Passage Retrieval - Dense Embedding
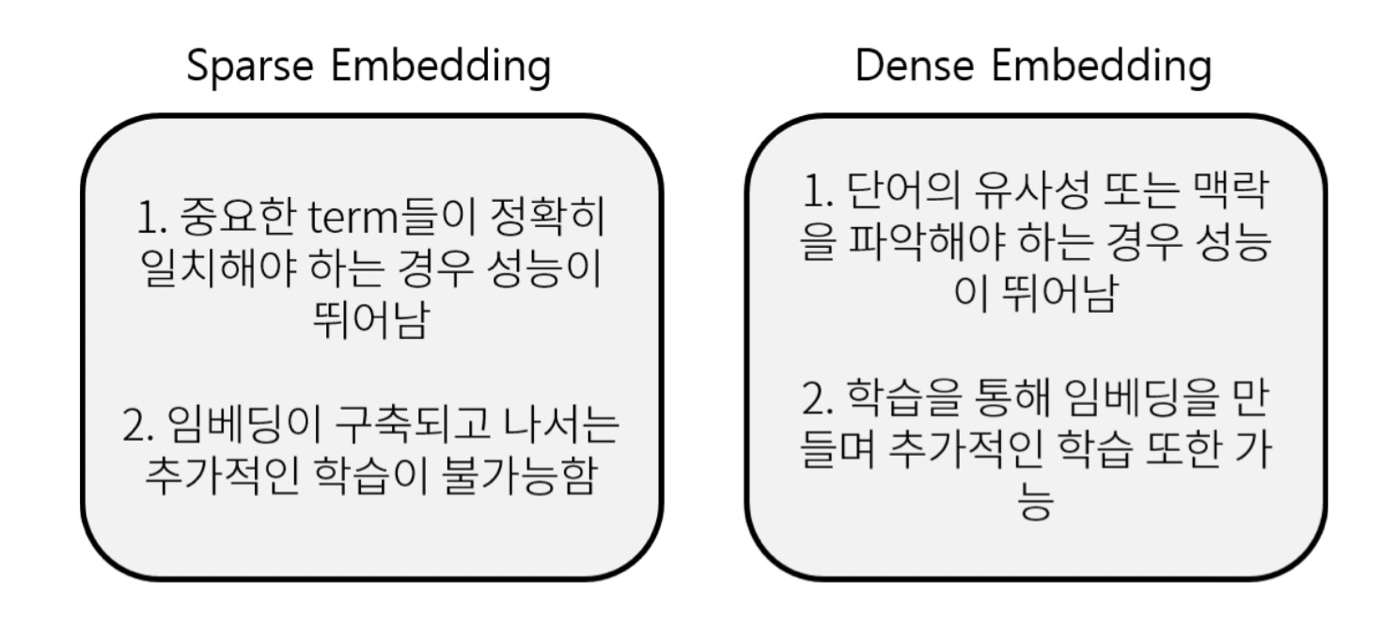
Sparse Embedding
TF-IDF벡터는 Sparse하다. 즉 90%이상의 Matrix 데이터가 0이다.
이렇게 차원의 수가 매우 크고 Sparse한 문제는 compressed format으로 극복이 어느정도 가능하다. 대표적으로 Non-zero인 index를 저장하는 방식 등이 있다. 여기를 참조하자.
그러나 Sparse Embedding방식은 유사성을 고려하지 못한다는 단점이 있다. 즉, 텍스트 자체가 다른 단어들은 완전히 다른 단어로서 판단하게 될 수 있다는 점이다.
Dense Embedding 이란?
Complementary to sparse representations by design
• 더 작은 차원의 고밀도 벡터 (length = 50-1000)
• 각 차원이 특정 term에 대응되지 않음
• 대부분의 요소가 non-zero값
즉, Sparse는 단어 자체의 유무는 잘 판단하나 의미를 생각하지 못하고, dimension이 너무 큰 탓에 한계가 있는 반면 Dense는 의미를 잘 파악할 수 있다는 장점이 있다.
