최종 순위 6등, 우리는 Covit-19
유래없는 바이러스 Covid-19로 전 세계의 사람들이 고통받고 수많은 사업들이 문을 닫거나 생기를 잃게 되었다. 아이러니하게도, 비대면이 활성화되면서 인공지능과 같은 기술 산업의 성장은 더욱 가속화된 것 같다.
2주 간의 짧은 Pstage가 끝이 났다. 제공되는 강의나 실습 코드 분량이 꽤 되었기 때문에 아무래도 강의를 충실히 수행해나가기 부담되는 일정이긴 했다.
약 2주, 정확하게는 12일 간의 프로젝트 진행 과정과 내가 했던 노력들을 정리해보려한다.
대회 개요
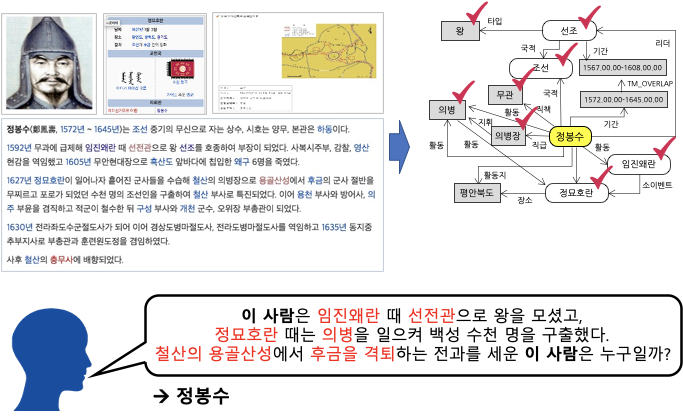
문장 속에서 단어간에 관계성을 파악하는 것은 의미나 의도를 해석함에 있어서 많은 도움을 준다. 그림의 예시와 같이 요약된 정보를 사용해 QA 시스템 구축과 활용이 가능하며, 이외에도 요약된 언어 정보를 바탕으로 효율적인 시스템 및 서비스 구성이 가능하다.
관계 추출(Relation Extraction) 은 문장의 단어(Entity)에 대한 속성과 관계를 예측하는 문제이다. 관계 추출은 지식 그래프 구축을 위한 핵심 구성 요소로, 구조화된 검색, 감정 분석, 질문 답변하기, 요약과 같은 자연어처리 응용 프로그램에서 중요하다. 비구조적인 자연어 문장에서 구조적인 triple을 추출해 정보를 요약하고, 중요한 성분을 핵심적으로 파악할 수 있다.
이번 대회에서는 문장, 단어에 대한 정보를 통해 ,문장 속에서 단어 사이의 관계를 추론하는 모델을 학습시킨다. 이를 통해 우리의 인공지능 모델이 단어들의 속성과 관계를 파악하며 개념을 학습할 수 있다. 우리의 model이 정말 언어를 잘 이해하고 있는 지, 평가해 보자.
