상황
몇 십 만개의 데이터를 갱신하는 스케쥴러들의 작동이 이상이 생겼다. ArgoCD 로그를 보니, 다음과 같은 것이 찍혀있었다.
Error 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
트랜잭션 데드락이 발생하고 있었다.
다음 명령어를 활용해서 MySQL의 최근 상태를 확인해보았다.
SHOW ENGINE INNODB STATUS;확인해보았더니, 다음과 같았다.
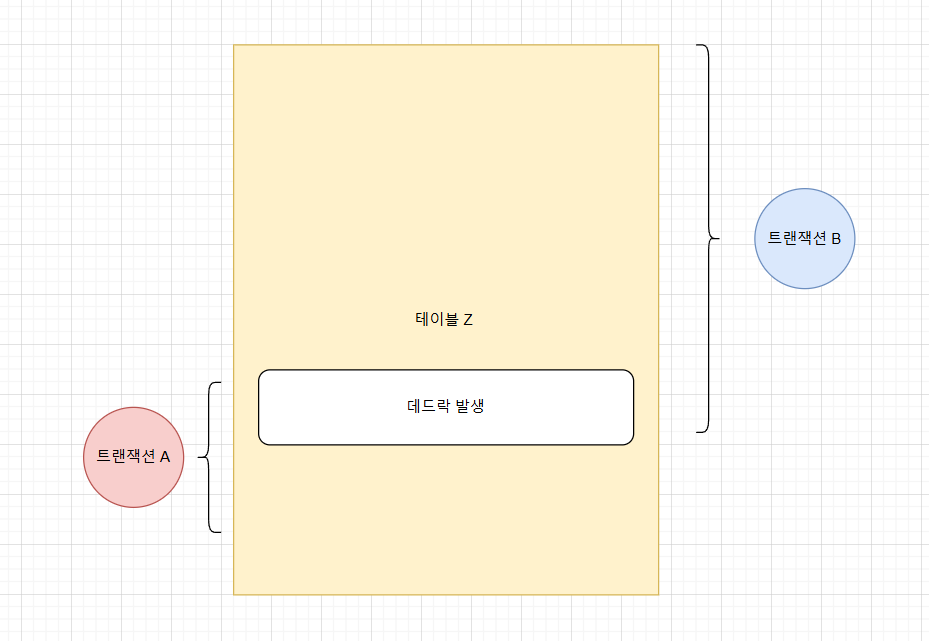
- 트랜잭션 A가 테이블 Z의 레코드 K에 대해 update 쿼리를 실행 중이고 특정 레코드 L에 대해 X락 (배타적 락)을 획득하려고 대기중
- 트랜잭션 B가 테이블 Z의 레코드 L에 대해 update 쿼리를 실행 중이고 특정 레코드 K에 대해 X락 (배타적 락)을 획득하려고 대기중
개념
- 공유 락 (S락)
- 데이터를 읽기 위해 설정되는 락으로, 여러 트랜잭션이 동시에 데이터에 접근할 수 있도록 허용함.
- 공유락이 설정된 데이터는 다른 트랜잭션에서 읽기는 가능하지만, 쓰기는 불가능함.
- 동일한 데이터에 여러 공유 락이 동시에 설정될 수 있음
- 배타적 락 (X락)
- 데이터를 수정하거나 삭제할 때 설정되는 락
- 배타적 락이 설정된 데이터는 다른 트랜잭션에서 읽기와 쓰기 모두 불가능
- 동일한 데이터에 대해 단 하나의 배타적 락만 설정 가능
- 트랜잭션 데드락 : 두 개 이상의 트랜잭션이 서로 보유한 자원을 기다리며 무한정 대기 상태에 빠지는 상황. (서로가 서로의 락 해제를 기다리고 있어 진행이 불가능함.)
해결
트랜잭션은 100% 되거나 0%로 안되는 경우만 있어야 한다. 따라서 반드시 같이 처리해야 하는 작업은 같은 트랜잭션에 묶여야 한다. 그럴 필요가 없는 작업들은 다른 트랜잭션에서 처리해도 된다.
내가 했던 실수는 같은 트랜잭션에 처리할 필요가 없는 데이터들을 같은 트랜잭션에 묶었다는 것이다. 그것도 대규모 데이터 갱신이 필요한 로직에서...!
