Taxonomy
Text Detection모델의 경우 regression과 segmentation 기반의 관점으로 볼 수 있다.
Regression-Based
regression-base Text Detection 모델 예시:
- TextBoxes'18
ssd를 글자 영역 탐지에 맞게 수정한 모델이다. text object의 특성에 맞게 anchor box를 가로를 늘린 것을 볼 수 있다. anchor박스와 GT의 좌표 차이가 최소가 되는 방향으로 학습한다.

이러한 regression-base 모델은 사각형의 bbox만 적용이 가능하다. 따라서 휘어진 글자나 구겨진 글자를 사각형의 bbox로 표현하다보니 불필요한 영역을 포함하게 된다. 또한 anchor box보다 휠씬 큰 종횡비를 갖는 객체에 인식률이 떨어지게 된다.

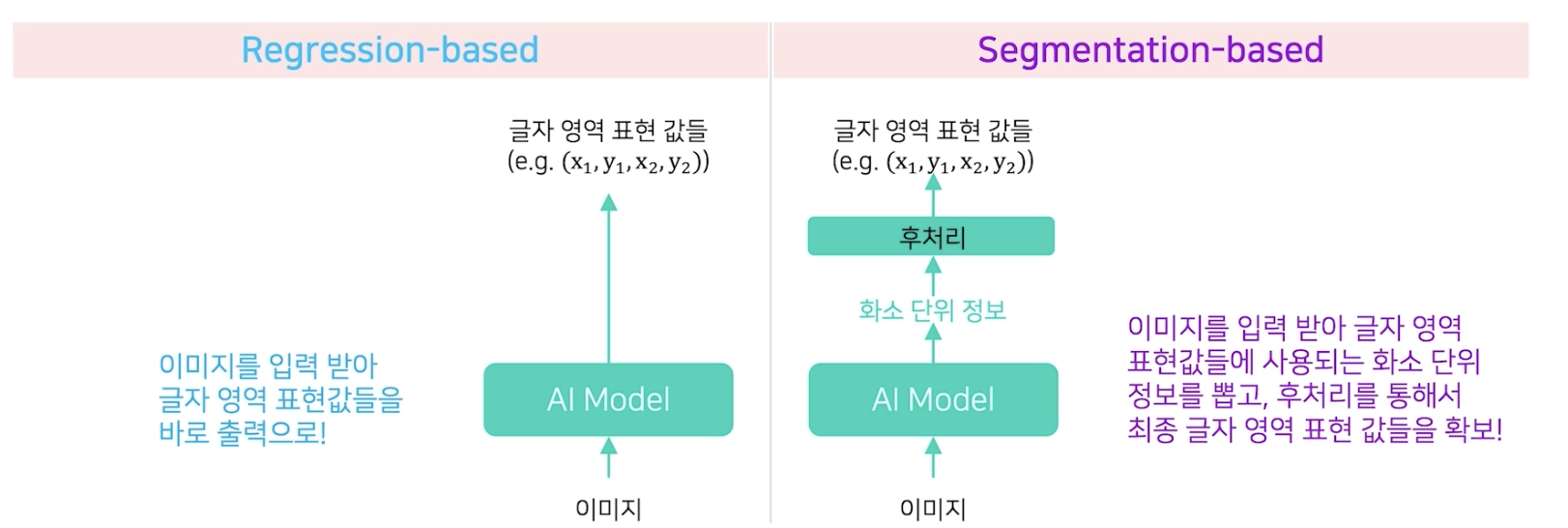
Segmentation-based
이미지를 입력 받아 글자 영역 표현값들에 사용되는 화소 단위 정보를 뽑고, 후처리를 통해서 최종 글자영역 표현 값들을 확보한다. 대표적인 방법으로는 2018년에 발표된 PixelLink'18 논문이 있다.
- PixelLing'18
Hybrid
최근에는 Reression과 Segmentation의 단점을 보완한 hybrid 기법이 사용되고 있다.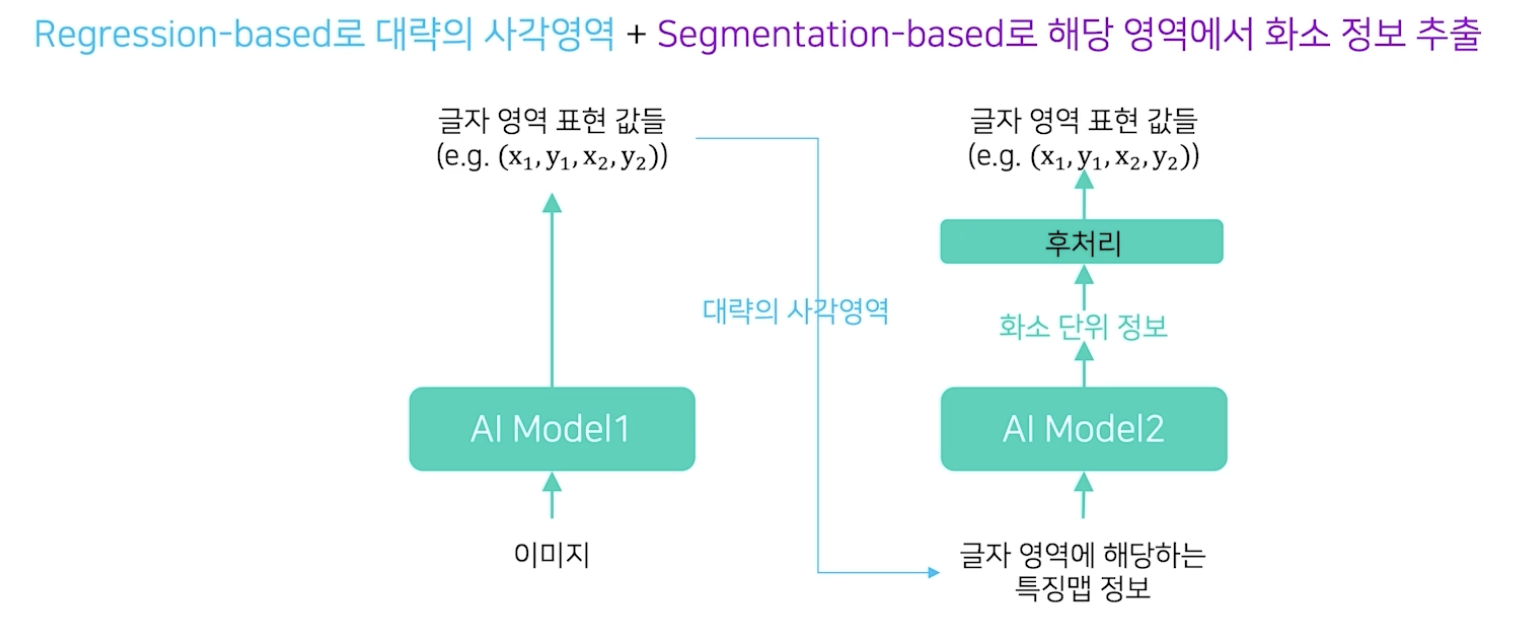
Baseline Model - EAST
- EAST: An Efficient and Accurate Scene Text Detector. CVPR, 2017
EAST 논문은 2.0 software 방식으로 좋은 성과를 낸 첫 논문이라고 볼 수 있다.

