Sequential Model
Markov Model
현재 일어나는 일은 바로 직전의 일에만 관련이 있다고 가정. (현실적이지는 않음)

많은 정보를 버리게 된다. 가장 큰 장점은 Joint Distribution을 설명하는데 편리하다는 장점이 있다.
Latent AutoRegressive Model
H(hidden state)가 과거의 정보를 담고 있고 현재 시점에서 H의 영향을 받는다.
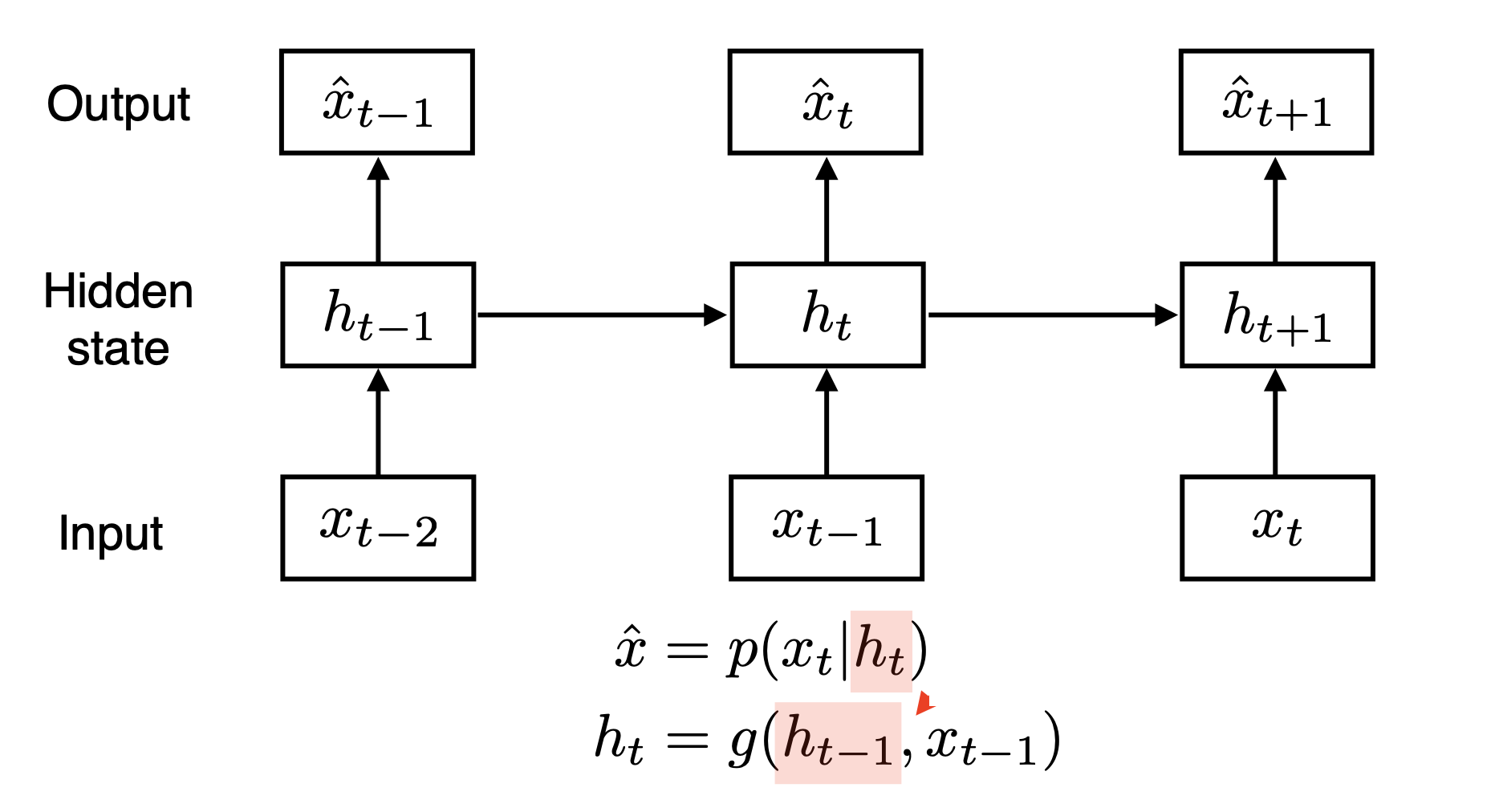
Recurrent Neural Network
가장 큰 차이는 자기 자신으로 돌아온다는 것, 시간 순으로 풀어보면 이전 스텝에서 나온 정보와 현재 스텝에서의 입력데이터로 계속 학습을 하는 형태이다. 그리고 이 모양이 사실 Fully Connected Layer의 형태라고 볼 수 있다. 가장 기본적인 RNN모델을 Vanilla-RNN이라고 부르기도 한다.
