
기존 첫 번쨰 시도는 실패햇엇다
1월에 전면 재작성을 시도했다. 기존 백엔드를 버리고, 처음부터 모노레포로 구성하여 레이어드 아키텍처로 전환하겠다는 계획이었다. (리포지토리 따로 파는 거였음)
결론적으론, 실패했다. 운영환경의 특정 k8s 데몬이 기존 DB 스키마에 강하게 의존하고 있어서, 새 프로젝트로의 전환 자체가 불가능했다. 솔직히 좀 허탈하고 절망도 느꼈었다
전면 재작성은 엎어졌지만 기존 코드의 문제가 사라진 건 아니었다.
기존 코드의 상태
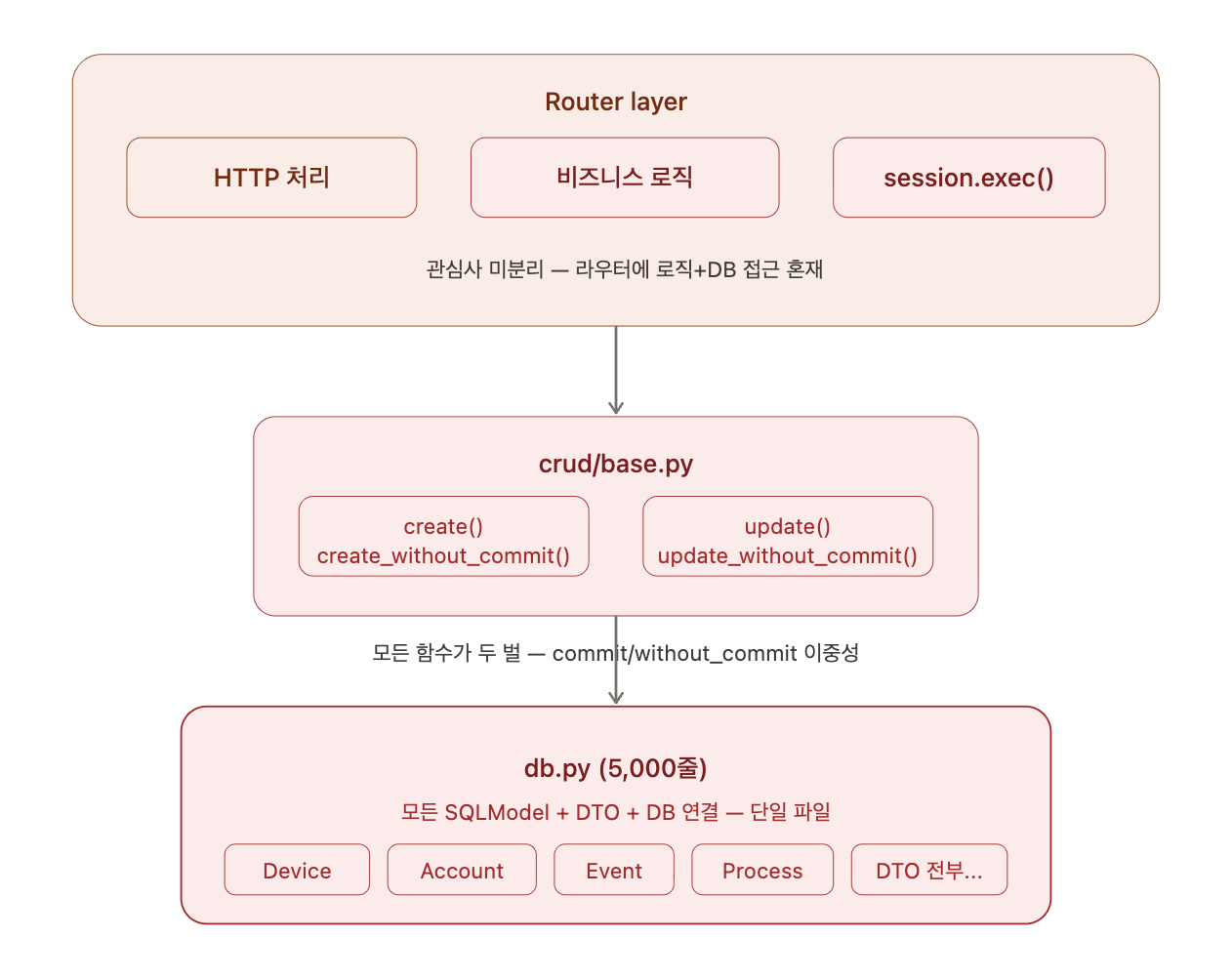
기술 부채가 심각했다.
