Data
1.교차 검증 'Cross Validation'

우리가 사용할 데이터가 있고, 그 데이터는 label이 있는 train, test set으로 구성되어 있다고 할 때, 고정된 test set을 가지고 모델의 성능을 확인하고 파라미터를 수정하는 과정을 반복하면 결국 내가 만든 모델은 test set에만 잘 동작하는 모델
2.Data 분할
1)from sklearn.model_selection import train_test_splittrain_set , test_set = train_test_split(train, train_size = 0.8, shuffle = True)print(train_set.
3.시계열 데이터
시간에 따른 변화를 데이터로 나타내는 것을 시계열 데이터라고 하고, 시계열 데이터를 분석할 때는 크게 데이터를 추세, 주기, 계절성으로 구분한다. 추세 : 장기적으로 늘어나거나 줄어드는 형태, 추세선으로 표현 가능주기 : 구정된 시간 단위로 유사한 변동 형태가 나타나는
4.전제
무엇보다도 논리와 정의가 중요한 데이터 분석에서, 정의를 잘 모르는 단어를 대충 자신의 생각대로 사용하는 데에서 수많은 일그러진 분석 결과가 만들어지고, 데이터 분석가의 일그러진 표정이 만들어지곤 한다. 자신이 아는 것으로 모든 것을 해석하는 데는 한계가 있다. 자신이
5.Random forest
여러 개의 의사 결정 나무를 만들어서 이들의 평균으로 예측의 성능을 높이는 방법: 앙상블 기법 (Ensemble), 주어진 하나의 데이터로부터 여러 개의 랜덤 데이터셋을 추출해, 각 데이터셋을 통해 모델을 여러 개 만들 수 있음배깅(Bagging) / 부스팅(Boost
6.Latent Dirichlet Allocation, LDA
토픽 모델링 : 문서의 집합에서 토픽을 찾아내는 프로세스(문서의 주제를 알아내는 일)★잠재 디리클레 할당(Latent Dirichlet Allocation, LDA)은 토픽 모델리의 대표적인 알고리즘LDA : 토픽들의 혼합으로 구성되어져 있으며, 토픽들은 확률 분포에
7.별점
점점 사용자들이 직접 매긴 점수는 크게 사용하지 않는 추이고, 별점은 식당과 상담원과 서비스 제공자가 고객에게 매달리는 용도로만 사용된다. 많은 서비스에서는 이미 이런 사용자가 주는 점수 대신 '사용자들이 다시 보는 프로그램', '재방문자', '배달 시간'같은 실제 사
8.데이터 형태
\*스터디에서 보기로 한 데이터 위주로 정리논리형(boolean형) : True / False 두 가지 값만 존재, 일반적으로 참은 True, 거짓은 False, 일치 혹은 불일치 여부 확인 가능\*범주형(몇 개의 범주로 나누어진 자료)명목형(nominal data)
9.NLTK
\*스터디 멤버의 논문 작성과 관련하여 데이터 요청이 있어 알게 된 새로운 데이터 세계:)NLTK(Natural Language Toolkit)은 자연어 처리 미치 문서 분석용 파이썬 패키지다. 주요 기능은 '말뭉치', '토큰 생성', '형태소 분석', '품사 태깅'을
10.머신러닝 개념 정리
\*지도 학습(올바른 답이 레이블에 존재하는 것) : 분류(Yes or No와 같은 이진 분류, 개와 고양이 분류하는 다중 분류) / 회귀(연속적인 값을 찾는 것. 예측)\*비지도 학습(Input 데이터에 올바른 답이 없는 것이 주어짐) : 군집(구글 뉴스, 유사도)
11.선형 회귀 모델
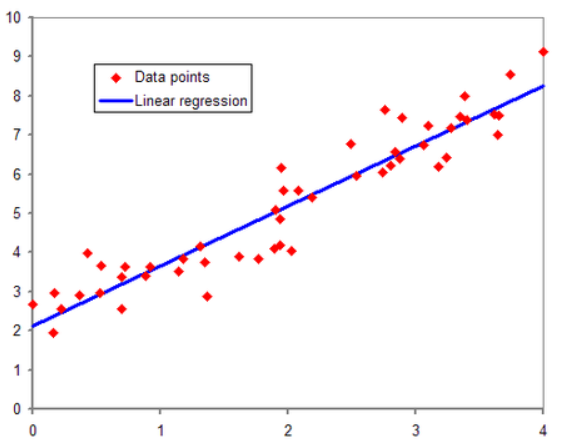
지도 학습의 대표적인 예로, 레이블(정답)이 있는 데이터를 다룬다.회귀식에서 MSE(평균 제곱 오차)를 통해 가장 적합한 w와 b값을 찾는 일★회귀 : 평균으로 돌아간다→ 어떠한 변수가 평균값으로 돌아간다고 가정한다면, 평균값은 무엇이며, 평균값에 어떠한 변수들이
12.행동 데이터
주어지는 숫자보다은 실제로 고객이 매일마다 움직이는 행동 데이터를 기반으로 고객을 이해하는 것이 더욱 필요하다. 기존에는 의지 할 수 있는 것이 몇 안 되는 외부 통계 자료뿐이었기 때문에 '사람'을 정의하는 데 성별, 나이, 사는 지역 같은 정보를 사용할 수 밖에 없었
13.선형 회귀 간단한 모델 구현하기
(4,)dtype('int32')array(\[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
14.LDA 진행 중
스터디에서 공유받은 코드 중 일부 전체적인 로직과 흐름을 이해를 못하고 있어 엄청 헤매고 있다. 다음 스터디에서 관련 내용에 대해 팀원이 정리해주시기로 했는데 사전에 공부를 해야 정리해주는 내용도 이해가 잘 될 것 같다...
