RNN(Recurrent Neural Network)
RNN,순환 신경망은 시퀀스 데이터들을 처리하기 위해 고안된 모델들 중 하나다. RNN은 그 중에서 가장 기본적인 딥러닝 시퀀스 모델이다. 나중에 배우게 될 LSTM이나 GRU또한 근본적으로 RNN에 속한다.
- MLP은 전부 은닉층에서 활성화 함수를 지난 값이 오직 출력층 방향으로만 향했다(피드 포워드 신경망). 그러나 RNN은 은닉층의 노드에서 활성화 함수를 통해 나온 결과값을 출력층 방향으로도 보내면서, 다시 은닉층의 다음 계산의 입력으로 보내는, 순환적인 특징을 갖고 있다.

NN에서 은닉층에서 활성화 함수를 통해 결과를 내보내는 역할을 하는 노드를 셀(cell)이라고 한다(위 그림의 h). 이 셀은 이전의 값을 기억하려고 하는 일종의 메모리 역할을 수행하므로 이를 메모리 셀 또는 RNN 셀이라고 표현한다. 은닉층의 메모리 셀은 각각의 시점(time step)에서 바로 이전 시점에서의 은닉층의 메모리 셀에서 나온 값을 자신의 입력으로 사용하는 재귀적 활동을 하고 있다. 현재 시점을 변수 t로 표현하고, 이는 현재 시점 t에서의 메모리 셀이 갖고있는 값은 과거의 메모리 셀들의 값에 영향 받은 값임을 의미한다.
메모리 셀이 출력층 방향으로 또는 다음 시점 t+1의 자신에게 보내는 값을 은닉 상태(hidden state)라고 한다. 다시 말해 t 시점의 메모리 셀은 t-1 시점의 메모리 셀이 보낸 은닉 상태값을 t 시점의 은닉 상태 계산을 위한 입력값으로 사용한다.
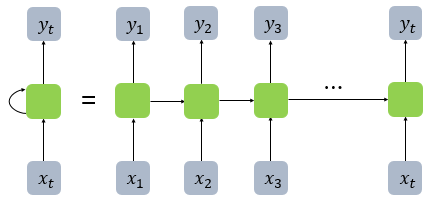
피드 포워드 신경망에서는 뉴런이라는 단위를 사용했지만, RNN에서는 뉴런이라는 단위보다는 입력층과 출력층에서는 각각 입력 벡터와 출력 벡터, 은닉층에서는 은닉 상태(Hidden State)라는 표현을 주로 사용한다. 위의 그림에서 회색과 초록색으로 표현한 각 네모들도 기본적으로 벡터 단위를 가정하고 있다. 피드 포워드 신경망과의 차이를 비교하기 위해서 RNN을 뉴런 단위로 시각화해보면 다음과 같다.
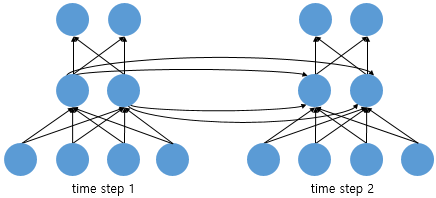
위의 그림은 입력 벡터의 차원이 4, 은닉 상태의 크기가 2, 출력층의 출력 벡터의 차원이 2인 RNN이 시점이 2일 때의 모습을 보여준다. 다시 말해 뉴런 단위로 해석하면 입력층의 뉴런 수는 4, 은닉층의 뉴런 수는 2, 출력층의 뉴런 수는 2이다.

RNN은 입력과 출력의 길이를 다르게 설계 할 수 있어서 다양한 용도로 사용할 수 있다. 위 그림은 입력과 출력의 길이에 따라서 달라지는 RNN의 다양한 형태를 보여준다.
자연어 처리에서 RNN 셀의 각 시점 별 입력/출력의 가장 보편적인 단위는 '단어 벡터'이다.
RNN 수식 정의
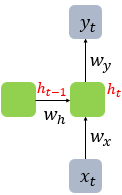
현재 시점 t에서의 은닉 상태값을 라고 정의하자. 은닉층의 메모리 셀은 를 계산하기 위해서 총 두 개의 가중치를 갖게 된다. 하나는 입력층에서 입력값을 위한 가중치 이고, 하나는 이전 시점 t-1의 은닉 상태값인 을 위한 가중치 입니다.
이를 식으로 표현하면 다음과 같습니다.
은닉층 :
출력층
단, 는 비선형 활성화 함수 중 하나.
RNN에서 활성화 함수로 tanh를 많이 쓰는 이유
RNN의 은닉층 연산은 벡터와 행렬 연산으로 이해할 수 있다. 자연어 처리에서 RNN의 입력 는 대부분의 경우에서 단어 벡터로 간주할 수 있는데, 단어 벡터의 차원을 라고 하고, 은닉 상태의 크기를 라고 하였을 때 각 벡터와 행렬의 크기는 다음과 같다.
위 수식을 간단하게 그림으로 표현한다면 아래와 같다.

위의 식에서 각각의 가중치 값들은 모든 시점에서 값을 동일하게 공유한다. 만약, 은닉층이 2개 이상일 경우에는 은닉층 2개의 가중치는 서로 다르다.
출력층은 결과값인 를 계산하기 위한 활성화 함수로는 상황에 따라 다를텐데, 예를 들어서 이진 분류를 해야하는 경우라면 시그모이드 함수를 사용할 수 있고 다양한 카테고리 중에서 선택해야하는 문제라면 소프트맥스 함수를 사용하게 될 것이다.
Keras Parameters
- hidden_size = 은닉 상태의 크기를 정의. 메모리 셀이 다음 시점의 메모리 셀과 출력층으로 보내는 값의 크기(output_dim)와도 동일. RNN의 용량(capacity)을 늘린다고 보면 되며, 중소형 모델의 경우 보통 128, 256, 512, 1024 등의 값을 가진다.
- timesteps = 입력 시퀀스의 길이(input_length)라고 표현하기도 함. 시점의 수.
- input_dim = 입력의 크기.

