Abstract
- news 데이터는 named entity와 흔히 사용하지 않는 단어를 포함하기 때문에 caption을 예측하기 힘들다.
- 본 논문에서는 멀티 모달 멀티헤드 어텐션을 이용해 뉴스 이미지에 등장하는 object와 얼굴을 caption과 연관시켜named entity가 포함된 caption을 생성하도록 돕는다.
- 또한 흔히 사용되지 않는 단어 문제를 해결하기 위해 BPE(byte-pair-encoding)을 사용한다.
1. Introduction
기존 captioning system의 문제
- 대부분의 captioning system은 일반적은 객체 분류를 인식할 뿐 구체적인 이름과 장소에 대해서는 인식하지 못하고, 상식과 일치하지 않는 경우가 많다.
- captioning system은 고정된 vocab에 의존하기 때문에 사람이 직접 작성한 caption 보다 짧고 다양하지 못한 caption을 생성하는 경향이 있다.
News caption
- news caption은 특정한 인물, 단체, 장소를 설명할 뿐만 아니라 기사의 맥락적인 정보를 제공한다.
- news에 사용되는 언어는 시간이 지남에 따라 어휘와 단어가 바뀐다.(e.g. walkman -> mp3)
- 기존 접근 법은 template을 이용해 caption을 예측하고 template의 빈곳을 많이 등장하는 entity순으로 채우기 때문에 오류가 발생할 확률이 높다.
논문에서 제안한 방식
- image captioning을 위한 end-to-end방식의 모델인 transform and tell model을 제안
- 이미지에서 추출한 얼굴과 객체와 기사에 있는 단어에 대한 multi-head attention을 계산해 이미지와 텍스트의 정보를 포함하는 representation을 만듦
- vocab에 존재하지 않는 단어(OOV)를 해결하기 위해 BPE인코딩을 이용한다.
3. The Transform and Tell Model
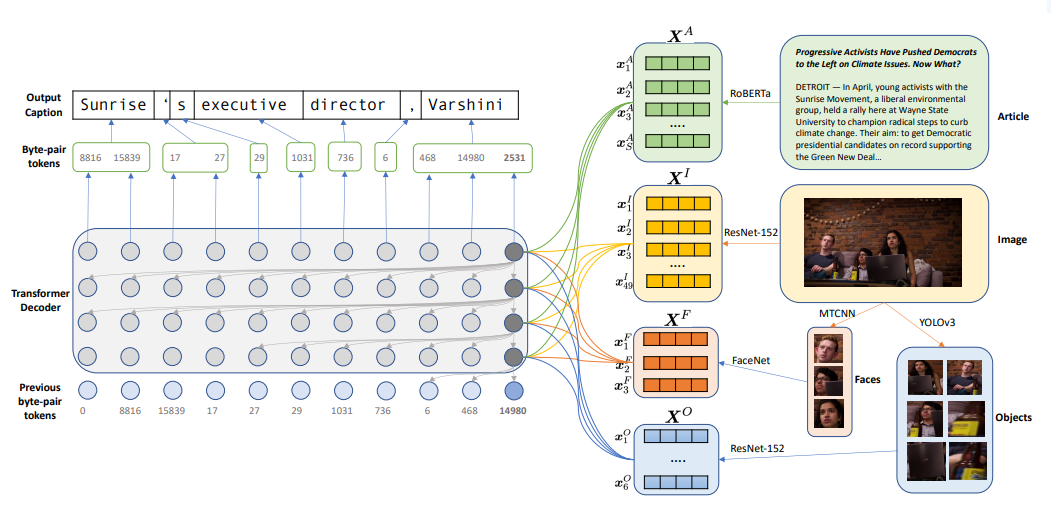
논문에서 사용한 모델은 그림과 같이 pretrained된 encoder와 decoder로 구성 되어있으며, 간략한 역할은 아래와 같다.
encoder
- 이미지, 얼굴, 객체, 뉴스기사에서 high-level representation 추출
decoder
- encoder에서 추출한 representation들을 이용해 caption을 생성
3.1 Encoder
Image Encoder:
pretrain된 resnet152 모델을 사용, linear layer를 거치기 전 (batch_size, 7, 7, 2048) 크기의 vector를 (batch_size, 49, 2048) 차원으로 변환한 뒤 representation으로 사용한다.
- 이러한 representation을 사용하면 decoder가 이미지의 서로 다른 영역을 attend 할수 있기때문에 caption 생성에서 널리 채택된다.
Face Encoder:
이미지에서 얼굴 영역의 bounding box를 detect하기 위해 MTCNN 모델을 사용.
대부분의 caption은 최대 4명 까지 등장하므로 이미지에서 4 명의 사람 얼굴만 detect한다. 이후 detection 된 bounding box 영역들을 FaceNet을 이용해 512 크기의representation을 추출한다.
- 이러한 face representation은 decoder가 더 정확한 named entity들을 생성하도록 돕는다.
※ 이미지에 사람 얼굴이 없는 경우 representation은 존재하지 않는다.
Object Encoder:
YOLO-v3 모델을 이용해 confidence 0.3 이하인 영역들을 제거하고 최대 64개의 object를 추출.
이후 resnet-152를 사용해 특징을 추출한다.
Article Encoder:
RoBERTa 모델 사용, byte 단위의 tokenizer인 BPE를 사용하기 때문에 entity가 unknown token으로 매핑되지 않는다.
3.2 Decoder

잘하자