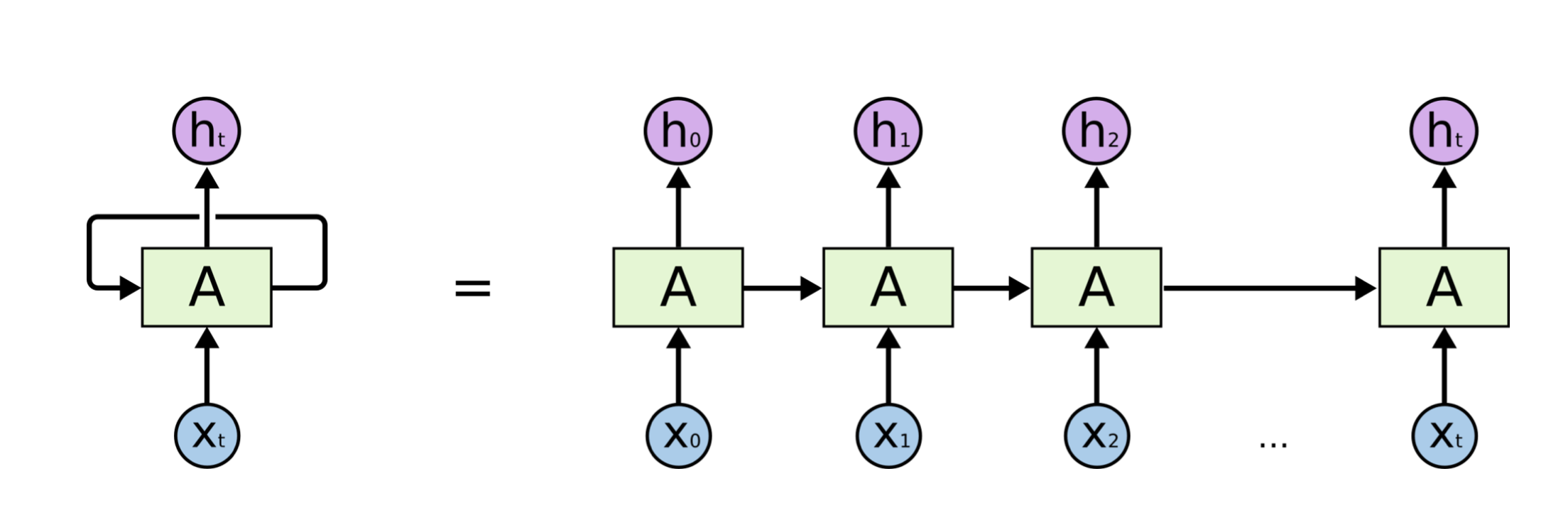
단점
-
Long Term Dependencies
과거의 먼 정보는 미래까지 전달되기 어려움. -
Sigmoid/ ReLU 어떤 activation function에서도 문제
sigmoid는 0-1 사이의 값을 스텝이 지나는 만큼 계속 곱해져 기울기 소실, ReLU라면 임의의 양수 범위에서 스텝이 지나는 만큼 계속 곱해져 기울기 증폭의 문제가 생긴다.
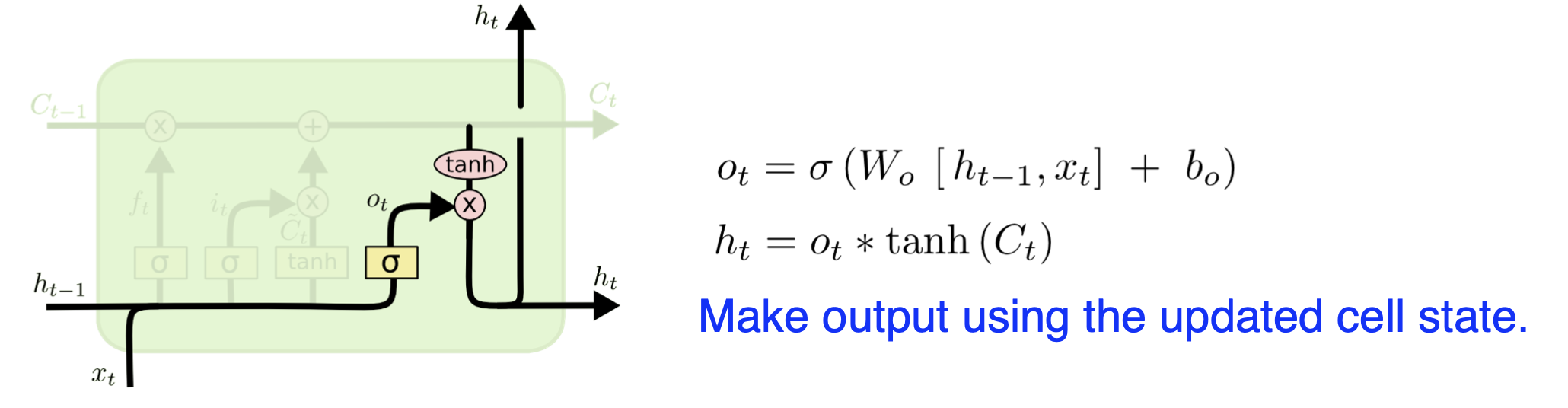
LSTM(Long Short Term Memory)
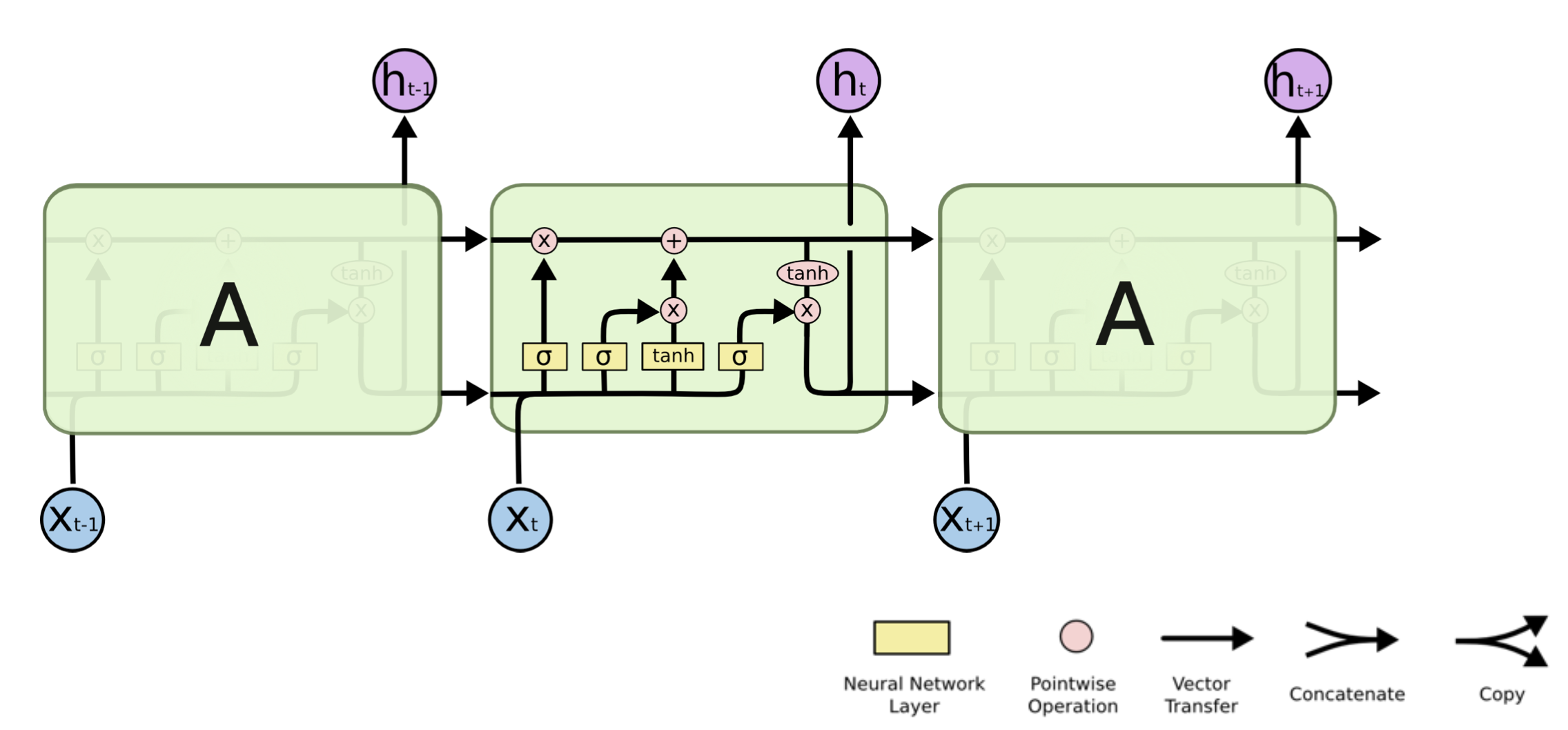
X_t : input data
h_t : Output(Hidden State)
Previous Cell State : 내부적으로만, 밖으로 나가지 않고 0~t-1시점의 정보를 취합해서 전달하는 역할