15.통계가 왜 필요할까?
\_패스트 캠퍼스 '통계와 엑셀을 활용한 데이터 분석 올인원 패키지 Online' 강의 Chapter 01.의 내용을 정리 했습니다. 링크텍스트\-통계학이란?관심의 대상이 되는 집단 즉, 모집단의 특성을 파악하기 위해 모집단으로부터 일부의 자료(표본, 우리가 가지고 있
16.자료 데이터
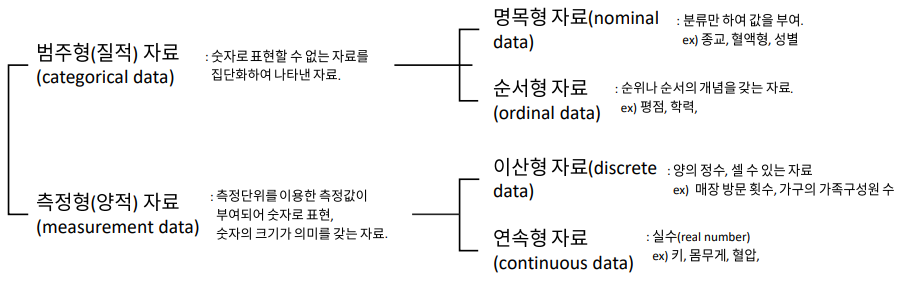
링크텍스트\*기술 통계학자료를 하나 하나 열거하기 보단 몇 가지 대표적인 통계량으로 파악하는 것이 더욱 효과적(특히 둘 이상의 집단을 비교할 때)범주형 자료 : 숫자로 표현할 수 없는 자료측정형(양적) 자료 : 숫자의 크기와 의미를 갖는 자료자료의 기술 : 위치의 측도
17.소비자가 광고를 보고 상품을 구매할 '확률'

패스트 캠퍼스 '통계와 엑셀을 활용한 데이터 분석 올인원 패키지 Online' 강의 Chapter 02.의 내용을 정리 했습니다.링크텍스트\*확률확률의 공리 : 몇 가지 조건을 설정하고 이를 만족하는 경우상호 배반 : 동싱에 발생할 수 없는 사상종속 관계 : 두 사상
18.소비자가 광고를 본 다음 할 수 있는 모든 행동 '확률 변수'
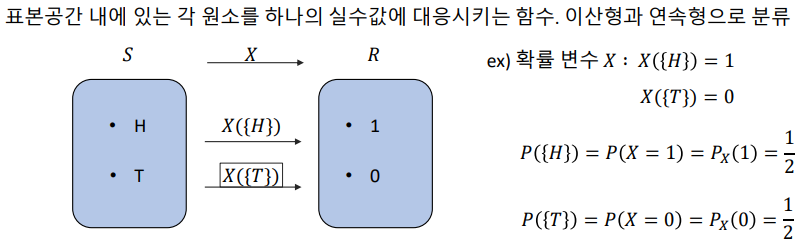
\_패스트 캠퍼스 '통계와 엑셀을 활용한 데이터 분석 올인원 패키지 Online' 강의 Chapter 02.의 내용을 정리 했습니다.링크텍스트확률변수 : 표본 공간 내에 있는 각 원소를 하나의 실수값에 대응시키는 함수, 이산형과 연속형으로 분류
