
 진짜 짜증... 누가 이거 브론즈1이라고 했냐? 솔직히 이 정도는 내 자존감을 위해서 실버 주자...
진짜 짜증... 누가 이거 브론즈1이라고 했냐? 솔직히 이 정도는 내 자존감을 위해서 실버 주자...
문제
문제 링크
N개의 수가 주어졌을 때, 이를 오름차순으로 정렬하는 프로그램을 작성하시오.
입력
첫째 줄에 수의 개수 N(1 ≤ N ≤ 10,000,000)이 주어진다. 둘째 줄부터 N개의 줄에는 수가 주어진다. 이 수는 10,000보다 작거나 같은 자연수이다.
출력
첫째 줄부터 N개의 줄에 오름차순으로 정렬한 결과를 한 줄에 하나씩 출력한다.
Code
import sys
input = sys.stdin.readline
test_case = int(input().rstrip())
list_ = [0] * 10001
for _ in range(test_case) :
list_[int(input())] += 1
for i in range(10001) :
if list_[i] != 0 :
for j in range(list_[i]) :
print(i)
계수 정렬(Counting Sort)
이 문제는 코드를 설명하기 전에 계수 정렬에 대한 이해가 필요하다.
계수 정렬이란 말 그대로 숫자를 정렬할 때, 그 숫자가 등장하는 횟수를 이용하는 정렬방법이다.
계수 정렬 쉽게 보기!
계수 정렬 순서
- 가장 작은 데이터와 가장 큰 데이터가 담길 수 있는 배열을 초기화한다. (이 문제에서는 10000)
- 등장 횟수를 기록할 배열에 정렬되지 않은 배열의 수들의 등장 횟수를 기록한다. (아래 코드에서는 list_가 등장 횟수를 기록할 배열)
- 등장 횟수를 기록한 배열에 저장된 등장 횟수를 누적합으로 변환한다.
- 위에서 사용한 누적합을 이용하여 순서대로 숫자 출력
이때, 계수 정렬을 위해서는 두 가지 조건이 필요하다.
- 등장 횟수는 양수여야 한다.
- 데이터의 범위가 너무 크지 않아야 한다. (메모리 사이즈를 넘어서는 안 되기 때문)
위와 같은 조건을 위해 이 문제에서는 '이 수는 10,000보다 작거나 같은 자연수이다.'라는 조건을 명시했다.
코드 설명
import sys
input = sys.stdin.readline
test_case = int(input().rstrip())
list_ = [0] * 10001위 문제에서 가장 중요한 문구는 이 수는 10,000보다 작거나 같은 자연수이다.라는 문구이다. 문제에서 주어진 데이터의 범위가 10,000이기 때문에 리스트의 인덱스가 0에서 시작하는 것을 감안하여 10001개의 배열을 만든다. 메모리 제한 때문에 그냥 list_ = []을 할 정도의 메모리 여유가 없다.
만약 list_ = []을 사용하게 된다면 문제에 나온 것처럼 수의 개수가 천만개가 나올 경우 메모리 초과가 이루어지게 된다. 때문에 자연수의 개수는 10,000 이하이고 수의 개수는 10,000,000임을 감안하여 중복된 수는 같은 배열에 저장할 수 있도록 한다.
for _ in range(test_case) :
list_[int(input())] += 1
for i in range(10001) :
if list_[i] != 0 :
for j in range(list_[i]) :
print(i)첫 번째 for문이 위에서 설명한 것처럼 천만개의 수가 들어오는 경우를 위해 중복된 수의 경우 같은 인덱스에 저장하는 과정이다. 만약 4가 다섯 번 들어오는 경우, 4번 인덱스의 값은 5가 될 것이다. 이 과정이 누적합을 구하는 과정이다.
두 번째 이중 for문은 배열을 처음부터 끝까지 돌면서 배열에 어떤 수가 몇 번 들어가 있는지 확인 후 출력하는 과정이다. 만약 인덱스 내에 들어있는 수가 1이 아니라면, 들어있는 수만큼 for문을 한 번 더 돌면서 인덱스를 출력하는 것이다. 위의 예시와 같게 설명하자면, 4번 인덱스의 값이 5인 경우에 두 번째 for문이 5번 실행되면서 인덱스 번호인 4를 5번 출력할 것이다.
문제를 풀면서 시간초과를 걱정하기도 했는데, 시간 제한이 5초이기도 했고 애초에 계수 정렬이 시간복잡도가 좋은 정렬은 아니라 시간을 넉넉하게 준 것 같기도 하다. 문제의 채점 및 기타 정보에 이 문제의 채점 우선 순위는 2이다.라는 문구를 통해 시간보다 메모리가 우선이라고 명시했다.