db.py 하나에 5,000줄. 모든 SQLModel 정의와 DTO가 이 파일 하나에 들어가 있었다. Device, Account, Notification, Process, DataSource — 도메인 구분 없이 전부. Claude Code한테 읽히면 읽기 허용량이 초과될 정도였다.
crud/base.py에는 create()와 create_without_commit(), update()와 update_without_commit() 같이 모든 함수가 두 벌씩 존재했다. 두 가지 요소 이상의 트랜잭션 처리가 안 되어 있었고, PostgreSQL 단일 트랜잭션만 겨우 돌아가는 상태였다.
라우터에는 전부 다 섞여 있었다. HTTP 처리, 비즈니스 로직, session.exec(select(...))같은 DB 직접 접근이 하나의 함수 안에 공존. 서비스 레이어라는 개념 자체가 없었다.
제약 조건
1월 프로젝트에서 Repository 패턴, UnitOfWork, 레이어드 아키텍처 설계는 이미 해둔 상태였다. 아키텍처를 어떻게 바꿔야 하는지는 알고 있었다.
문제는 실행이었다.
운영 중인 시스템이라 멈출 수 없었고, API 50개 이상을 리팩토링해야 했는데 이걸 2주 안에 혼자서 해야 했다.
결론부터 말하면, Claude Code를 활용해서 해냈다. 거대한 레거시를 작게 쪼개서 AI에게 반복 실행을 맡기고, 매 단계마다 검증하는 방식이었다.
목표 아키텍처
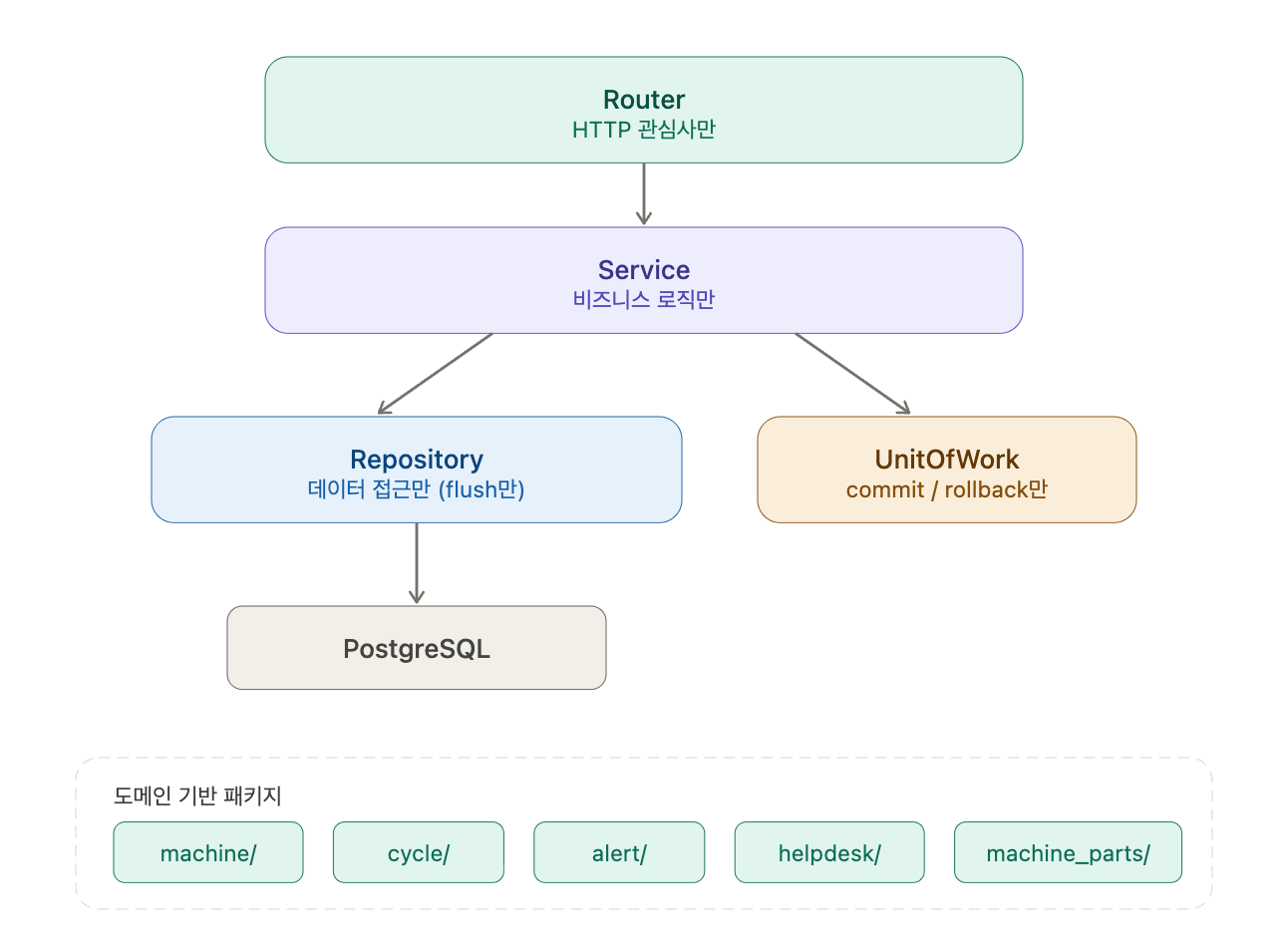
바꾸려는 구조는 명확했다. 1월 프로젝트에서 이미 설계해둔 레이어드 아키텍처 그대로.
Router → Service → Repository → DB