Sparse와 Dense를 동시에 사용하거나, Dense만을 사용하는 추세이다. 최근 사전학습 모델의 등장, 검색 기술의 발전 등으로 인해 Dense Embedding을 활발히 이용한다.
dense embedding에는 두 개의 model를 학습시키며 활용하는데, 두 모델을 같은 걸 사용하기도 하나 보통은 두 개로 따로 나누어서 사용하고, 아키텍쳐는 같은 방식을 사용한다.
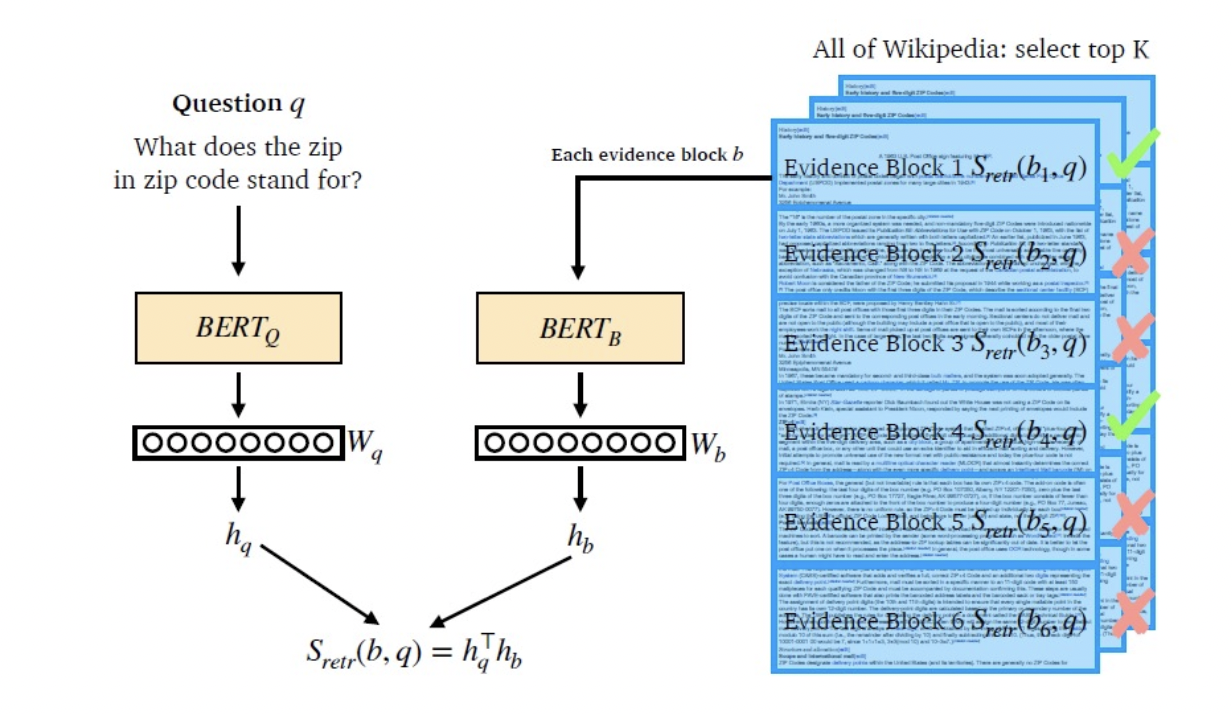
먼저, Dense embedding을 생성한 인코더 훈련을 한 다음 질문과 문서를 비교하여 관련 문서를 추출하는 방식이다.
Training Dense Encoder
BERT와 같은 PLM이 자주 사용된다.
what can be Dense Encoder?
