wandb sweeps
허깅페이스의 trainer는 wandb logging을 매우 쉽게 제공한다. 터미널에서 wandb login만 한다면 TrainingArguments의 report_to 인자에 wandb만 넣으면 된다.
그렇다면 wandb sweeps를 이용한 하이퍼파라미터 튜닝은 어떻게 할까?
먼저, 위와 같이 wandb logging 환경이 세팅되었다면 .yaml파일이 필요하다.
program: train.py
method: bayes
metric:
name: eval/micro f1 score
goal: maximize
parameters:
learning_rate:
values: [1e-5,5e-5]
batch_size:
values: [8, 64]
epoch:
value: 1
weight_decay:
value: 0.01파일 내용은 대략적으로 위와 같이 작성한다. 학습을 실행하는 파일명을 제일 먼저 입력한 뒤, 하이퍼 파라미터 튜닝의 방법을 bayes, random, grid 중에 선택하면 된다.
Sweep Methods

그 다음 원하는 metric의 이름과 목표를 설정한다. 마지막으로 튜닝하고자 하는 하이퍼파라미터들을 values, 또는 value 인자에 주면 끝이다.
sweep을 실행하기 이전에, project name을 까먹지 말자.
export WANDB_PROJECT="project name"Bayesian Method
그렇다면 Bayesian Method로 한다는 말은 무슨 뜻일까?
흔히들 알고 있듯이 Bayesian Rule이란 아래와 같다.
P(X) : the probability of observing this new evidence.
P(X|Y) : the probability of observing the new evidence X given the event Y that we care about.
P(Y) : the initial hypothesis about the event Y that we care about (treat it like an initial belief about the event Y).
이 때, 우리의 하이퍼파라미터 튜닝을 Bayesian Rule과 같이 생각하면 아래와 같다.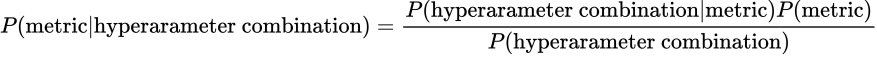
우리는 어떠한 하이퍼 파라미터가 주어졌을 때, metric을 Minimize/ Maximize하는 확률이 높도록 만들어야 한다.
P(hyperparameter combination | metric) is the probability of a certain hyperparameter combination if the given metric is minimized/maximized.
P(metric) is the initial metric quantity in scalar.
P(hyperparameter combination) is the probability of getting that particular hyperparameter combination.
따라서 확률을 기반으로 하이퍼 파라미터 조합을 생각하기에 좀 더 효율적인 튜닝을 진행할 수 있다. 자세한 사항은 좀 더 알아봐야 할 것 같다.