19.데이터 편집
패스트 캠퍼스 '통계와 엑셀을 활용한 데이터 분석 올인원 패키지 Online 강의 Chapter 04.의 내용을 정리 했습니다.링크텍스트"데이터 편집"1) 원본 데이터를 받았을 때 폰트 크기를 줄이고 셀 넓이를 조절하여 가독성을 높이는 작업을 한다. 2) 첫 번째 A열
20.분산 분석
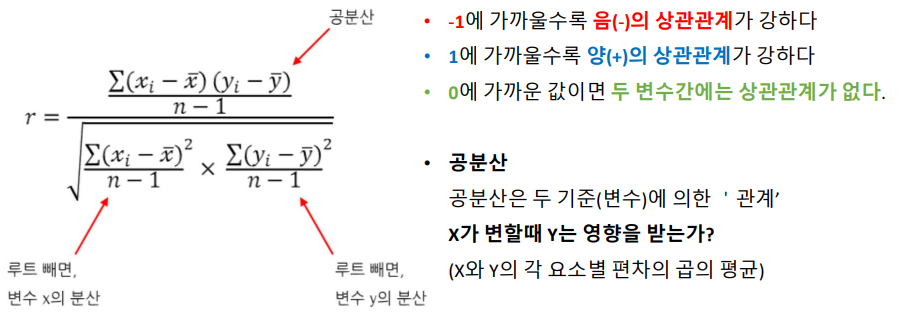
_패스트 캠퍼스 '통계와 엑셀을 활용한 데이터 분석 올인원 패키지 Online' 강의 Chapter 05.의 내용을 정리 했습니다. 링크텍스트
21.ANOVA를 활용한 가설 검정

\_패스트 캠퍼스 '통계와 엑셀을 활용한 데이터 분석 올인원 패키지 Online' 강의 Chapter 05.의 내용을 정리 했습니다.서로 다른 집단이 세 개 이상일 때 집단 간 평균의 차이를 검정평균에 대한 비교이지만, 분산의 개념을 활용하여 검정하기 때문에 분산 분석
22.SNS 채널별 광고 효과 분석

\_패스트 캠퍼스 '통계와 엑셀을 활용한 데이터 분석 올인원 패키지 Online 강의 Chapter 05.의 내용을 정리 했습니다.링크텍스트유입수 : 각 SNS 채널을 통해 (광고하는) 사이트에 유입시킨 수 유입률 : 노출된 컨텐츠를 클릭한 사람이 실제로 얼마나 유입되
23.클릭을 부르는 배너 위치

\_패스트 캠퍼스 '통계와 엑셀을 활용한 데이터 분석 올인원 패키지 Online 강의 Chapter 05.의 내용을 정리 했습니다.링크텍스트\*분산분석 : 서로 다른 변수나 표본이 있을 때, 그것들을 비교하는 분석법\*동일 기간, 같은 콘텐츠, 각 이벤트(총 3건)의
