1. 기계독해 & 파이썬 베이직 소개
기계독해란?
기계독해 평가방법
언어처리를 위한 파이썬 베이직
기계독해 데이터셋 들여다 보기
-
추출기반 기계독해
추출기반으로 기계독해 접근하기
Hugging Face와 BERT
BERT를 기계독해에 fine-tune 해보기 -
생성기반 기계독해
생성기반으로 기계독해 접근하기
BART 알아보기
BART를 기계독해에 fine-tune 해보기 -
단어기반 문서 검색
문서 검색이란?
tf-idf와 BM-25에 대해 알아보기
tf-idf 사용해 보기 -
임베딩 기반 문서 검색
단어기반 (Sparse) 문서 검색의 한계점
Dense 임베딩의 장점
Dense 임베딩 문서 검색 시스템 만들어보기 -
Faiss로 스케일업
Dense 임베딩 검색을 빠르게 하는 방법 알아보기
Faiss 사용법 익히기
문서검색시스템을 Faiss로 포팅하기 -
기계독해와 문서검색의 만남
오픈도메인 질의응답 (ODQA)란?
기계독해 시스템과 문서 검색 시스템 연결해 보기 -
연결할 때 문제점 및 해결방법
연결한 ODQA 시스템의 문제 파악하기
Training Bias 문제 해결방법 알아보기
해결방법을 실제 시스템에 적용하기 -
T5를 활용한 Closed-book 질의응답*
Closed-book QA 개념 알아보기
T5와 GPT-3에 대해 알아보기
T5 적용해 보기 (실습은 없으나 강의 중 t5-trivia 활용) -
Phrase retrieval을 이용한 Real-time 질의응답*
문서검색기반 질의응답 시스템의 한계점 알아보기
Phrase Retrieval의 개념 알아보기
관련 최근 논문 들여다 보기
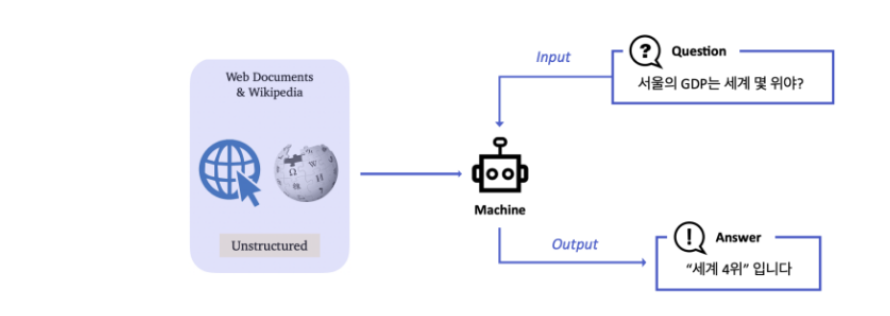
Question Answering(QA)
Question Answering (QA)은 다양한 종류의 질문에 대해 대답하는 인공지능을 만드는 연구 분야이다.
다양한 QA 시스템 중, Open-Domain Question Answering (ODQA) 은 주어지는 지문이 따로 존재하지 않고 사전에 구축되어있는 Knowledge resource 에서 질문에 대답할 수 있는 문서를 찾는 과정이 추가되기 때문에 더 어려운 문제이다.
QA는 질문이 들어오면 위키피디아 등의 거대한 knowledge base에서 문서 몇개를 가져오는 과정(Retrieve) 과 해당 문서들을 읽고 정보를 가져오는 과정(read) 를 거치게 된다.
강의 1-3강은 Read, 4-6강은 Retrieve 과정을 다루고 있으며 7-8강은 두 모델을 합치는 과정을 다룬다.
이번 주의 목표는 1-8강의 강의를 듣고 실습 코드를 따라가며, 베이스라인 코드를 기반으로 학습을 진행하면서 경과를 지켜보면서 시작하려고 한다.
현재 베이스라인 코드에서 눈여겨 볼 점은 아래와 같다.
-
train.py 에서 sparse embedding 을 훈련하고 저장하는 과정은 시간이 오래 걸리지 않아 따로 argument 의 default 가 True로 설정되어 있다. 실행 후
sparse_embedding.bin과tfidfv.bin이 저장이 된다. 만약 sparse retrieval 관련 코드를 수정한다면, 꼭 두 파일을 지우고 다시 실행해야한다. 안그러면 존재하는 파일이 load 되기 때문이다. -
모델의 경우
--overwrite_cache를 추가하지 않으면 같은 디렉토리에 저장되지 않는다. -
./outputs/디렉토리 또한
--overwrite_output_dir을 추가하지 않으면 같은 디렉토리에 저장되지 않는다.