→ UnitOfWorkRouter는 HTTP 관심사만 처리한다. Service는 비즈니스 로직만 담당하고, DB에는 절대 직접 접근하지 않는다. Repository가 데이터 접근을 전담하되, flush()만 하고 commit()은 하지 않는다. 트랜잭션의 commit과 rollback은 오직 UnitOfWork만 수행한다.
이렇게 하면 crud/base.py의 create()/create_without_commit() 이중성이 사라진다. Repository는 항상 flush만 하니까, commit 여부를 호출하는 쪽에서 고를 필요가 없다.
작게 쪼개야 한다
목표 구조는 알고 있었는데, 한번에 바꾸면 안 된다는 것도 알고 있었다.
1월에 전면 재작성을 시도하다가 실패한 경험이 있었다. 그때의 교훈은 명확했다. 거대한 변경을 한번에 하면 망한다. 운영 중인 시스템이면 더더욱.
그래서 리팩토링 자체를 분해했다. 순서는 이렇다:
db.py5,000줄을 model과 schema로 분리한다. 그 다음 각 패키지 안에서 도메인별로 다시 쪼갠다.- 서비스 레이어를 도입한다. 라우터에서 비즈니스 로직을 추출한다.
- 리포지토리 레이어를 도입한다.
crud/base.py를BaseRepository로 교체한다. - 도메인 모델/스키마를 다시 한번 정리한다.
"서비스 레이어 도입"과 "리포지토리 레이어 도입"을 동시에 하지 않았다. 한번에 두 레이어를 바꾸면 변경 범위가 너무 커져서 AI가 실수할 확률이 높아지고, 테스트 실패 시 원인을 특정하기 어려워진다. 각 레이어를 별도 작업으로 나눴고, 그 안에서도 도메인별로 다시 쪼갰다.
가장 먼저 db.py를 분리한 이유는 단순하다. 5,000줄짜리 파일을 Claude Code가 제대로 읽지 못했다. 읽기 허용량을 초과하니까 분석 자체가 안 됐다. AI한테 리팩토링을 시키려면 AI가 코드를 읽을 수 있어야 한다. 그래서 db.py를 models/와 schemas/로 나눈 뒤, 각 패키지 내에서 도메인별 파일로 다시 분리하는 것이 모든 작업의 출발점이었다.