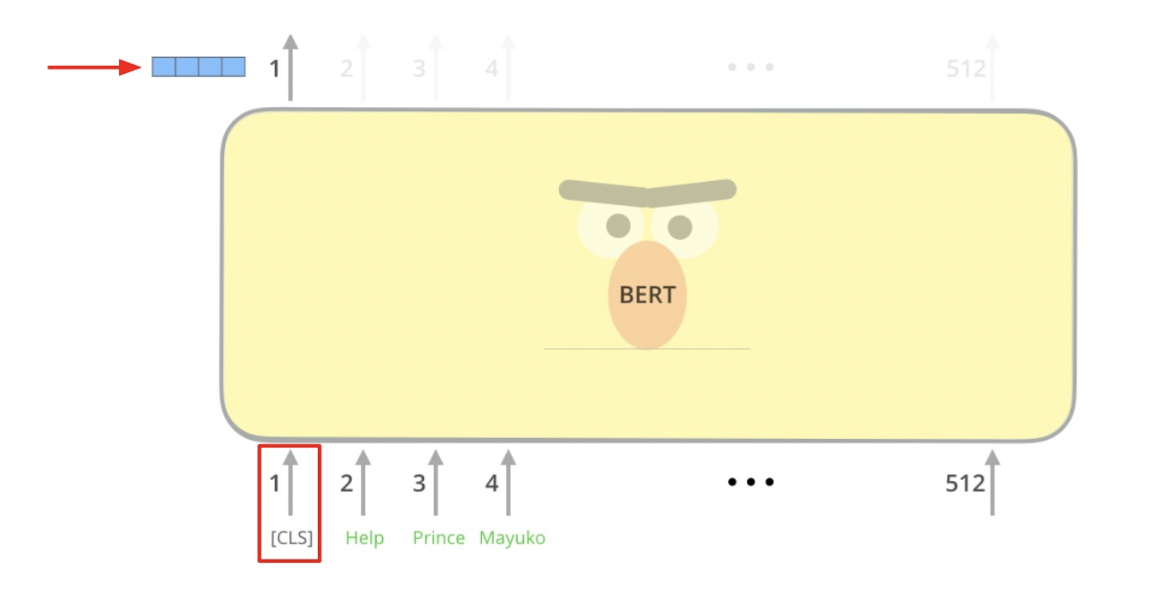
BERT as dense encoder -> [CLS] token 의 output 사용
Passage나 Question의 정보를 대표하는 정보로 CLS 토큰 사용!
연관된 question과 passage dense embedding 간의 거리를 좁히는 것 (또는 inner
product를 높이는 것). 즉 higher similarity.
Challenge: 연관된 question / passage를 어떻게 찾을 것인가?
: 기존 MRC 데이터셋을 활용
학습 with Negative Sampling
Dense Encoder 학습 목표와 학습 데이터 – Negative Sampling
1) 연관된 question과 passage 간의 dense embedding 거리를 좁히는 것 (higher similarity) ⇒