Previous Hidden State : 이전 시점의 Hidden State
Three Important Gates
Forget Gate

Input Gate

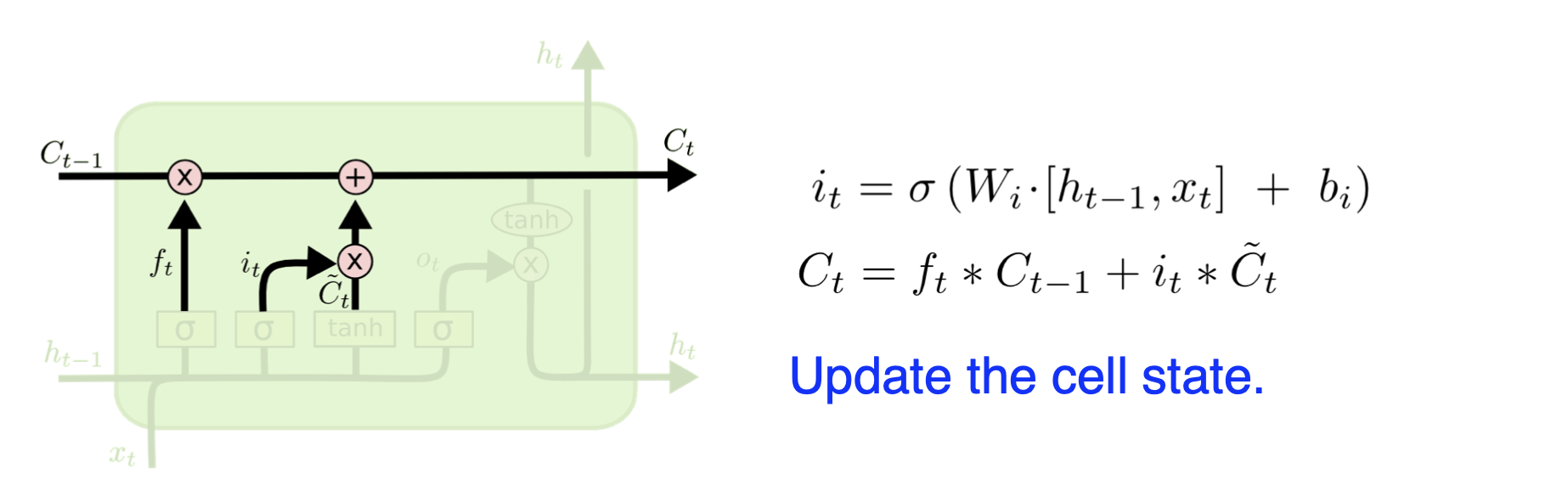
Update Cell
Output Gate
GRU(Gated Recurrent Unit)
LSTM과 비교했을 때 Cell State가 없고 Hidden State만 사용해서 파라미터 수가 더 적고 성능이 더 좋을 수 있다.
Further Question.
- LSTM에서는 Modern CNN 내용에서 배웠던 중요한 개념이 적용되어 있습니다. 무엇일까요?
DenseNet, ResNet 등의 CNN 모델에서 사용했던 Concatenate, Skip-connection 등의 개념이 들어가 있다.