Claude Code 활용 방법론
API 50개 이상의 백엔드를 리팩토링하기 위해 10단계 방법론을 설계했다.
1. 테스트 환경 구축
테스트 DB를 연결해서 Claude Code가 CRUD를 자유롭게 실행할 수 있는 환경을 먼저 세팅했다. 이게 없으면 AI가 코드를 바꿔도 검증할 방법이 없다.
2. 현황 분석 세션
Claude Code 세션을 열고 기존 코드베이스를 통째로 분석시켰다. 어디에 crud.base를 쓰고 있는지, session을 직접 접근하는 곳이 몇 군데인지, 도메인 간 의존관계가 어떻게 되는지를 파악하는 단계다.
3. 안건 선정 및 설계 문서 생성
사람이 우선순위를 판단해서 안건을 선정한다. 그리고 Claude Code에게 해당 안건에 대한 .md 설계 문서를 작성하게 했다. 이때 작업 단위를 적절히 분리하는 것이 핵심이다. "서비스 레이어 + 리포지토리 레이어"를 한번에 하면 컨텍스트 부하로 품질이 떨어진다.
4. 설계 문서 상세화
다른 Claude Code 세션이 바로 작업할 수 있을 정도로 문서를 상세하게 보완한다. 테스트 방법을 반드시 명시하고, 작업이 클 경우 라우터/도메인 단위로 Phase를 분할했다. 인수인계서 수준의 상세도를 목표로 했다.
실제로 이 프로젝트에서 작성한 설계 문서는 6개, 총 4,279줄이었다.
5. 세션 분리
여기가 가장 중요한 포인트다. 설계 세션을 clear하고, 새로운 Claude Code 세션을 열어서 실행 전용으로 사용한다.
설계 컨텍스트와 실행 컨텍스트를 분리하는 이유는 단순하다. 하나의 세션에서 분석부터 실행까지 모두 하면 컨텍스트가 커져서 AI의 실행 품질이 떨어진다. 설계 세션에서는 "이 코드의 문제점은 뭐고, 어떻게 바꿔야 하고, 주의할 점은 뭐다"를 충분히 논의한다. 실행 세션에서는 설계 문서만 읽고 Phase별 코드 변경에만 집중시킨다.
6. Phase별 리팩토링 실행
새 세션에서 설계 문서의 Phase 순서대로 코드 변경을 진행한다.
7. 변경 전 GET 결과 캡처
빌드 전에 모든 GET API의 응답 결과를 캡처해서 baseline을 확보한다. status code와 레코드 수를 기록해둔다.
8. 빌드 및 GET 검증
Docker 빌드 후, 동일한 GET API를 다시 호출해서 캡처한 baseline과 비교한다. status code와 레코드 수가 일치하는지 Claude Code에게 검증시켰다.
9. CUD 라이프사이클 테스트
읽기만 검증해서는 Repository의 create/update/delete가 제대로 flush → commit 되는지 알 수 없다. CUD API는 생성 → 조회 → 수정 → 조회 → 삭제 → 조회(404) 순서로 테스트했다. Claude Code가 Python 스크립트로 자동 실행하고, 동시에 프론트엔드에서 직접 조작해서 교차 검증했다.
10. 반복
모든 Phase가 완료될 때까지 6~9를 반복한다.
역할 분담
이 방법론의 핵심은 사람과 AI의 역할을 명확히 나눈 것이다.
사람이 하는 것: 우선순위 판단, 안건 선정, 설계 문서 검토, Docker 빌드, 프론트엔드 교차 검증. 즉, 판단이 필요한 일.
AI가 하는 것: 코드베이스 분석, 설계 문서 작성, Phase별 코드 변경, GET baseline 캡처 및 비교, CUD 테스트 스크립트 실행. 즉, 패턴이 반복되는 일.
AI의 컨텍스트 윈도우 한계를 이해하고, 설계 판단은 사람이, 패턴 반복 실행은 AI가 담당하는 구조다.
실행 ① — 기반 정리
db.py 분리
모든 작업의 출발점은 db.py 5,000줄을 쪼개는 것이었다.