Positive
2) 연관 되지 않은 question과 passage간의 embedding 거리는 멀어야 함 ⇒ Negative
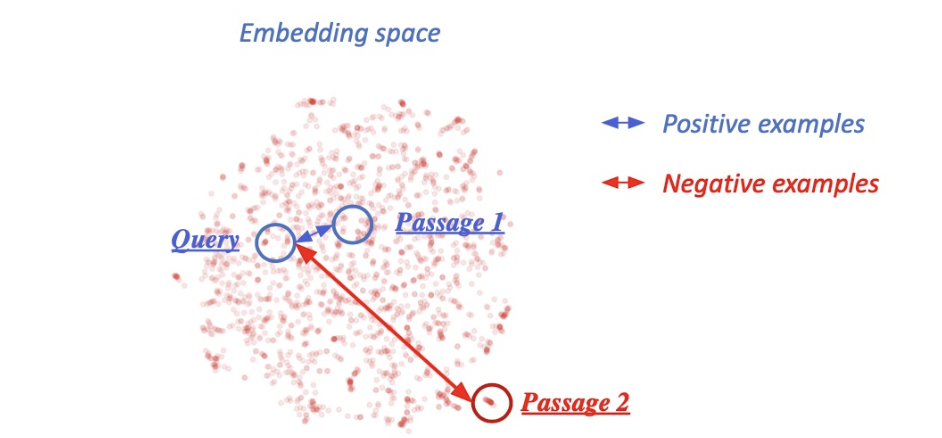
Choosing negative examples:
- Corpus 내에서 랜덤하게 뽑기
- 좀 더 헷갈리는 negative 샘플들 뽑기 (ex. 높은 TF-IDF 스코어를 가지지만 답을 포함하지 않는 샘플)
Objective Function
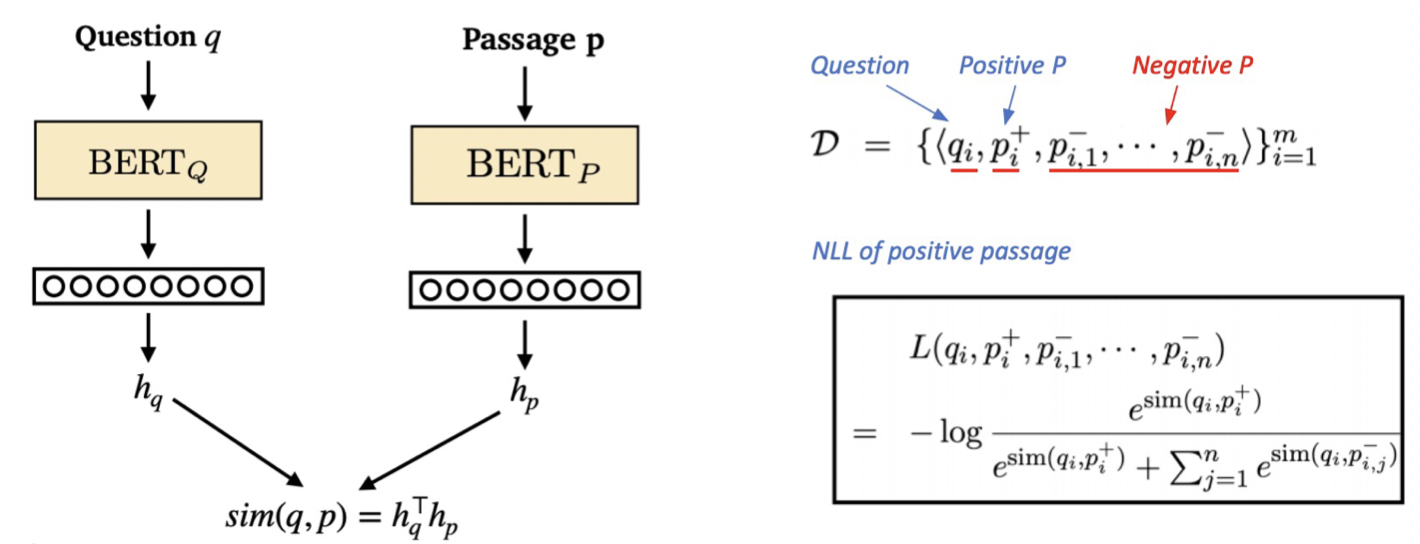
어떠한 Question 에 대해서 Passage 들을 포함하는 Data 가 있을 때, 값의 NLL Loss Function을 사용한다.
- 하나의 positive sample과 n개의 negative sample을 하나의 instance로 학습한다.