그에 따라 불필요하게 트랜잭션 락의 범위가 커지고, 트랜잭션 락이 살아있는 시간이 오래 지속되어 데드락 발생 확률을 높인 것이다.
그래서 트랜잭션 락의 범위를 줄여보기로 했고, 스케쥴러에 두 가지 그룹이 있는 것을 확인했다.
- 스케쥴러들이 어떤 순서 경로를 따르던 간에 상관 없이 데이터 일관성에 문제가 없는 스케쥴러들
- 작동 순서가 중요한 스케쥴러들
그룹 1의 경우에는 어떤 순서로 작동하던지 상관이 없었기 때문에 작동 순서에 의해 일관성이 깨질 염려가 없었다. 따라서 트랜잭션 범위를 최대한 줄여보았다. (테스트는 db 데이터 dump 후 로컬에서 실험했다!)
레코드 1개로 줄일 수 있으면 레코드 1개 단위의 트랜잭션으로 줄였고, 짧은 락 시간을 유지하도록 하였다. 그리고 순서가 상관 없기 때문에 고루틴으로 그룹 2와 병렬 처리할 수 있었다.
반면, 그룹 2의 경우는 작동 순서가 보장이 되어야 했다. 해당 작업들은 스케쥴러 하나에 여러 개의 job으로 등록하여 순서대로 작동시킬 필요가 있었다. 그래서 전략 패턴과 가변 인자를 활용해서 job 배열을 생성자에 주입하게 했다. 왜냐하면 한 스케쥴러 job의 메서드에 다른 job의 메서드들을 추가 호출하기만 하는 것은 스케쥴러 job 이름과 매칭이 안되기 때문이다.
type JobRunner interface {
Execute(ctx context.Context, entClient *ent.Client) (interface{}, error)
}
type EntScheduler struct {
*BaseScheduler
schedulerJobRunners []JobRunner
entClient *ent.Client
parsedTimeSpec string
}
func NewEntScheduler(
entClient *ent.Client,
parser TimeSpecParser,
schedulerJobRunners ...JobRunner,
) *EntScheduler {
parsedSpec, err := parser.ParseSpec()
if err != nil {
log.Printf("스케쥴러 시간을 파싱하는 데 실패했습니다: %v", err)
return nil
}
return &EntScheduler{
BaseScheduler: NewBaseScheduler(),
schedulerJobRunners: schedulerJobRunners,
entClient: entClient,
parsedTimeSpec: parsedSpec,
}
}
func (s *EntScheduler) Start(ctx context.Context) error {
_, err := s.cron.AddJob(
s.parsedTimeSpec, func() {
for _, jobRunner := range s.schedulerJobRunners {
_, err := jobRunner.Execute(
ctx,
s.entClient,
)
if err != nil {
log.Printf(
"ent 스케쥴러 작동에 실패했습니다:%v ",
err,
)
}
}
},
)
if err != nil {
return errors.New("ent 스케쥴러 시작에 실패했습니다")
}
return s.BaseScheduler.Start(ctx)
} schedulers := []scheduler.EntScheduler{
scheduler.NewEntScheduler( // 고루틴으로 병렬 처리
entClient,
scheduler.NewTimeSpecParser(scheduler.MidNight),
scheduler.NewAJobRunner(),// A 작업 이후 B 작업 실행
scheduler.NewBJobRunner(),
),
scheduler.NewEntScheduler( // 고루틴으로 병렬 처리
entClient,
scheduler.NewTimeSpecParser(scheduler.MidNight),
scheduler.NewCJobRunner(),
),
}
schedulers.startAll()
}반드시 같이 해야 하는 최소한의 작업 단위까지 트랜잭션 범위를 줄이고, 그룹에 따라 스케쥴러를 병렬 실행해보니 데드락 문제가 해결되었다.
교훈
시스템에 영향이 가지 않도록 트랜잭션도 범위를 신경쓰면서 걸어야 한다.
트랜잭션 하나도 고심하면서 걸어야 한다!
더 나아가기
DB 동시성과 락에 대한 공부가 필요하다. 그리고 MySQL은 인덱스가 중요하다고 하는데, 얼마나 깊게 연관되어 있을까?