EAST는 일종의 segmetation 기반의 모델로서 입력이미지에서 화소 단위의 정보를 추출하고, 후처리를 통해 글자영역을 검출한다.
- 화소 단위 정보
- 화소 단위의 정보로는 글자영역 중심에 해당하는지에 대한 Score map
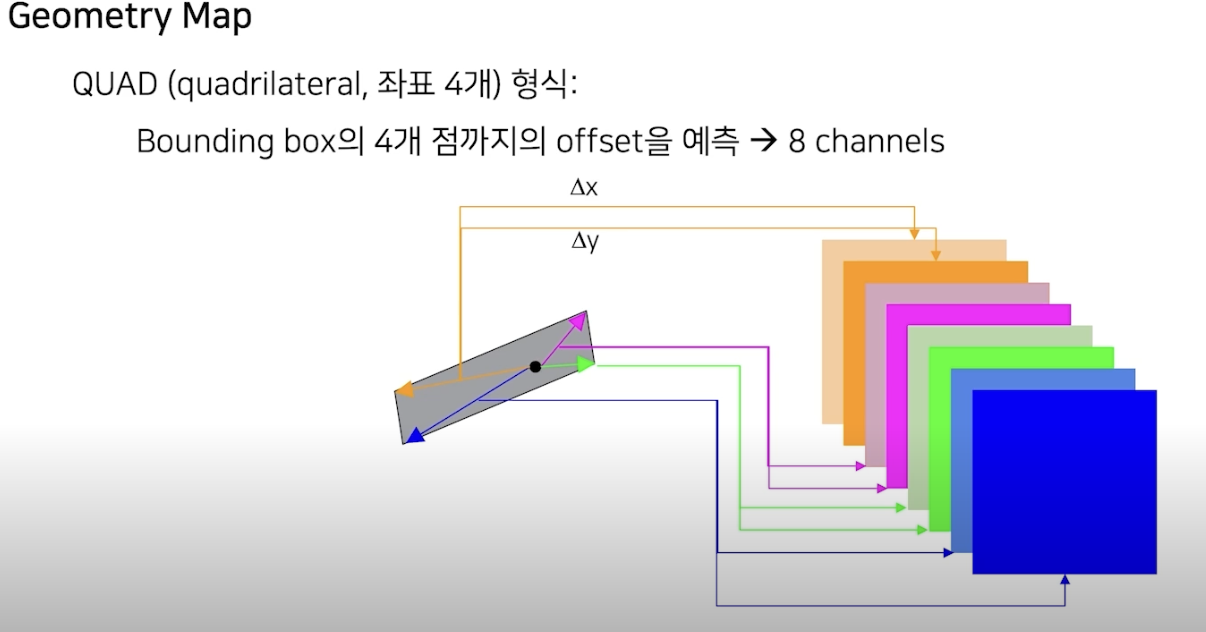
- Bounding box의 위치는 어디인지에 대한 geometry map(해당 화소가 글자 영역이라면 해당)

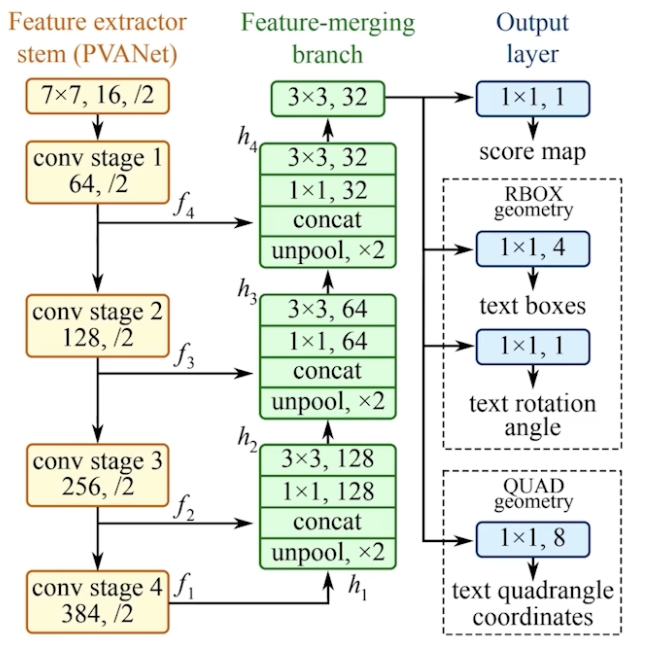
EAST model 구조
- U-net구조
크게 세가지 부분으로 구성 되어있다
-
Feature extrcator stem: PVANet,vggNet,...등 여러 모델을 사용할 수 있지만 baseline에서는 vgg를 사용한다.
-
Feature merging branch:(feature map을 키워가며 concat)
Uppool로 크기 맞추고 concat 1x1,3x3 convolution으로 channel수 조절 -
Output: H/4 x W/4 x C maps


Training



잘하자