협업 툴
1. github
- 기본적으로 깃허브를 통해 main 브랜치를 만들고 각자 브랜치를 하나씩 만들어서 작업하는 형태로 진행했다.
- 팀 전체에 공통적으로 합치고 싶은 코드일 때 main branch에 merge시키는 형식으로 진행했다.
2. notion
팀 회의나 일정 관리, 각자의 실험 결과 기록 등 다양한 정보를 공유하는 공유 워크스페이스로 활용했다.
3. slack
또 다른 공유 워크스페이스로, 멘토 분과의 질의응답이나 좀더 정보 제공의 목적으로 팀원들과 의사소통의 장으로 사용할 수 있었다.
4. wandb
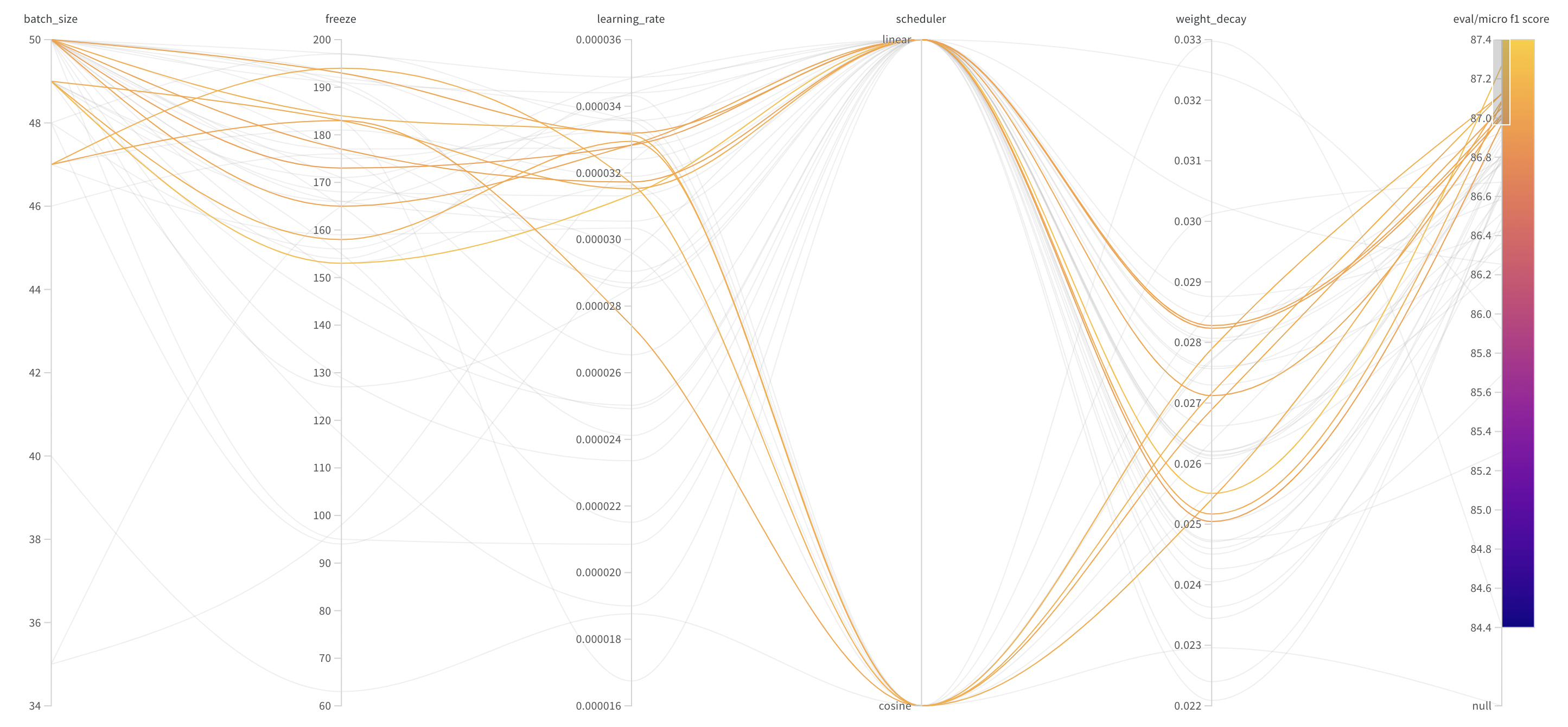
정확하게 실험 결과를 Logging하기 위해 Wandb와 WandbSweep을 이용한 하이퍼파라미터 자동화를 진행했다.
- Wandb Logging
- Wandb Sweep Hyperparameter 변경
Model Selection
일반적으로 RE(Relation Extraction) Task에서 BERT 계열은 웬만하면 좋은 성능을 보인다. BERT는 Transformer의 Encoder를 차용하여 MLM, NSP task를 통해 사전학습하게 되는데, 이 과정에서 문장의 문맥 정보를 이해하고 [SEP]토큰으로 구분되는 Entity간의 관계를 파악하도록 학습 되었다고 생각할 수 있다.
1. Klue/bert-base
- 기본 베이스라인으로 제공되었던 모델이며 아래와 같은 데이터들로 학습시킨 버트 모델이다.
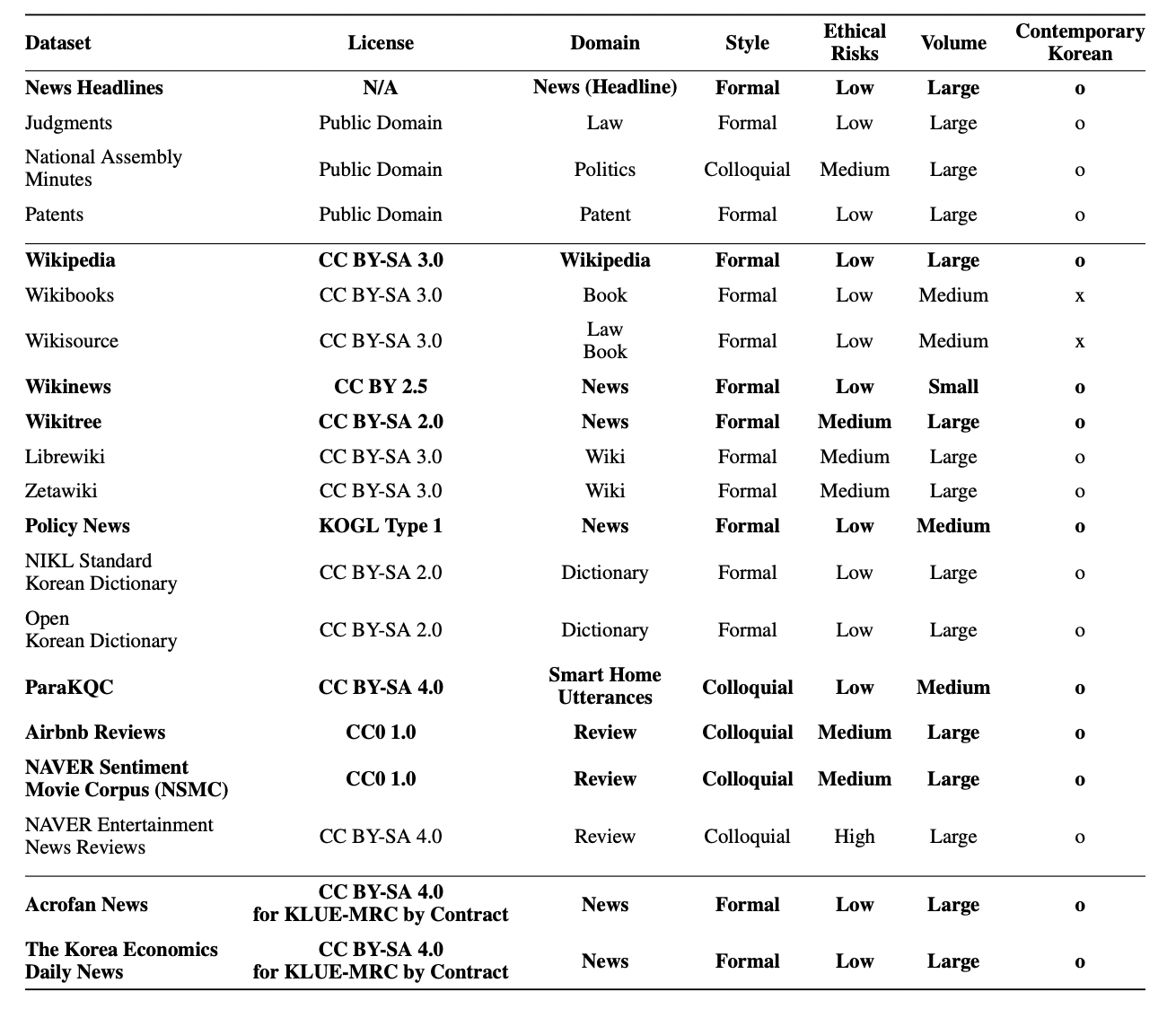
제공된 베이스라인 코드에서 바로 실행이 가능했으며, 성능 역시 준수했다.