Claude Code에게 코드베이스를 분석시키려면 먼저 AI가 파일을 읽을 수 있어야 한다. 5,000줄짜리 단일 파일은 읽기 허용량을 초과해서 분석 자체가 불가능했다. 그래서 이게 최우선이었다.
db.py에 뒤섞여 있던 SQLModel 정의를 models/로, DTO를 schemas/로 분리했다. DB 연결 로직은 별도 모듈로 빼냈다. 그 다음 models/와 schemas/ 안에서 도메인별 파일로 다시 쪼갰다.
# Before
models/
└── db.py (5,000줄 — 모든 모델 + DTO + DB 연결)
# After
models/
├── device.py
├── account.py
├── event.py
├── process.py
└── ...
schemas/
├── device.py
├── account.py
├── event.py
└── ...이 단계에서 사용하지 않는 유틸리티, 서비스, 테스트, 예외 클래스도 같이 정리했다. 약 28커밋.
서비스 레이어 도입
db.py 분리가 끝나자 Claude Code가 코드베이스를 정상적으로 읽을 수 있게 됐다. 다음은 서비스 레이어를 도입하는 작업이었다.
기존에는 라우터 함수 안에 비즈니스 로직과 DB 접근이 전부 들어가 있었다. 이걸 분리하는 건 단순하지만 양이 많은 작업이다. 전체 도메인에 걸쳐 서비스 클래스를 도입했다.
# Before — 라우터에 전부 다 있음
@router.get("/devices")
def get_devices(session: Session = Depends(get_session)):
stmt = select(Device).where(Device.is_active == True)
devices = session.exec(stmt).all()
# 비즈니스 로직도 여기서...
return devices
# After — 라우터는 HTTP만, 로직은 서비스로
@router.get("/devices")
def get_devices(session: Session = Depends(get_session)):
service = DeviceService(session)
return service.get_active_devices()스키마 파일도 이 단계에서 도메인별 디렉토리로 이동시켰다. 약 50커밋.
이 단계에서의 AI 활용
Claude Code에게 현황 분석 세션을 먼저 돌렸다. 기존 코드의 import 의존관계, crud.base 사용처, session 직접 접근 패턴을 전부 파악시킨 뒤, 이를 바탕으로 설계 문서 6개(총 4,279줄)를 작성하게 했다.
설계 문서가 완성되면 세션을 clear하고, 새 세션을 열어서 설계 문서만 읽고 실행하게 했다. 세션 분리의 효과는 확실했다. 분석 컨텍스트 없이 설계 문서만 보고 작업하니까 AI가 Phase별 코드 변경에 집중할 수 있었다.
실행 ② — Repository 패턴 도입
