1) Kafka 란 무엇인가
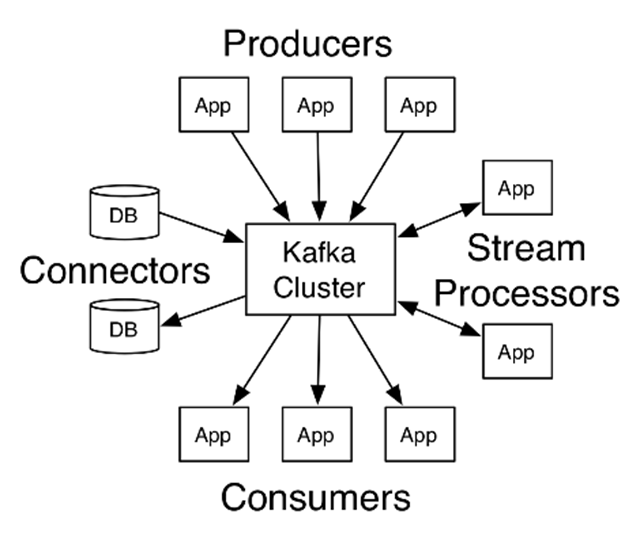
카프카는 Publish-Subscribe 모델을 구현한 분산 메시징 시스템이다.
데이터 파이프라인(Data Pipeline)을 구축할 때
가장 많이 고려되는 시스템 중 하나가 '카프카(Kafka)' 일 것이다.
2) Kafka 탄생 배경
LinkedIn에서 개발된 분산 메시징 시스템으로 2011년에 오픈소스로 공개되었다.
[기존 링크드인 시스템의 가진 문제점]
하나의 서비스가 너무 많은 시스템과 연결된다
그로 인해 유지 관리 부담은 더욱 더 늘어나게 되었고, 이로 인해 기능 개발 자체가 지연되었다
첫째 : 실시간 트랜잭션 처리와 비동기 처리가 동시에 이뤄지지만 통합된 전송 영역이 없으니 복잡도가 증가할 수밖에 없다.
둘째 : 통합 데이터 분석을 위해 서로 다른 데이터 시스템을 연결해야할 경우, 데이터의 포맷이나 처리하는 방법이 다르다면 통합하기가 어렵다. 또한 두 시스템 간의 데이터가 서로 달라져 신뢰도마저 낮아질 수 있다.
[과거]
과거에는 많은 서비스에서 생성되는 모든 이벤트의 부하를 견딜만한 버스 시스템이 없었다.
이전 세대에서는 회사 전체의 데이터가 파편화되어 총합적인 데이터 분석이 어려웠다.
[현재]
클라우드 시대가 본격적으로 열리면서 컴퓨텅 리소스는 더이상 영속적이지 않는다.
데이터가 증가함에 따라 스케일아웃이 가능한 시스템이다.
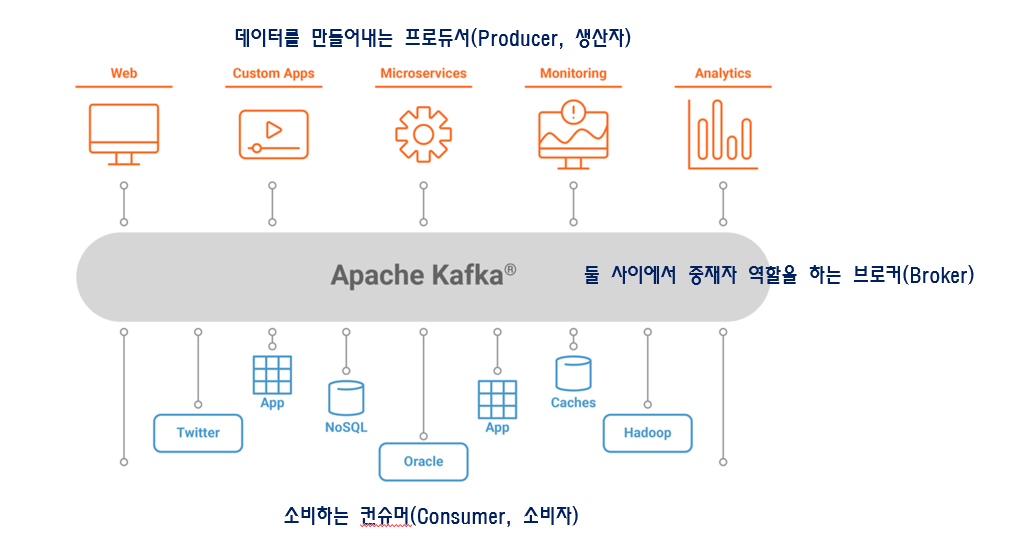
데이터 중앙화 : 카프카를 메시지 전달의 중앙 플랫폼으로 두고, 기업에서 필요한 모든 데이터 시스템(오라클, NOSQL, 하둡) 뿐만 아니라 마이크로 서비스, 사스 서비스 등과
연결된 파이프라인을 만드는 것을 목표로 두고 개발되었다.
[링크드인에서 카프카를 적용한 이후]
사내 서비스에서 발생하는 모든 이벤트/데이터의 흐름을 중앙에서 관리한다.
카프카가 제공하는 데이터를 이용해서 다양한 분석이 가능해졌다.
개발 입장에서도 여러 데이터 시스템에 의존하지 않고, 카프카에만 데이터를 전달하면 되기 때문에 본연의 업무에만 집중할 수 있게됨