2. Koelectra
- BERT계열의 새로운 child로 등장한 것이 ELECTRA인데, BERT 모델보다 훨씬 더 가벼우며 계산적으로도 효율적인데다가 성능 역시 뒤지지 않는 모델이다.
- 일반적인 BERT 모델의 MLM을 통해 새로 Masked 단어를 대체하는 단어를 생성하고 Discriminator가 이를 단어별로 replaced 인지 아닌지를 예측하면서 학습되는 모델이다.
- Klue에서 제공되는 모델은 아니었지만, 박장원 님의 블로그와 깃허브, 허깅페이스 허브에 올려놓은 사전 학습 Electra모델을 활용했다.
- 성능은 bert-base에 비해 조금 떨어지거나 비슷한 정도였다.
- 나중에 Roberta large model과 ensemble을 진행했을 때 꽤 준수한 성능을 냈다.
3. klue/roberta-large
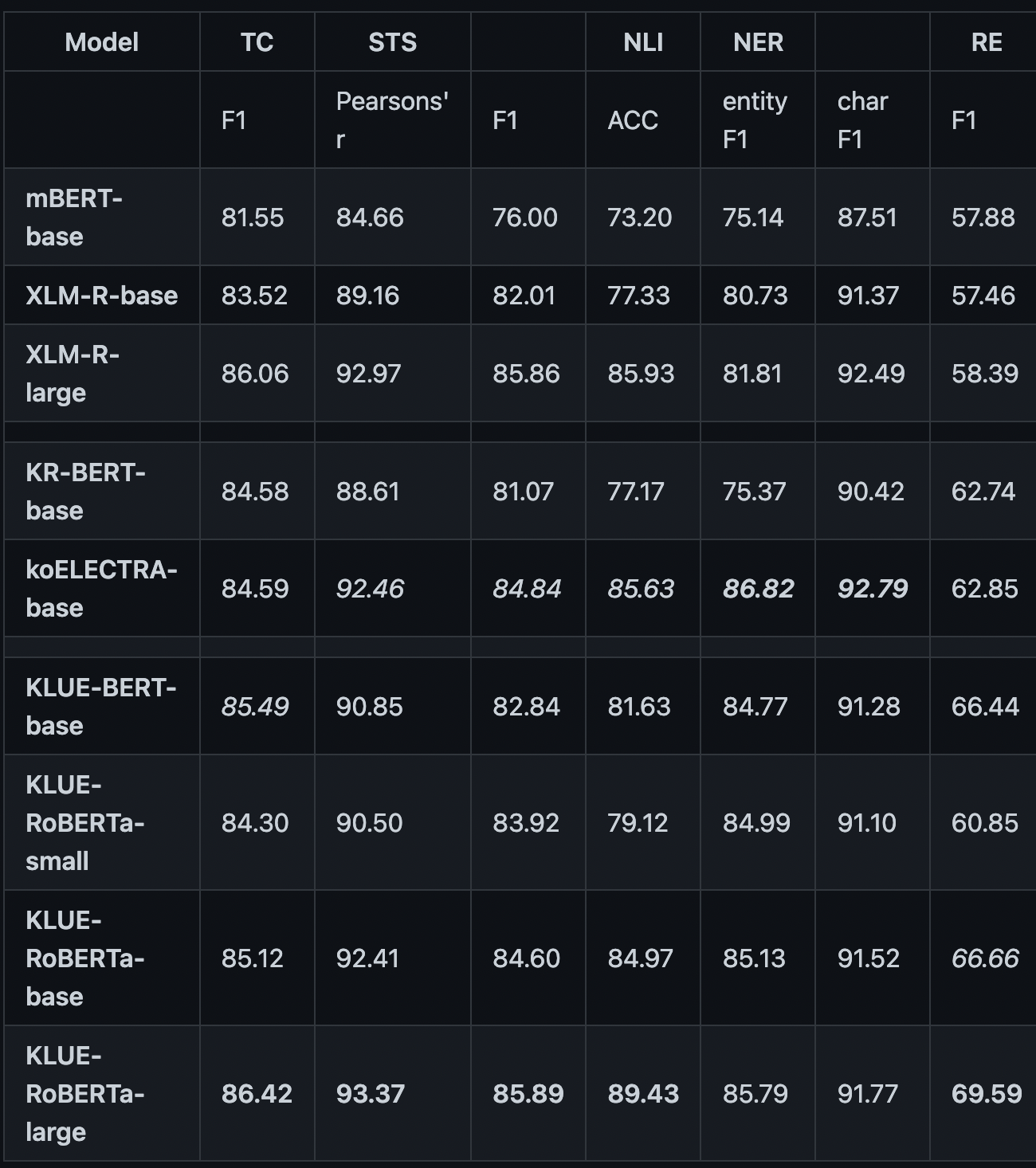
- 위의 표와 같이, Roberta-large 모델이 RE Task에서 가장 높은 Score를 보여주고 있었다. 실제로 Huggingface에서 사용한 Klue/roberta-large모델을 사용하자마자 f1-score 70점대를 달성할 수 있었다.
