redis Cache는 메모리 단 (In-Memory)에 위치한다. 따라서 용량은 작지만 접근 속도가 빠르다. 다만 저장하려는 데이터 셋이 주어진 메모리 크기보다 크면 디스크를 쓰는 것이 올바른 선택이다.
캐시의 구조 패턴
Look aside Cache 패턴
캐시를 사용하는 패턴은 첫 번째로 Look aside Cache 패턴이다. 앞서 말한 일반적인 캐시 정의를 그대로 구현한 구조이다. look aside cache는 캐시를 한 번 접근하여 데이터가 있는지 판단한 후, 있다면 캐시의 데이터를 사용하고 없으면 실제 DB 또는 API를 호출한다.
Look aside Cache 쿼리 순서
-
클라이언트에서 데이터 요청
-
서버에서 캐시에 데이터 존재 유무 확인
-
데이터가 있다면 캐시의 데이터 사용 (빠른 조회)
-
데이터가 없다면 실제 DB 데이터에 접근
-
그리고 DB에서 가져온 데이터를 캐시에 저장하고 클라이언트에 반환

✅ 참고
Cache Miss: 메모리에 찾고자 하는 데이터가 없어서 디스크에 조회할 때Cache Hit: 메모리에 찾고자 하는 데이터가 있을 때
Write Back 패턴
write back은 주로 쓰기 작업이 굉장히 많아서, INSERT 쿼리를 일일이 날리지 않고 한꺼번에 배치 처리를 하기 위해 사용한다. 예를 들어 시험을 온라인으로 진행하는 서비스가 있을 때, 여러 학생이 동시에 제출 버튼을 누르면서 DB에 갑작스럽게 엄청난 쓰기 요청이 몰리게 되면 DB 서버가 죽을 수도 있다. 이때 write back 기반의 캐시를 사용하면 캐시 메모리에 데이터를 저장해 놓고, 이후 DB 디스크에 업데이트해 주면 안전하게 쓰기 작업을 이행할 수 있는 것이다.
즉, insert를 1개씩 500번 수행하는 것보다 500개를 한 번에 삽입하는 동작이 훨씬 빠르기 때문에 write back 방식은 빠른 속도로 서비스가 가능하다.
단점
DB에서 디스크를 접근하는 횟수가 줄어들기 때문에 성능 향상을 기대할 수 있지만, DB에 데이터를 저장하기 전에 캐시 서버가 죽으면 데이터가 유실된다는 문제점이 있다. 그래서 다시 재생 가능한 데이터나, 극단적으로 heavy 한 데이터에서 write back 방식을 많이 사용한다. 예를 들면 로그를 캐시에 저장하고 특정 시점에 DB에 한 번에 저장하는 경우가 있다.
write back 쿼리 순서
-
우선 모든 데이터를 캐시에 싹 저장
-
캐시의 데이터를 일정 주기마다 DB에 한꺼번에 저장 (배치)
-
그리고 나선 DB에 저장했으니 잔존 데이터를 캐시에서 제거
Redis는 특히 Remote Dictionary로서 RDBMS의 캐시 솔루션으로 사용 용도가 굉장히 높다. 일반적으로 데이터베이스는 저장 장치에 저장이 되는데, 데이터베이스를 조회하려면 저장 장치로 i/o가 발생하게 된다. RDBMS에서 SELECT 쿼리문을 날려 특정 데이터들을 FETCH 했을 때, RDBMS의 구조상 DISK에서 데이터를 꺼내오는 데 Memory에서 읽어들이는 것보다 천 배가량 더 느리다.
예를 들어 데이터베이스에 접근하여 10,000개의 레코드를 읽는다고 가정했을 때 disk에 저장되어 있다면 약 30초의 시간이 걸리는 반면 RAM에서 읽을 경우엔 약 0.0002초 밖에 걸리지 않는다.
따라서 Redis 같은 유연한 자료구조를 가지는 인 메모리 Key-value 솔루션을 사용하여 DB 부하의 Read 연산의 부하를 분산시키는 데 적용한다. 캐시는 in-memory 방식을 활용하여 데이터를 임시로 저장해두기 때문에 저장 장치의 i/o보다 훨씬 빠르게 동작할 수 있다. 그래서 자주 사용하는 데이터는 캐시 서버에서 우선 조회하고 없을 때는 데이터베이스를 다시 조회하는 방식을 활용하면 전체적인 서비스의 속도를 향상시킬 수 있다.