24.여름에 판매하면 좋은 상품
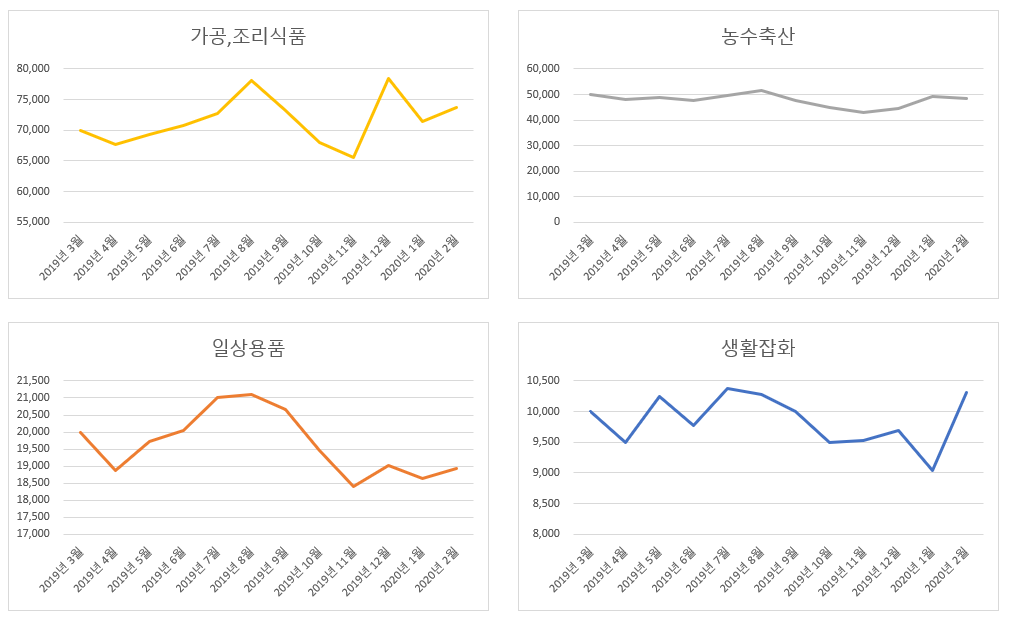
\_패스트 캠퍼스 '통계와 엑셀을 활용한 데이터 분석 올인원 패키지 Online' 강의 Chapter 05.의 내용을 정리 했습니다.\*분산분석 : 서로 다른 변수나 표본이 있을 때, 그것들을 비교하는 분석법\*품목별 매출 동향에 어떤 요인이 영향을 미치는가?\*각 품
25.상품 서비스 기획-성공적인 이벤트를 돕는 배너 기획
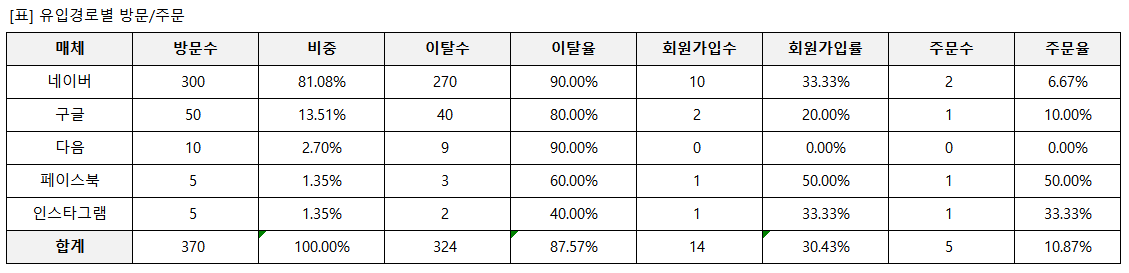
패스트 캠퍼스 '통계와 엑셀을 활용한 데이터 분석 올인원 패키지 Online' 강의 Chapter 08.의 내용을 정리 했습니다.\-배너를 언제, 누구에게 노출시킬지에 대하여 고민하기\-시간대별 트래킹 파악하기▼예시\-방문수 대비 이탈수, 회원가입수, 주문수 비교하기(
26.상품 서비스 기획 - 컬러와 가격이 결정하는 패션 아이템
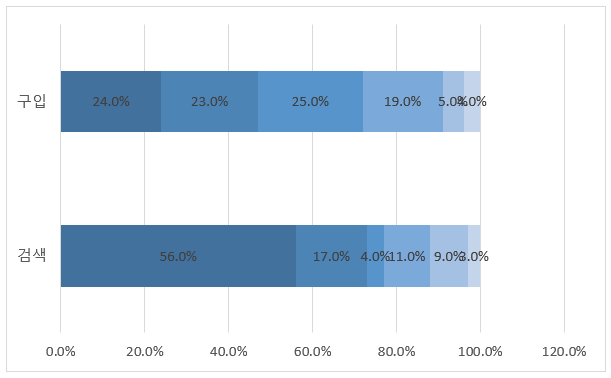
패스트 캠퍼스 '통계와 엑셀을 활용한 데이터 분석 올인원 패키지 Online' 강의 Chapter 08.의 내용을 정리 했습니다.꺽은 선, 막대 혼합 그래프 만들어보기★데이터 시각화 연습하기 주요 검색어 리스트업 하기(검색 광고) : 판매 전략 데이터로 활용
27.마케팅 - SNS 광고 효율을 올리기 위한 광고 전략