- 따라서 메인 학습 모델로 RoBERTa Large모델을 사용하도록 결정했다.
EDA / Data Augmentation
EDA
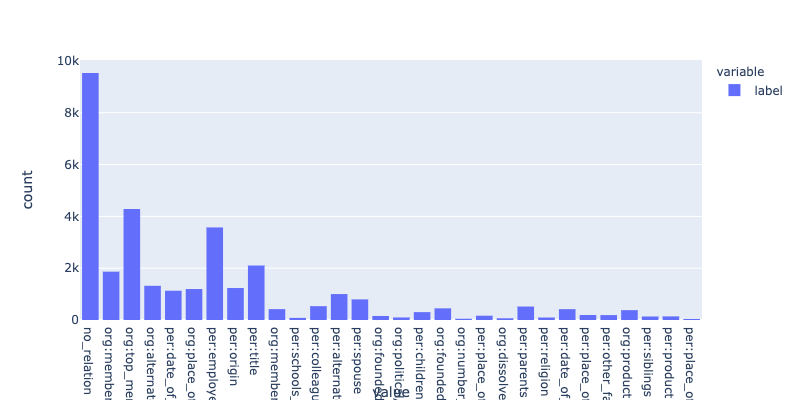
클래스별 분포
문장별 토큰 수
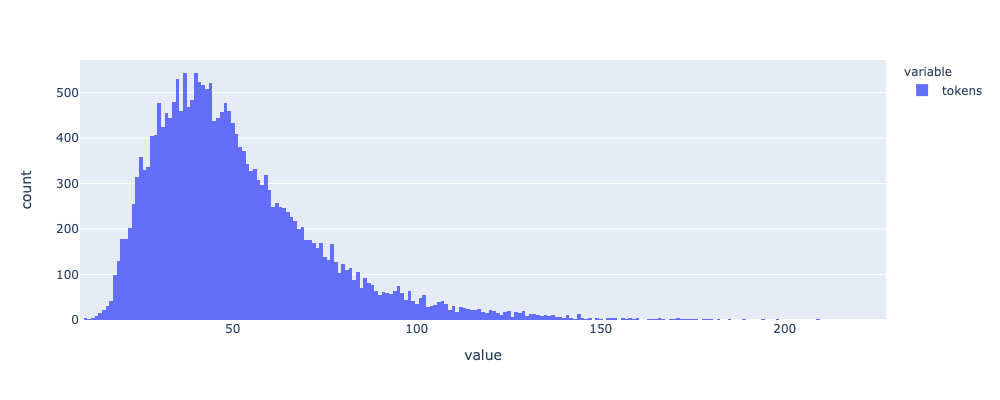
위와 같이, 클래스가 매우 불균형한 형태를 나타내고 있었으며 문장의 길이는 약 50개를 기준으로 약간 치우친 정규분포의 형태를 나타내고 있었다.
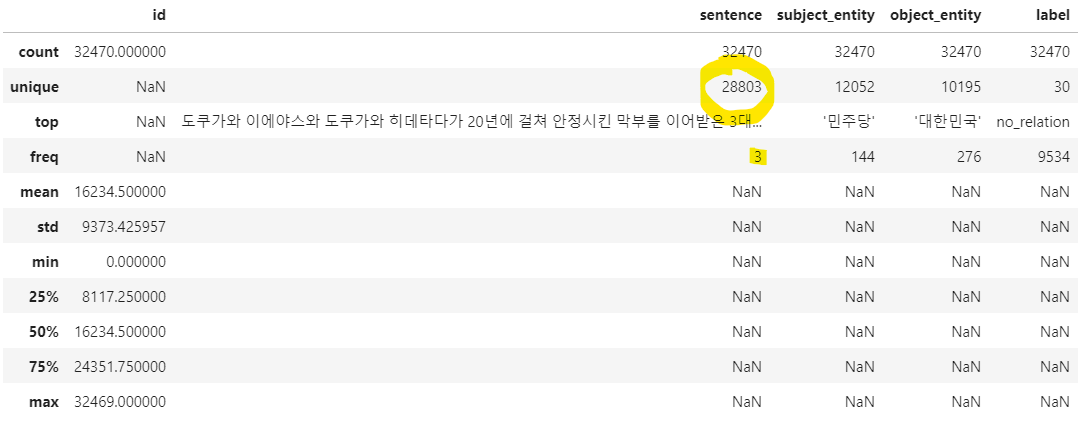
위 사진은 김채은 캠퍼님의 토론 게시판(Competition 참가자만 볼 수 있다.) 사진을 첨부한 것으로, 문장들은 약 3~4000개의 중복 문제가 있었고, 문장과 entity, relation모두 중복인 것은 약 50개 정도가 있었다. 모든 정보가 중복된 데이터의 경우 삭제하여 데이터의 품질을 높였고, 문장이 중복되는 것으로 보아 data augmentation의 방법을 유추할 수 있는 기회가 되었다.