또, 하드한 작업 같은 경우 쿼리문이 길고 복잡해 기본적으로 데이터베이스를 조회하는 시간이 오래 걸리는데, 만일 이 쿼리가 자주 사용되는 경우라면 해당 쿼리가 전체 서비스 속도의 병목이 될 수 있다. 그럴 때는 쿼리 결과 자체를 Redis로 캐싱을 해두고, 쿼리의 결과가 바뀔 수 있는 이벤트가 발생할 때마다 캐시에 적재를 새로 한다면 전체 서비스 속도를 향상시킬 수도 있다. 그래서 캐싱이 필요할 때 많이 사용되는데 즉시 메시지를 주고받아야 될 때나, 장바구니의 삭제와 같은 경우에 많이 사용하는 편이다.
또한 RAM은 휘발성인데 그럼 실행 중인 Redis를 끄면 데이터가 전부 날아간다고 생각이 들게 되는데, Redis는 in-memory이지만 persistent on-disk 데이터베이스 이기도 하다. Redis는 특정한 때에 현재까지의 in-memory 상태를 disk에 저장해 두었다가 Redis를 다시 시작했을 때 disk에 저장해 두었던 dump 파일들을 load 하기 때문에 데이터의 손실 발생을 방지할 수도 있다.
Redis 주의해야 할 점
시간 복잡도
레디스는 자바스크립트와 같이 싱글 쓰레드 기반으로 돌아간다. 그래서 한 번에 딱 하나의 명령어만 실행하기 때문에, 긴 처리시간이 필요한 명령어를 쓰면 불리하고 요청 건을 처리하기 전까지 다른 서비스 요청을 받아들일 수 없고 서버가 다운되는 현상이 일어날 수 있다. 따라서 전체 데이터를 다루는 시간 복잡도를 가진 O(N) 명령어 keys flush getall는 주의해서 사용할 필요가 있다.
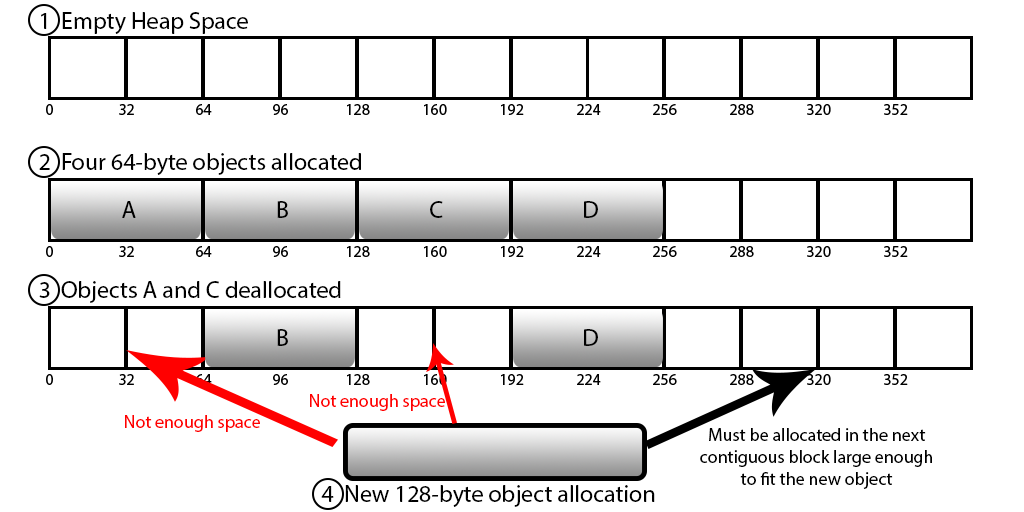
메모리 파편화
메모리를 할당받고 해제하는 과정에서 아래 그림과 같이 부분 부분 빈 공간이 생기게 되는데, 4번같이 새로운 메모리를 할당할 때 알맞은 공간(4칸)이 없기 때문에 마지막 부분(우측) 부분에 프로세스가 위치해야 되고, 그러면 빈 공간 메모리가 남아 낭비가 발생하게 된다. 이 현상이 계속되면 실제 physical 메모리가 커져 프로세스가 죽는 현상이 발생할 수도 있다.