- Pytorch LSTM 클래스에서 3dim 데이터(batch_size, sequence length, num feature), batch_first 관련 argument는 중요한 역할을 합니다. batch_first=True인 경우는 어떻게 작동이 하게되는걸까요?
Batch_first=True 인자를 통해 데이터 I/O의 순서를 바꿔줄 수 있다. Batch_first=True라면 Batch 사이즈 값이 가장 먼저 오게되고, False라면 Sequence Length가 먼저 들어오게 된다.
Transformer
Transformer는 LSTM이후 Sequential Model의 판도를 뒤집어버린 현재로써는 전무후무한 모델이다. 대표적인 언어 모델인 BERT나 GPT도 모두 Transformer를 기준으로 하고 있고, 이에 따라 Transformer에 대한 확실한 이해가 필요하다.
Transformer논문 : Attention is All you Need
Sequential Model
왜 Sequential model은 어려울까?
Sequential model은 다양한 문제들이 생길 수 있기 때문
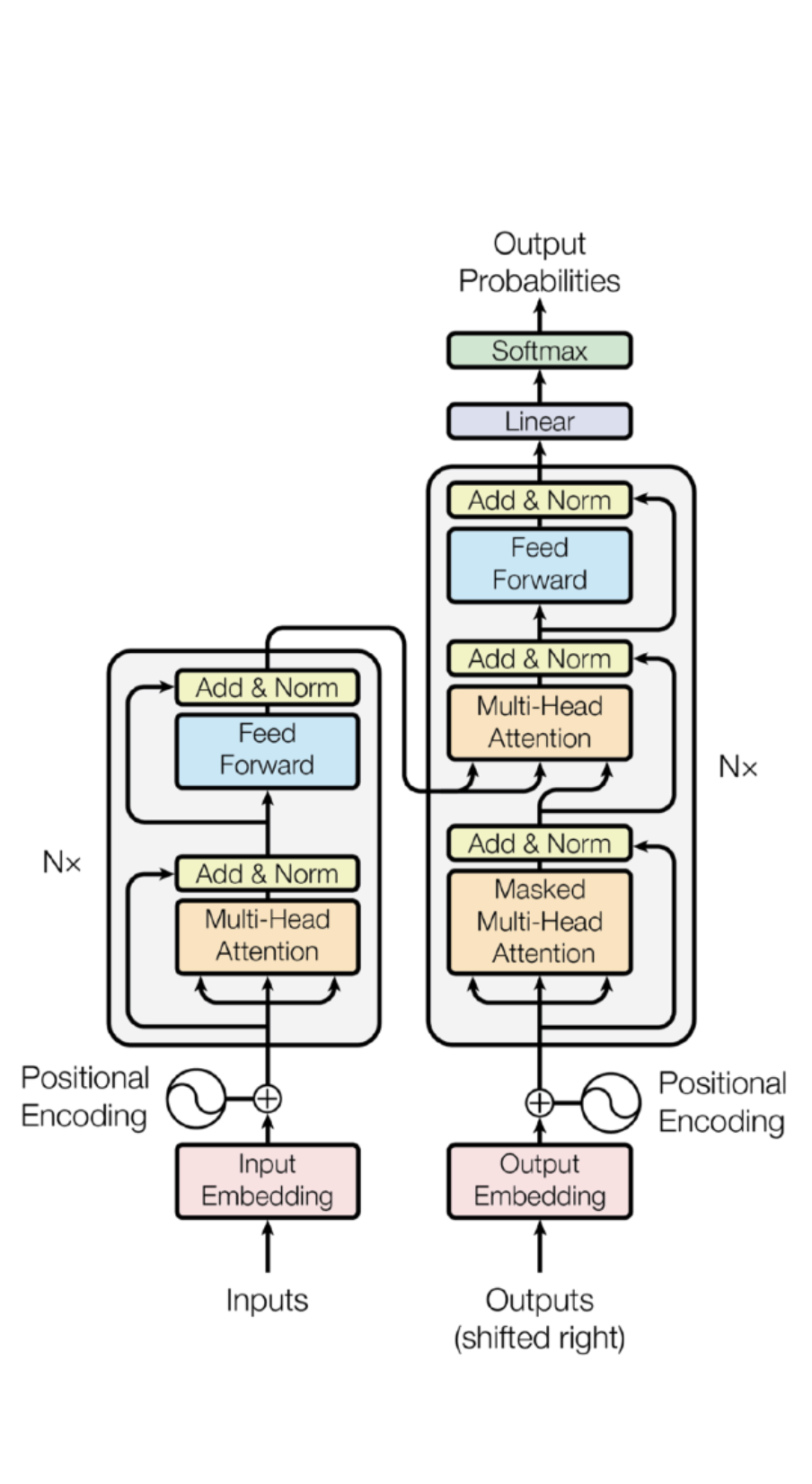
Transformer의 구조도
Transformer is the first sequence transduction model based entirely on attention.
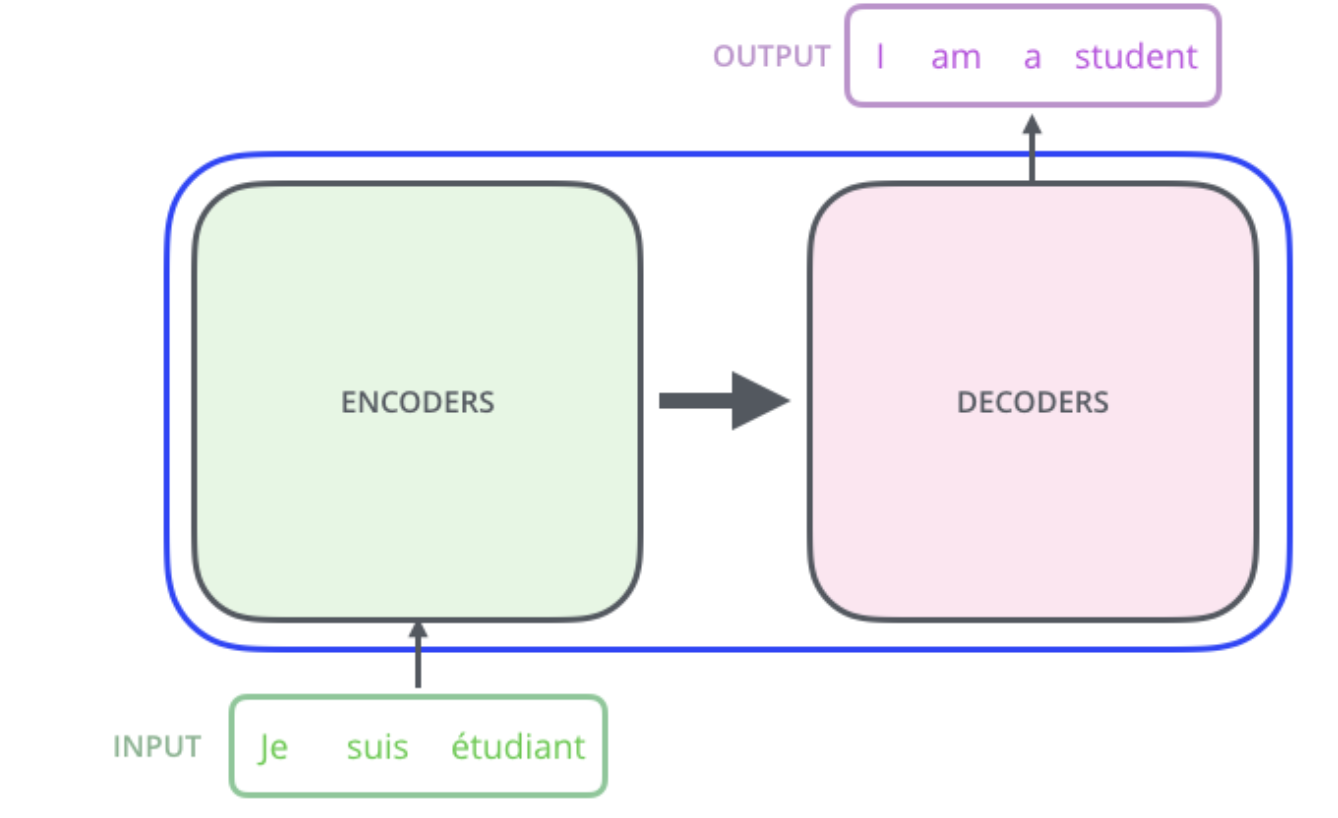
Transformer가 하고 싶은 것은 아래와 비슷하다.Input Sentence를 Encoding하고 Decoding해서 Ouput Sentence를 만들어내는 것이다. 이를 Seq2Seq모델이라고 한다.