Data Augmentation
sbj-obj substitution
위에서 살펴본 것과 같이, data가 불균형하고 그 수가 적은 데이터이기 때문에 data 증강이 필요하다고 판단되었다. 그 방법으로 Subject_entity와 Object_entity를 서로 바꾸는 방식을 택했다. 자리를 바꿔도 relation이 그대로일 수도 있고, 새로운 relation으로 바뀌는 경우가 있었기 때문에 두 가지 경우를 생각해주었다. 그리고 해당 방법을 통해 유의미한 데이터 증강을 이뤄낼 수 있었다.
KoBART / KoGPT2
Data Augmentation Using Pre-trained Transformer Models에서 pretrained 된 모델을 사용한 데이터 증강을 연구했는데, 결론적으로 GPT계열의 경우 label이나 Entity정보를 유지하지 못하기 때문에 사용되기 어렵다고 한다. 반면 BART와 같은 Seq2Seq계열의 경우 정보를 충분히 유지하면서 문장 생성도 다양한 방식으로 해냈기 때문에 데이터 증강 방식으로 적절하다는 것이다.
한편 위의 논문보다 1년정도 앞서 DARE: Data Augmented Relation Extraction with GPT-2논문에서는 GPT2를 사용한 데이터 증강을 연구했는데, 시간이 된다면 두 논문을 함께 읽어보면 좋을 것이다.
위 논문의 내용을 바탕으로 KoBART를 이용해 데이터 증강을 시도했으나 결과는 그렇게 만족스럽지 못했다. Entity를 유지하지 못하는 경우도 있었고 relation도 유지하지 못하는 경우도 있었다. 물론 Entity와 relation을 모두 유지하면서 서로 다른 새로운 문장을 생성하는 경우도 있었지만 데이터로 추가하기에는 정확하지 않은 데이터라고 판단되어 데이터로 추가하지는 않았다.
생성 모델의 경우 정확한 지표가 없고 사람이 직접 눈으로 확인해야하는 부분이 있다. 요약이나 번역 등에서 활용되는 BLEU스코어나 ROUGE스코어 등이 대체제로서 활용되기는 하지만 한계가 있는 것이 사실이다. 아무래도 KoBART를 활용한 데이터 증강과 관련해서는 더욱 연구가 필요하다고 생각한다.
Entity Marker
An Improved Baseline for Sentence-level Relation Extraction 에서는 Relation Extraction Task에서 Entity를 특정한 토큰이나 문자로 Marking하는 방법의 효과를 설명했다. 이번 프로젝트에서는 Entity를 모델이 명확하게 인식하도록 아래의 그림과 같이, RoBERTa에서 성능이 좋은 Typed Entity Marker with punctuation mark를 사용했다.

Project processes
내가 집중적으로 담당했던 부분은 아래와 같다.
Scheduler test
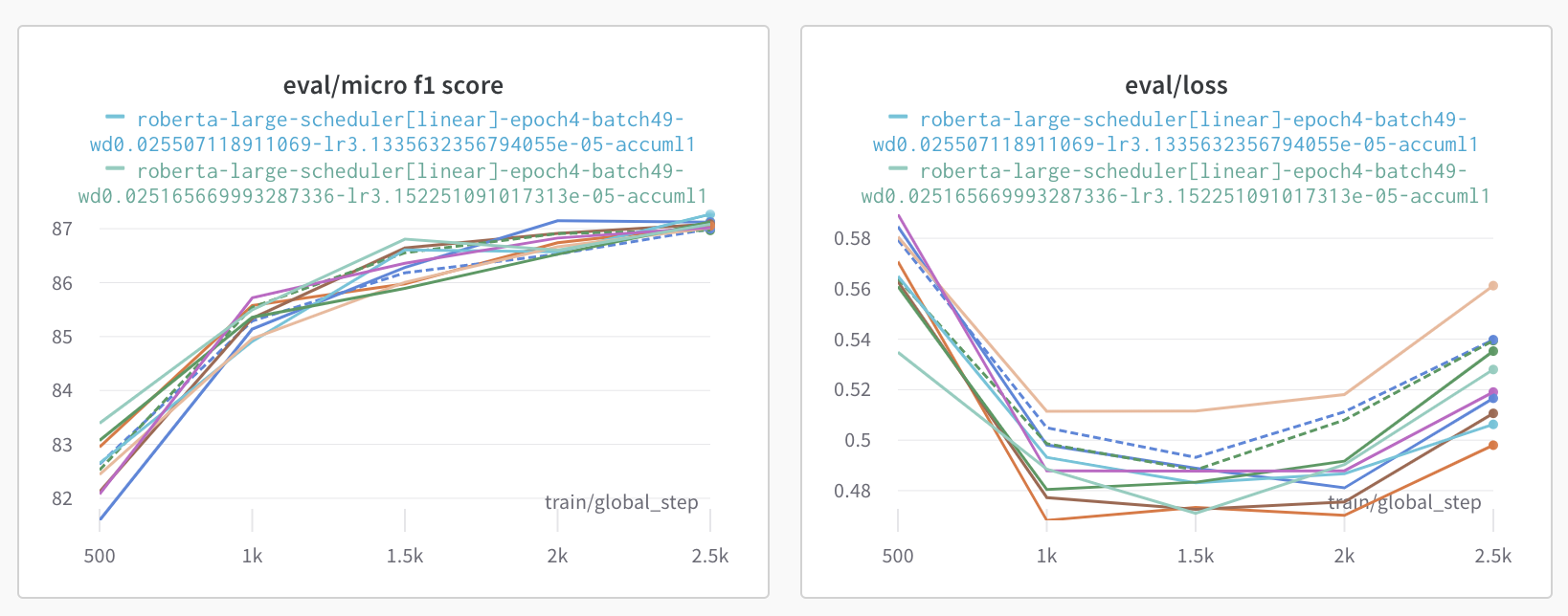
Hugging Face에서 지원하는 Linear, Constant, Cosine, Cosine_with_restart 가운데 최적의 Scheduler를 찾기 위해 Wandb Sweeps를 활용했다.