또한 쓰기 연산이 copy on wirte 방식으로 동작하기 때문에 최대 메모리를 2배 이상까지 사용하기도 한다. 그래서 redis를 사용할 때 메모리를 적당히 여유 있게 사용하는 것이 좋다.
Redis Key
Redis의 키는 문자열이기 때문에 abc부터 JPEG 파일까지 모든 이진 시퀀스를 키로 사용할 수 있다. 빈 문자열도 키가 될 수 있다. string 타입과 마찬가지로 허용되는 최대 키 크기는 512MB다.
키를 조회할 때의 비용을 생각하면, 키를 너무 길게 사용하는 것은 권장하지 않는다. 만약 그런 키를 저장해야 한다면 차라리 hash의 member로 저장하는 것이 더 좋은 방법이다. 하지만 그렇다고 해서 가독성이 좋은 user:1000:followers를 u1000flw로 줄이는 건 그다지 의미 있지는 않다.
레디스의 키를 잘 설계하는 것도 중요하다. 어떻게 키를 생성하느냐에 따라 분산이 몰릴 수도, 아닐 수도 있게 된다. 보통 스키마를 사용해서 레디스의 키를 설계하는 것이 좋은데, 예를 들어 user:1000 처럼 object-type:id의 형태를 권장한다. comment:reply.to 또는 comment:reply-to와 같이 ., -, : 등의 부호를 사용해서 관계를 나타낼 수 있다.
키에 대한 커맨드는 데이터 타입에 국한되지 않고 사용할 수 있다. SORT는 입력된 키에 해당하는 아이템을 정렬하여 보여준다. 기존에 정렬되지 않은 상태로 저장된 set 같은 경우, 커맨드를 이용한 정렬이 가능하므로 유용하게 사용될 수 있다. EXISTS 커맨드는 해당 키가 레디스에 있는지 확인하고, DEL 커맨드는 값에 관계없이 키를 삭제한다. TYPE 커맨드는 해당 키에 연결된 자료구조가 어떤 형태인지 반환한다.
Expire 기능
레디스를 사용하려면 Expire 기능에 대해 알고 있어야 한다. 레디스는 in-memory DB인 만큼, 메모리에 저장될 수 있는 데이터는 한정적이다. 더 이상 메모리에 데이터를 저장할 수 없는 경우 레디스에서는 가장 먼저 들어온 데이터를 삭제하거나, 가장 최근에 사용되지 않은 데이터를 삭제하거나, 혹은 더 이상 데이터를 입력받지 못하게 된다.
가장 좋은 방법은 삭제되는 데이터를 레디스가 선택하도록 맡기지 않고, 직접 설정하는 것이다. 데이터를 입력할 때 이 데이터의 사용 기한이 언제까지인지를 직접 설정해 줌으로써, 애플리케이션이 직접 해당 데이터가 삭제되는 타이밍을 제어할 수 있게 된다. 간단히 키에 대한 timeout을 설정하는 것이다. 설정된 timeout 시간이 경과하면 키에 대해 DEL 명령어를 호출한 것처럼 키가 자동으로 삭제된다. 몇 초 뒤에 삭제되어야 하는지를 입력하거나, 혹은 유닉스의 timestamp를 이용하여 삭제되어야 하는 시각을 정확하게 설정할 수도 있다.
동일한 키가 다시 들어오면 이 timeout은 재설정된다. 따라서 자주 사용되는 데이터는 계속 남아있고, 사용되지 않는 데이터는 설정한 시간에 따라 삭제된다. 따라서 레디스를 사용하실 때, 모든 키에 expire 값을 추가하는 것을 권장한다. 물론 너무 짧은 시간은 레디스에 오히려 부하를 줄 것이고, 너무 길다면 이 기능에 대한 의미가 없게 되니, 적절한 timeout 시간을 고려해야 한다.
참고 자료