입력과 출력은 데이터 길이도 다르고, 도메인도 다 다르다.
목표
- n개의 단어가 어떻게 인코더에서 처리되는지
- 그렇다면 인코더와 디코더 사이에는 어떤 정보들을 전달받으며
- 디코더가 어떻게 생성해낼 수 있는지
Transformer Process(Single Headed Attention)
인코더는 기존 RNN과 달리 한 번에 n개의 단어를 모두 입력받아 처리한다. Self-Attention 과 FeedForward Network(MLP와 동일)를 거쳐서 나오는 형태로 이루어져 있다.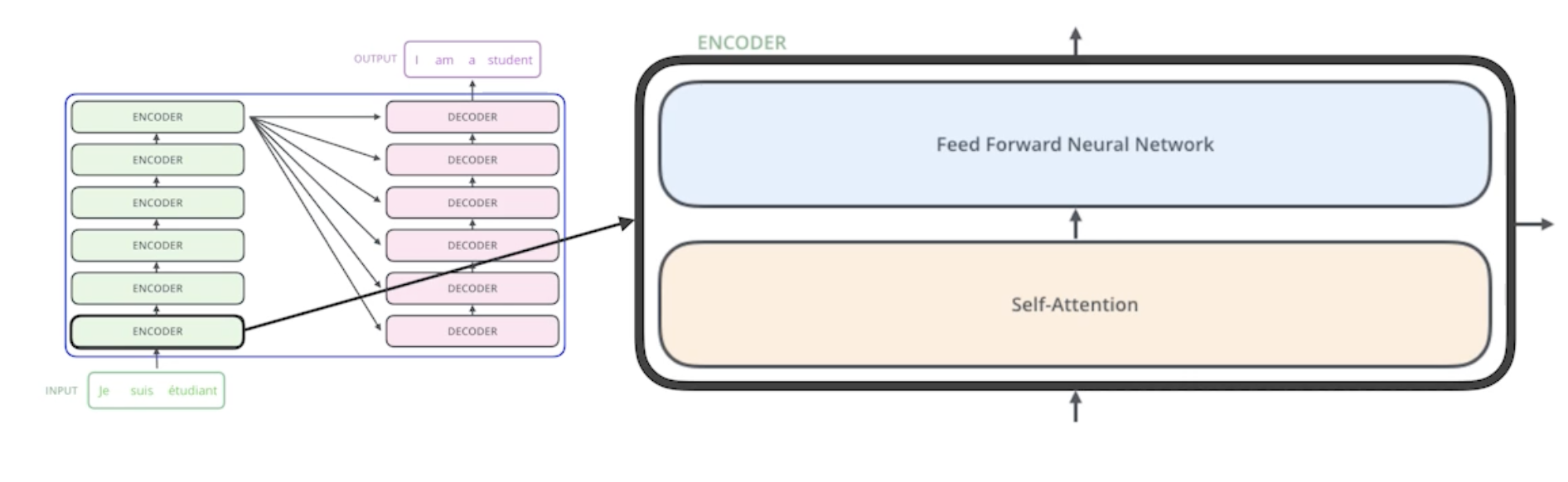
1.
먼저, 아래와 같은 입력 데이터를 받았다고 하자.

우리는 일련의 방법들로 위의 세 단어를 Embedding Vector로 변환시킬 수 있고, 따라서 우리는 단어 수 만큼의 Word Vector를 가지게 된다.
2.
이 때 우리는 Self-Attention을 거쳐 각각 z1,z2,z3를 출력하는데, 한 단어의 정보에서 나오는 것이 아니라 다른 단어들의 정보를 활용하여 Dependency를 가지게 된다.