Constant와 Cosine_with_restart는 좋지 않은 성능을 보이는 것을 확인했고, Linear와 Cosine이 비슷한 성능을 보였다.
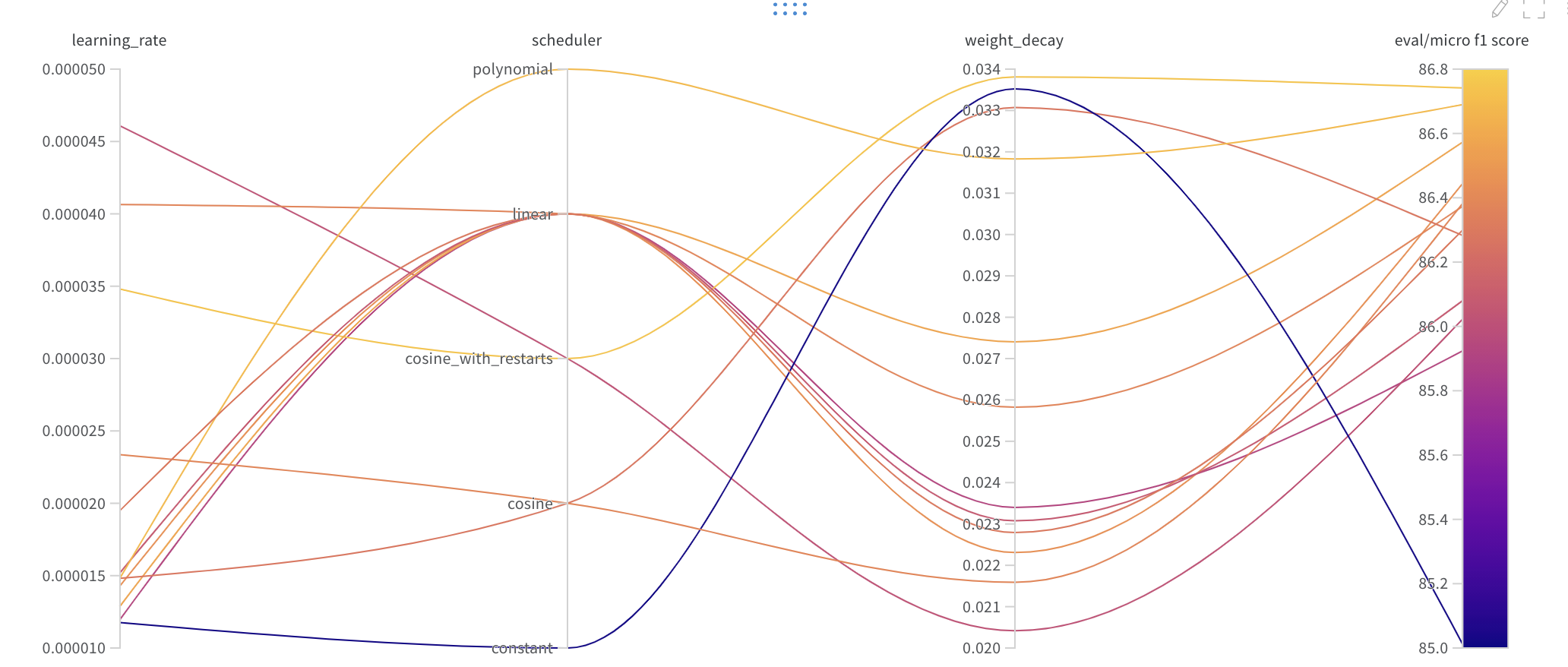
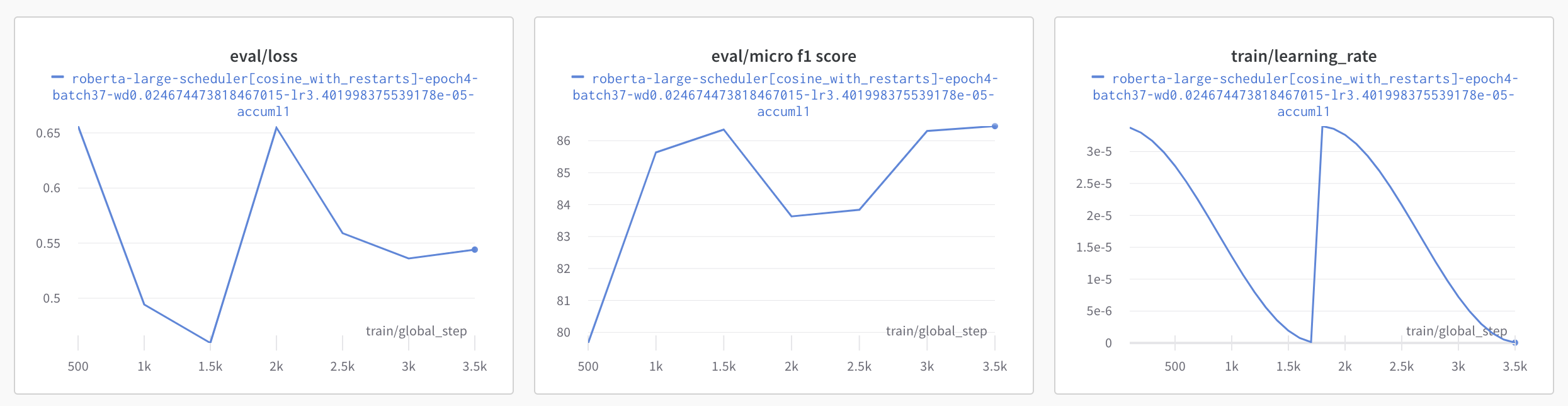
두 번째 그림은 Cosine Annealing방식(Cycle 2)으로, Learning rate이 급격하게 뛰는 부분에서 Micro f1과 Loss값이 급격하게 나쁜 성능을 보였다. 학습을 모두 마쳤을 때에는 비슷한 f1 score가 나왔지만, Submission 결과 Public 상에서 매우 나쁜 성적을 보였기 때문에 제대로 학습되는 것이 아니라고 판단, Scheduler로는 Linear 또는 Cosine을 사용하는 것으로 확정되었다.