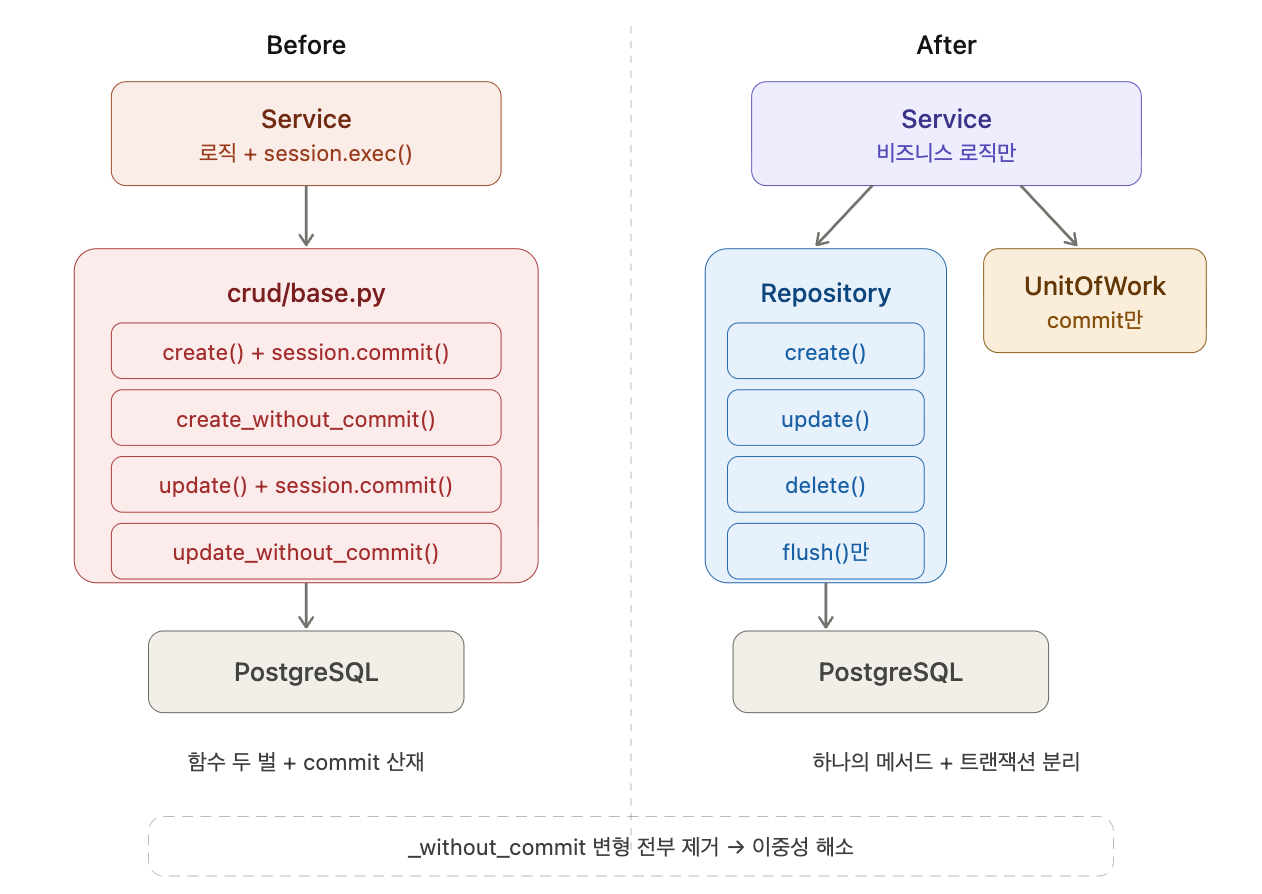
서비스 레이어가 들어갔으니 다음은 데이터 접근 레이어를 정리할 차례였다.
기존 crud/base.py의 문제는 두 가지였다. 모든 함수가 create()/create_without_commit() 식으로 두 벌씩 존재하는 이중성. 그리고 서비스 레이어에서 session.exec(select(...))로 DB에 직접 접근하는 코드가 약 94건 산재해 있었다는 것.
이걸 한번에 고치면 안 된다. 그래서 1차와 2차로 나눴다.
1차: crud/base.py 제거
설계 문서 repository-layer-proposal.md (1,170줄)를 Claude Code에 전달하고 5단계로 실행했다.
핵심은 BaseRepository[T: SQLModel]이다.
class BaseRepository[T: SQLModel]:
"""
범용 Repository. 모든 모델에 대해 기본 CRUD를 제공한다.
- 절대 commit하지 않는다. flush만 수행한다.
- PK 생성은 DB server_default에 위임한다.
"""
def __init__(self, session: Session, model: type[T]):
self.session = session
self.model = model
def create(self, item: SQLModel | dict) -> T:
db_item = self.model.model_validate(item)
self.session.add(db_item)
self.session.flush()
self.session.refresh(db_item)
return db_itemRepository는 flush()만 한다. commit()은 절대 하지 않는다. 트랜잭션 확정은 UnitOfWork가 담당한다. 이렇게 하면 create()/create_without_commit() 이중성이 완전히 사라진다. Repository는 항상 같은 동작을 하고, commit 여부는 UnitOfWork로 감싸는 쪽이 결정한다.
# 쓰기 — UnitOfWork 안에서
def create_device(self, item):
with UnitOfWork(self.session):
return self.repo.create(item)
# 읽기 — UnitOfWork 불필요
def get_device(self, id_):
return self.repo.get(id_)PK 생성도 정리했다. 기존 crud/base.py는 db_item.id = uuid.uuid4()를 하드코딩하고 있었는데, 모든 모델에 이미 server_default: gen_random_uuid()가 설정되어 있었다. Python에서 UUID를 생성할 이유가 없었다. Repository는 session.add() + flush() + refresh()만 하고, PK는 DB가 생성하도록 했다.