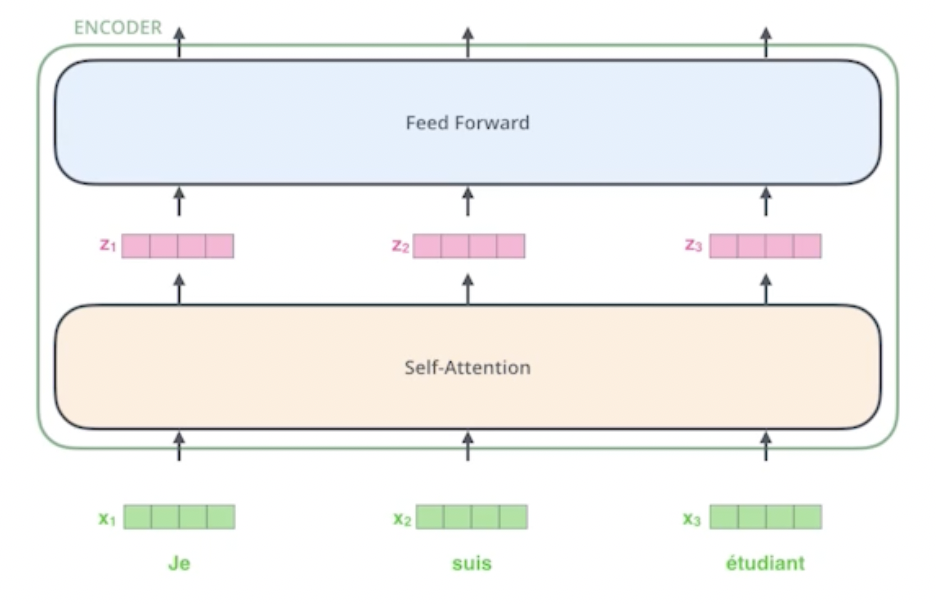
3.
Self-Attention
self-attention은 아래 그림에서 'it'이 의미하는 바를 단어들간의 관계를 통해 알아낸다.

Self-attention은 세 가지 NN를 거쳐서 세 가지 결과를 만들어내는데, 각각 Queries, Keys, Values이다. Query와 key는 같은 사이즈를 가져야하며, 각각의 Q,K,V를 만드는 가중치 행렬은 모든 단어에 Share 된다.
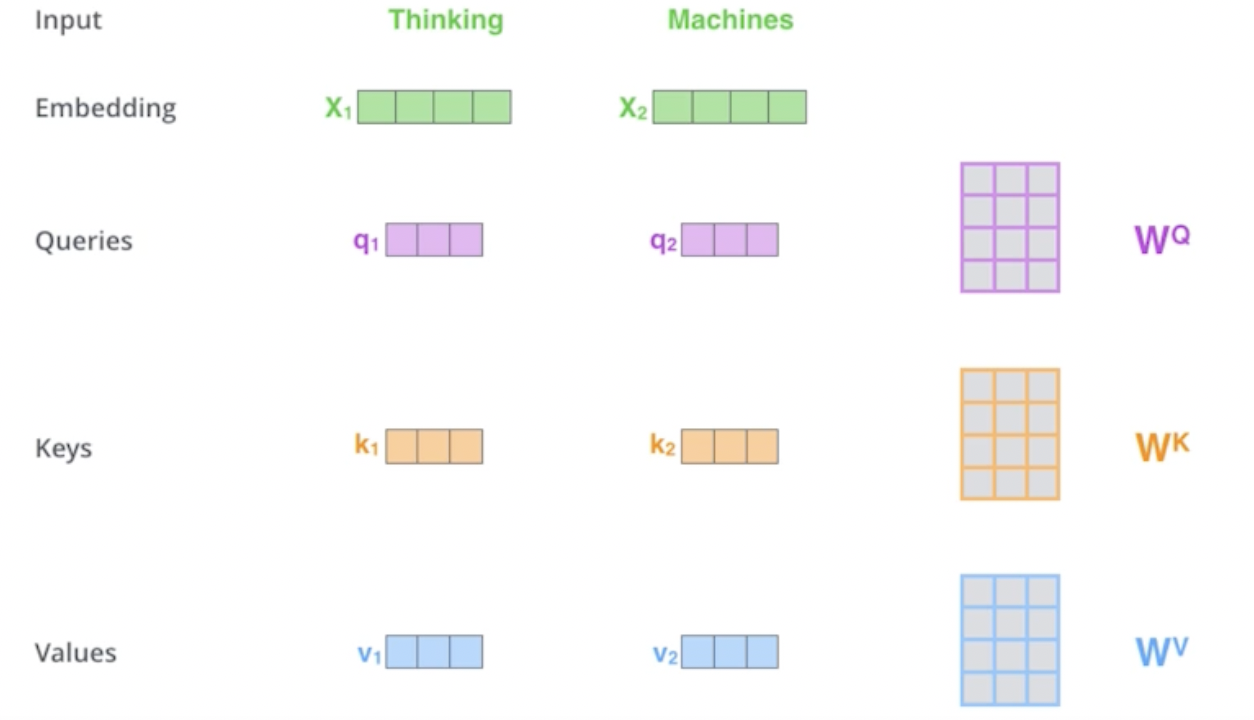
즉, 하나의 단어 벡터가 들어오면 각 단어마다 세 개의 벡터를 만들어낸다. 즉, x1이라는 벡터를 새로운 벡터로 바꿔줄 수 있다는 뜻이다.
4.