Passage Retrieval with Dense Encoder
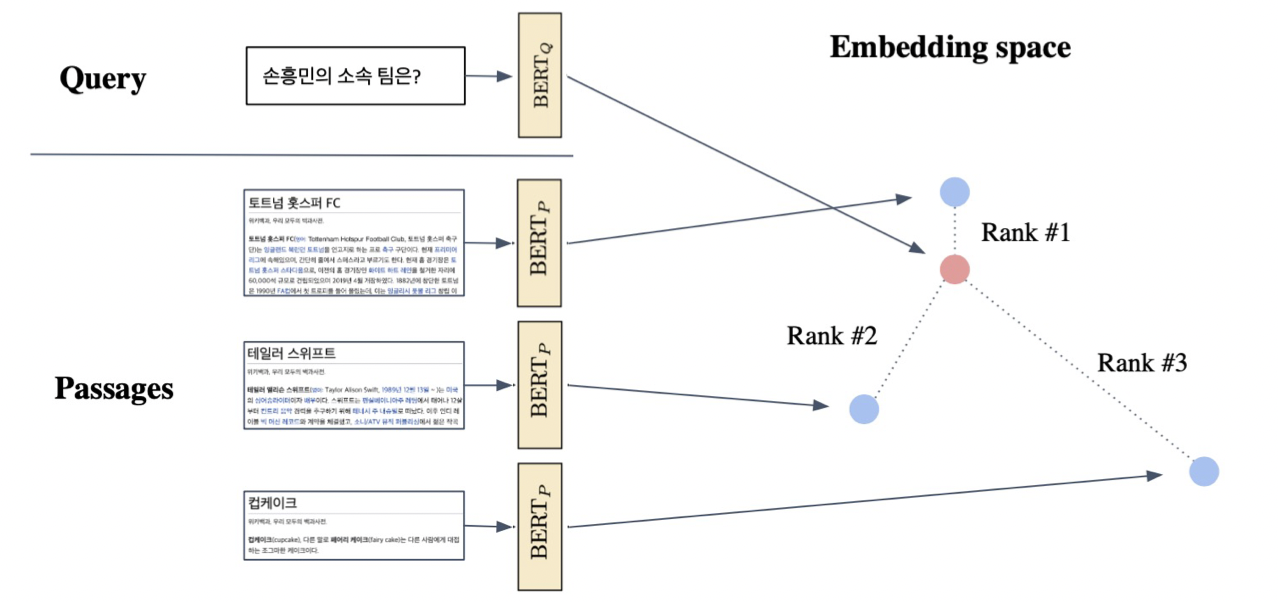
From dense encoding to retrieval
Dense Embedding
Inference: Passage와 query를 각각 embedding한 후(Offline, corpus가 정해지면 미리 하는 것), query로부터 가까운 순서대로 passage의 순위를 매김
How to make better dense encoding
• 학습 방법 개선 (e.g. DPR)
참조 논문
Dense Retriver end2end
• 인코더 모델 개선 (BERT보다 큰, 정확한 Pretrained 모델)
• 데이터 개선 (더 많은 데이터, 전처리, 등)
Code 실습
1. Requirements
2. 데이터셋 로딩
3. 토크나이저 준비 - Huggingface 제공 tokenizer 이용
4. Dense encoder (BERT) 학습 시키기
5. Dense Embedding을 활용하여 passage retrieval 실습해보기
negative sampling code를 살펴보자. corpus는 context 데이터들의 집합(중복이 없는)이라는 것을 염두해두자.
num_neg = 3
corpus = np.array(corpus)
p_with_neg = []
# 주어진 데이터들의 context에 속하는 c에 대해서,
for c in training_dataset['context']:
# 반복한다
while True:
# num_neg만큼 랜덤한 idx들을 선택한 뒤
neg_idxs = np.random.randint(len(corpus), size=num_neg)
# 만약 c가 corpus의 idx에 속하지 않는다면
if not c in corpus[neg_idxs]:
# 해당 context를 p_neg로 새로 선언하고
p_neg = corpus[neg_idxs]
# p_with_neg에 c를 추가한다.
p_with_neg.append(c)
# p_with_neg에 p_neg를 extend한다!
p_with_neg.extend(p_neg)
# 반복 종료
break즉, 위의 코드를 실행하면 모든 corpus의 context들에 대해서 positive passage 하나에 대해서 num_neg로 지정한 개수의 negative passage를 저장하게 된다.