단순 CRUD 도메인은 BaseRepository를 직접 사용했고, 복잡한 쿼리가 있는 도메인만 전용 Repository를 만들었다. JOIN이 4~6개 테이블에 걸치는 것들이 해당됐다.
Phase 5에서 crud/base.py를 삭제하고, 프로젝트 전체에서 from crud.base import 참조가 0건인 걸 확인했다.
2차: 서비스 레이어의 session 직접 접근 제거
crud/base.py는 사라졌지만 서비스 레이어에 여전히 session 직접 접근이 약 94건 남아 있었다.
| 위반 유형 | 건수 |
|---|---|
session.exec(select(...)) | ~27건 |
session.get(Model, id) | ~35건 |
session.add() + session.flush() | ~15건 |
session.commit() (UoW 외부) | 2건 |
session.delete() | 4건 |
설계 문서 repository-layer-phase2-proposal.md (1,154줄)를 Claude Code에 전달하고 10단계로 실행했다.
위험도 순으로 진행했다. session.commit()이 UnitOfWork 밖에서 호출되는 2건을 가장 먼저 제거하고, 단순한 도메인부터 복잡한 도메인 순으로 전환했다. 가장 복잡했던 건 1,274줄짜리 서비스 파일 안에 DB 직접 접근이 약 20건 있던 케이스였다.
최종 검증은 간단했다.
grep -r "self.session\." server/services/unit_of_work.py를 제외하고 0건. 서비스 레이어에서 session을 직접 만지는 코드가 완전히 사라진 걸 확인했다.
이 단계에서의 AI 활용
1차와 2차 모두 같은 패턴이었다. 설계 문서에 Phase를 정의하고, Claude Code에게 Phase 순서대로 실행시킨다. 각 Phase마다 Docker 빌드 + GET baseline 비교 + CUD 라이프사이클 테스트로 검증한다.
Claude Code가 특히 잘한 건 변환 패턴의 반복 적용이었다. 6가지 변환 패턴을 정의해두면, 도메인마다 같은 패턴을 정확하게 반복했다. 사람이 했으면 도메인 하나당 한 시간은 걸릴 작업을, AI는 몇 분이면 끝냈다.