fp16
Roberta-large 모델이 Batch size가 37일 때 최대 GPU Memory(95% 이상)를 점유하기 때문에 batch size를 높일 수 있는 trainingargument 의 fp16 값을 True로 주었다. Floating Point를 16bit로 계산한다는 의미이며, GPU Memory 소요량을 동일 배치 사이즈 기준 약 95%에서 30%대로 떨어졌다. 따라서 배치 사이즈를 좀 더 높일 수 있었고 성능을 유지함과 동시에 소요 시간을 단축할 수 있었다.
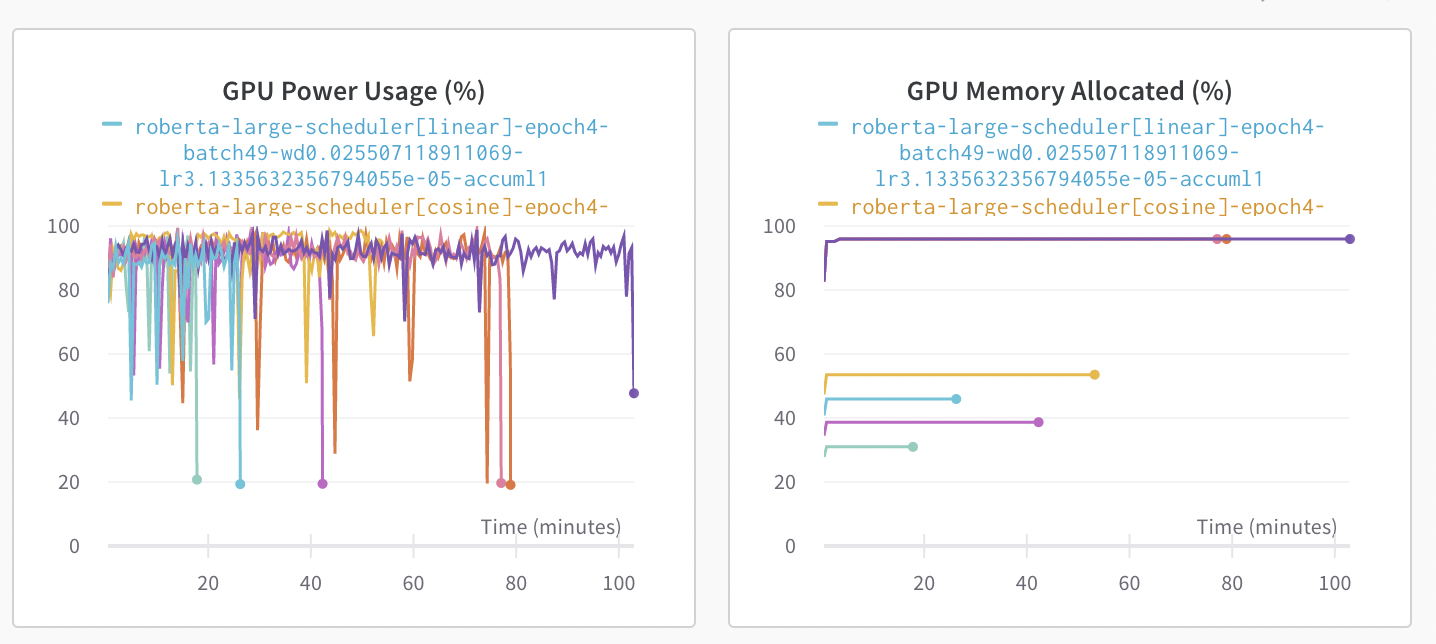
위 사진 오른쪽 그림과 같이 GPU Memory를 기존에 95%가량 점유하던 것이 fp16값을 줬을 때 아래 4개의 결과처럼 감소하는 모습을 보였다.