리뷰
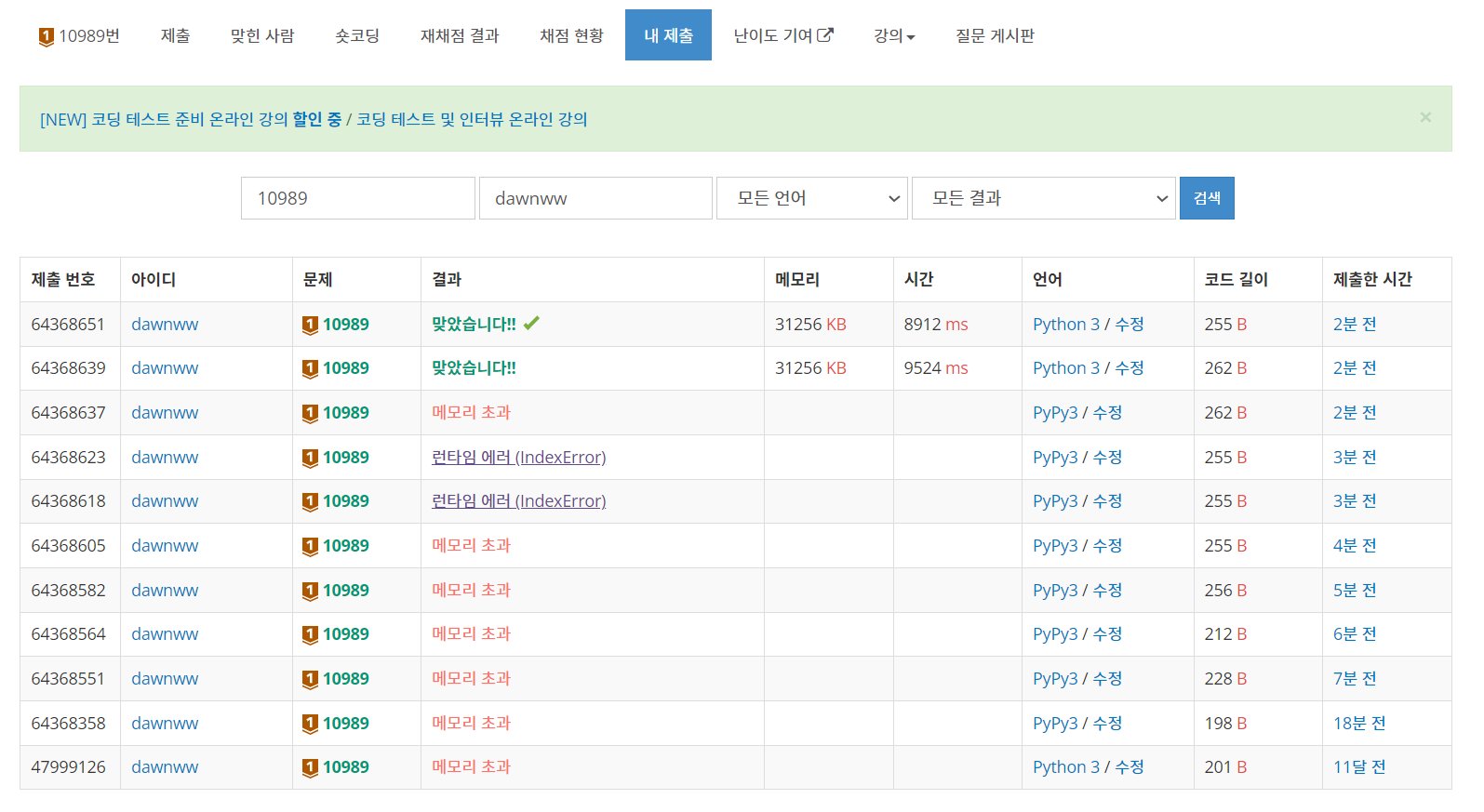
홍균 오빠랑 확인하다가 브론즈 1 문제 틀린 거 보고 그냥 잘못 풀었나보다... 했는데 집에 와서도 틀려서 진짜 황당했다. 알고 보니까 sort로는 메모리초과가 뜨고 계수 정렬을 무조건 사용해야만 메모리 초과를 피할 수 있었다. 누가 이거 브론즈 1이라고 했어... 장난? 세상에 메모리 초과 피하려고 계수 정렬 사용하는 브론즈가 어딨어......... 그리고 같은 코드여도 Pypy로는 메모리 초과가 뜨고 Python으로는 메모리 초과가 안 뜨는 것도 확인할 수 있었다. 이건 나중에 이유 찾아봐야겠다.
사실 코드 자체가 길고 어려운 건 아닌데, 자연수의 범위는 만 개이지만 수의 개수가 천만 개까지 들어올 수 있다는 사실을 깨닫고 중복을 방지하는 과정을 생각하기 어려운 것 같다. 중복된 수를 같은 인덱스에 저장해야 한다는 아이디어만 떠올리면 구현은 어렵지 않은 문제라고 생각한다. 그래두짜증나진짜이게먼데