패스트 캠퍼스 '통계와 엑셀을 활용한 데이터 분석 올인원 패키지 Online' 강의 Chapter 08.의 내용을 정리 했습니다.: 시즌, 시기에 맞는 이슈들 확인해보기노출수에 영향을 미치는 요인들은?클릭 당 비용은 적을수록 좋다
28.마케팅 - 네이버 검색량에 따른 콘텐츠 소비의 변화
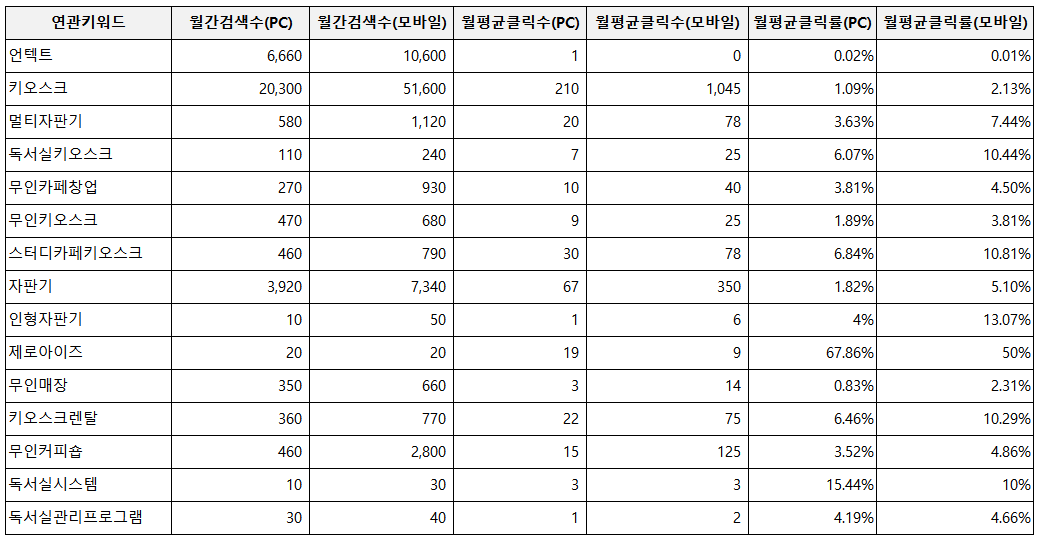
패스트 캠퍼스 '통계와 엑셀을 활용한 데이터 분석 올인원 패키지 Online' 강의 Chapter 08.의 내용을 정리 했습니다.PC와 모바일 상의 클릭수, 검색수, 검색어가 어떤 차이를 보이는지 확인해 보기\- 경험적으로 '검색어'는 이용자의 직관과 니즈를 이해할 수
29.생산 관리 - 계절별 주력 상품 판매 전략 수립
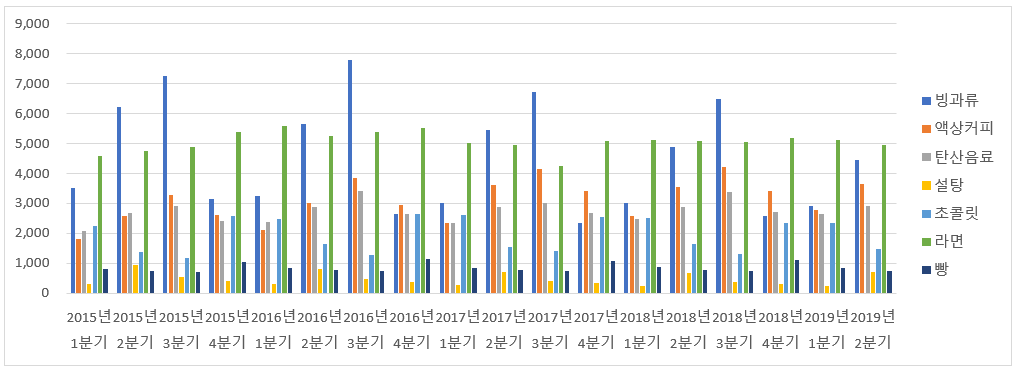
패스트 캠퍼스 '통계와 엑셀을 활용한 데이터 분석 올인원 패키지 Online' 강의 Chapter 08.의 내용을 정리 했습니다.추세선 그려보는 습관 ; 궁극적으로 추세선으로 알 수 있는 것, 아닌 것을 구별하기추세, 추이, 트렌드 파악하기 월별, 분기별로 데이터 시각
30.생산 관리 - 코로나 이슈에 따른 매출 임팩트
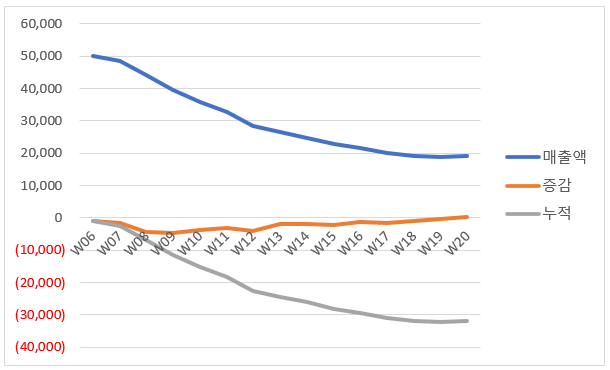
패스트 캠퍼스 '통계와 엑셀을 활용한 데이터 분석 올인원 패키지 Online' 강의 Chapter 08.의 내용을 정리 했습니다.모수의 차이로 인해 그래프상에서 제대로 된 변화를 보여줄 수 없는 경우, 하나의 항목에 하나의 그래프가 노출되도록 한다. 데이터 시각화에 있