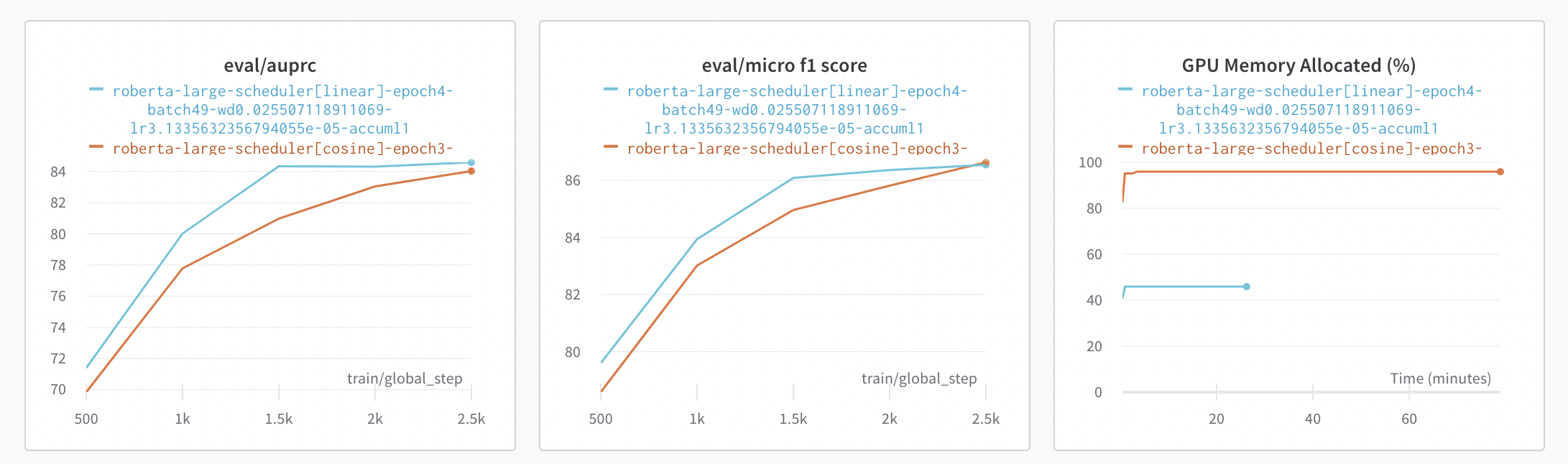
하지만 성능적으로는 위와 같이 큰 차이를 보이지 않았기 때문에 추후 이 점을 활용해서 학습을 진행하는 것이 좋아보인다.
Ensemble
KoElectra Model, Roberta-large Model, Roberta-base Model 3가지의 모델의 결과와 리더보드에서 성능이 좋았던 모델들을 Soft Voting을 사용하여 Ensemble을 시도하였으며, 대부분의 경우 단일 모델로 제출했던 모델들보다 더 성능이 높게 나왔다. 아래의 표는 Public 성적을 기준으로 조합하여 나온 Private 결과이다.
| 최종 순위 | 조합 | micro f1 | auprc |
|---|---|---|---|
| 1 | 가장 성능이 좋았던 단일 모델 5개 | 74.454 | 82.293 |
| 2 | 성능이 좋았던 단일 모델 3개 | 74.193 | 81.323 |
| 3 | 가장 성능이 좋았던 단일 모델 1개 | 73.651 | 78.979 |
| 4 | 가장 성능이 좋았던 단일 모델 2개 + 구조가 다른 모델 1개 | 73.308 | 79.225 |
| 5 | 4명이 각각 학습시킨 모델 1개씩 | 73.226 | 81.196 |
| 6 | 4명이 각각 학습시킨 모델 1개씩 + 구조가 다른 모델 1개 | 73.156 | 80.276 |
결과적으로 소프트 보팅으로 앙상블한 결과를 7개 제출했을 때 상위 8개 모델 중 7개가 소프트 보팅 앙상블 결과였다. 더욱 자세하게 말하자면, 앙상블한 결과는 Public 리더보드에서 단일 모델보다 모두 성능이 우수했다. 그러나 위 표에서 3번째에 해당하는 단일 모델만이 유독 성능이 Private에서 좋은 모습이었다. public에서 micro f1 score가 73점대였던 단일 모델들은 Private에서 71점대로 내려가기도 했고, 70점대였던 모델이 71점 후반의 성적을 보여주기도 했다.
| Metric --- | micro f1 | auprc |
|---|---|---|
| 단일 모델 |  |  |
즉, 위의 결과로 미루어보아 최종 제출에서 앙상블 결과가 웬만해선 안정적인 성적을 내고, 단일 모델의 경우 성적이 이리저리 뛸 수 있다는 사실을 알 수 있다. 또한 Private 성능이 가장 좋은 단일 모델을 사용할 경우 앙상블한 Private 성능역시 좋은 점수를 보장받을 수 있었다. 그러나 Private 점수가 가장 높은 단일 모델을 우리는 알 수 없기 때문에, 최대한 많은 실험을 통해서 Public 스코어가 높은 모델을 기준으로 다양한 앙상블 조합을 시도하는 것이 바람직해 보인다.