그 다음, Tokenizer를 이용해 위에서 저장한 p_with_neg와 dataset['questions']를 각각 p_seqs,q_seqs로 저장한다.
이 때, 각 tokenized text는 ['input_ids', 'token_type_ids', 'attention_mask']를 key로 가지고 있는 dictionary형태이다.
각 데이터는 (데이터수 X (Negtive num + 1), hidden dim)의 size를 가지고 있기 때문에 이를 각 seq별로 resize를 해주는 작업을 거쳐야한다.
max_len = p_seqs['input_ids'].size(-1)
p_seqs['input_ids'] = p_seqs['input_ids'].view(-1, num_neg+1, max_len)
p_seqs['attention_mask'] = p_seqs['attention_mask'].view(-1, num_neg+1, max_len)
p_seqs['token_type_ids'] = p_seqs['token_type_ids'].view(-1, num_neg+1, max_len)
print(p_seqs['input_ids'].size())
#(num_example, pos + neg, max_len)이제 Dense Retrival을 위해 Bert 모델을 사용한다. 방법은 간단하게 bert모델의 cls토큰, pooled output을 활용한다. 여기서 핵심은, p_seq와 q_seq에 대한 모델을 두 개 선언한다는 점이다.
두 모델에 각각 question과 passsage를 넣고 bmm(batch matrix-matrix product)를 통해 나온 값을 similarity score라고 생각할 수 있으며, 이 값을 Log_Softmax를 취해준다. 이 때 softmax를 취한 값은 각 passage별 확률값을 의미하게 되는 것이다. 이후에 위의 값과 target값의 NLL loss값을 loss function으로 학습하게 된다. 즉, 정답 클래스의 경우 softmax의 결과가 1에 가까워야 하고 1에 가까울수록 -log(a)는 0에 가까워지므로 loss가 줄어들게 된다.
반면 정답이 아닌 클래스의 경우 softmax의 결과가 0에 가까워야 하고 0에 가까울수록 -log(1-a)는 0에 가까워지므로 loss가 줄어들게 된다.
위의 과정을 통해 Dense Embedding작업을 완료했다. 그렇다면 passage retrieval을 하는 방법을 알아보자.
In-batch negative 방법
참조
In batch 방식은 target vector를 [0, 1, 2, 3, ...]의 벡터로해서 Diagonal vector를 Positive embedding으로 확인하는 형태이다. In batch가 아닌 방식은 사전에 Positive embedding을 진행할 때 0번째 index에 positive embedding을 위치시켰기 때문에 target vector가 zero 벡터가 된다. 따라서 nll loss function을 prediction과 target으로 설정해놓으면 positive embedding에 더욱 가까워지도록 학습하게 되는 것이다.
따로 positive, negative 샘플 지정 안 하고 batch 안에서 계산하는 방법, 빠르고 효과적인 training method. Q,P를 각각 임베딩 된 question, passage라고 할 때(batch_size: B, embed_dim: d), 대략적으로 다음과 같이 loss를 계산한다.
Dense Embedding을 활용한 passage retrieval
학습되지 않은 데이터셋인 validation 데이터를 활용해서 random하게 뽑은 데이터의 question에 대하여 ground truth인 context를 저장한다. 그 다음, question을 q_encoder를 통해 임베딩시키고 valid_corpus에 해당하는 passage들에 대해서도 p_encoder를 통해 임베딩시킨다.(인코딩 과정)
위에서 나온 p,q 임베딩 값들을 matrix multiplicate하여 나온 값을 우리는 passage의 score 벡터로 표현할 수 있고, 해당하는 정보를 통해 passage를 선택하게 된다.