Score
우리는 i번 째 단어 에 대한 Score값을 i번째 단어의 Query벡터와 다른 단어의 Key벡터의 내적으로 구하게 된다. 두 가지 입력 벡터 x1, x2에 대하여 각각 [q1,k1,v1][q2,k2,v2]가 만들어 졌을 때, 스코어는
라고 할 수 있다.(i번째 단어에 대해 Attention을 주는 것이다)
그 다음 dimension of k의 sqrt로 나눠준 다음 Softmax함수를 통한 값을 계산하고, Softmax함수로 나온 결과값에 values를 곱해서 모두 더한 값(Weighted Sum)이 곧 z1이라는 인코딩 벡터를 만들어내게 되는 것이다.
5.
여기까지의 과정을 그림으로 나타내면 다음과 같이 나타낼 수 있다.

왜 Transformer의 성능이 좋을까?
이미지를 예로 들면, CNN이나 MLP에서 input이 고정되면 출력이 고정된다. 그러나 Transformer는 하나의 인풋이 고정되어있다 하더라도 주변의 단어에 따라 Encoding한 값이 달라질 것이고, 따라서 MLP보다 좀 더 Flexible한 모델이고, 더 많은 모델을 표현할 수 있는 것이다.
하지만 Transformer는 RNN과 달리 n개의 단어가 주어지면 n X n attention map을 만들어야한다. 1,000개의 단어라면 1,000,000번의 연산이 필요하고 Computational 한계가 있다(단점). 대신 훨씬 더 Flexible하다는 강력한 장점.
Multi Head Attention
1.
위의 Transformer를 여러번 진행하는 것이 바로 Multi Head Attention이다. 즉, 아래 그림과 같이 Q,K,V를 여러개 만드는 것이다.
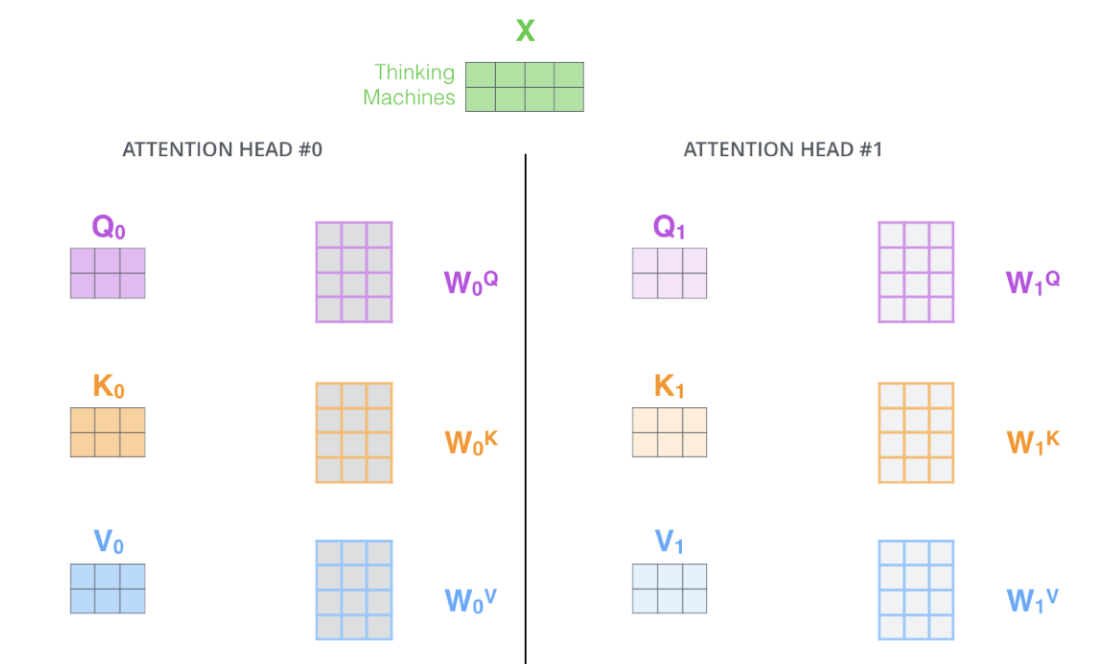
2.
N개의 Attention Head라고 한다면 이로 부터 N개이 z값이 출력될 것이고 이에 따라 출력 Dimension이 커지게 된다. 우리는 입력과 출력(Attention Head)의 Dimension을 맞춰주기 위해서 추가적인 행렬 곱(Additional(Learnable) Linear Map)을 통해 차원 수를 조정할 수 있다. 아래의 그림이 MHA를 잘 설명하고 있다.(실제 구현과는 다소 다를 수도 있다.)

3.
MHA는 추가적으로 Positional Encoding이 추가된다. 쉽게 생각하면 Input Data에 Bias를 추가하는 것이다.
왜 Positional Encoder가 필요할까?
n개의 단어가 Sequential하다는 정보가 없기때문이다. 실제 Transformer의 구조에서 계산 시에 순서(order)는 중요하지 않았다. Pre-defined된 값을 추가하는 형태로 진행한다.
2020년 Positional Encoding의 값이 조금 바뀌었다고 한다.
4.
Further Question.
Vision Transformer(VIT)
이미지에 Transformer의 Encoder를 활용해서 분류하는 모델이다.
DALL-E
이미지에 Transformer의 Decoder를 활용해서 생성하는 모델이다.