반면 설계 판단은 사람이 했다. "이 도메인은 전용 Repository가 필요한가, BaseRepository로 충분한가"는 비즈니스 로직을 이해해야 판단할 수 있는 문제였다. AI에게 맡기면 불필요하게 전용 Repository를 만들거나, 반대로 복잡한 JOIN 쿼리를 BaseRepository에 우겨넣는 실수가 생긴다.
검증 — 131커밋의 안전장치
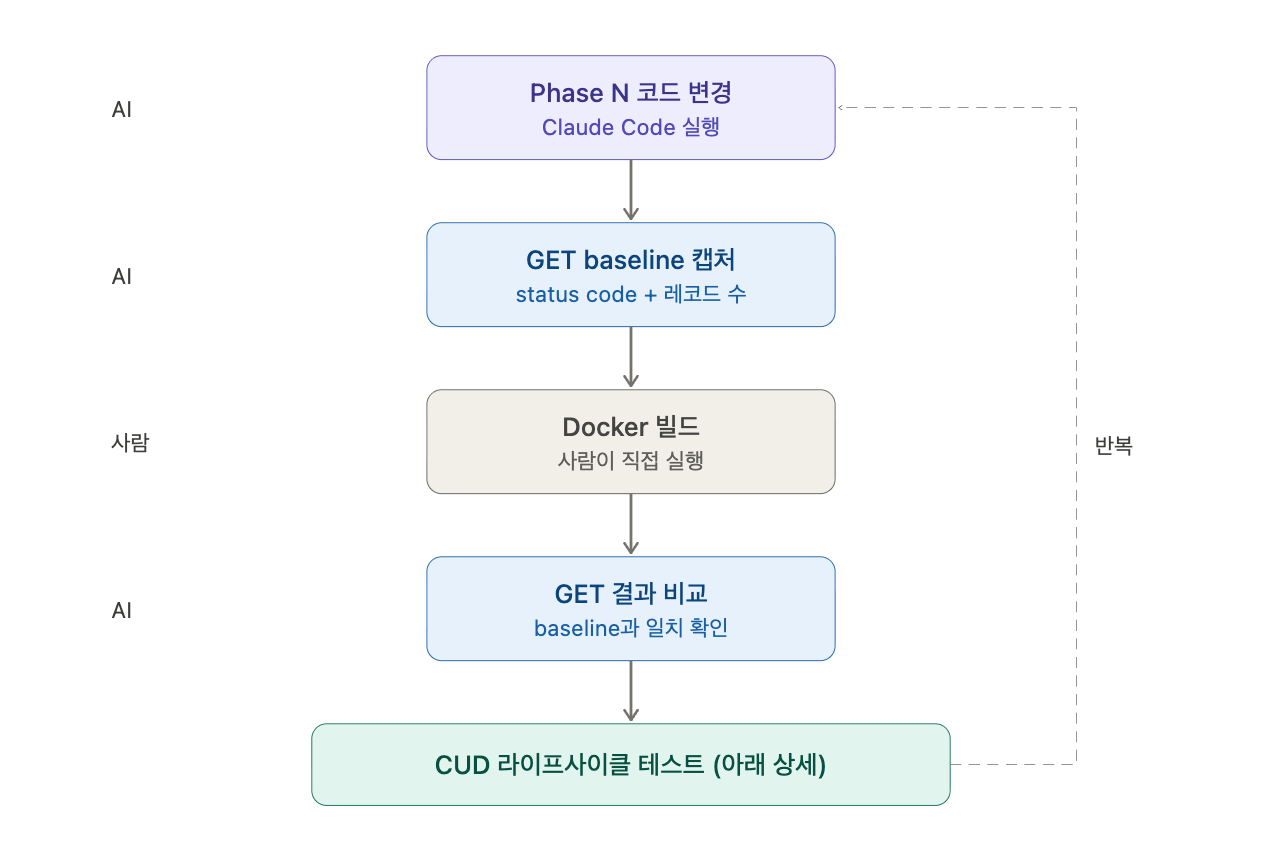
리팩토링에서 제일 무서운 건 "바꿨는데 기존 기능이 깨지는 것"이다. 특히 운영 중인 시스템이면.
131커밋 동안 안정성을 유지할 수 있었던 건 검증 프로세스 덕분이었다. 모든 Phase마다 같은 검증을 반복했다.
Phase별 검증 루프
매 Phase가 끝날 때마다 아래 순서를 돌렸다.
Claude Code가 Phase N의 코드 변경을 완료한다.- 변경 전 모든 GET API의 응답을 Python 스크립트로 캡처한다. status code와 레코드 수를 기록해둔다.
- Docker 빌드는 사람이 직접 한다.
Claude Code가 동일한 GET API를 재호출해서 캡처한 baseline과 비교한다.- CUD 테스트를 실행한다 (아래 상세).
- PASSED 확인 후 다음 Phase로 넘어간다.
CUD 라이프사이클 테스트
GET baseline 비교만으로는 부족하다. status code가 200이고 레코드 수가 같아도, Repository의 create()가 flush()만 하고 commit()이 안 되면 데이터가 실제로 저장되지 않는다. 세션이 끝나면 자동 rollback 되니까.
그래서 CUD 라이프사이클 테스트가 필수였다. 생성 → 조회(존재 확인) → 수정 → 조회(수정 확인) → 삭제 → 조회(404 확인) 전체를 돌려야 flush → commit 경로가 제대로 동작하는지 알 수 있다.
이 테스트는 두 갈래로 동시에 진행했다.
AI 측: Claude Code가 Swagger API를 직접 호출하는 Python 스크립트를 작성하고 실행했다. 생성 → 조회 → 수정 → 조회 → 삭제 → 404 확인까지 자동화된 스크립트로 돌렸다.
사람 측: 프론트엔드에서 직접 조작했다. 데이터를 생성하고 목록에 나타나는지, 수정이 반영되는지, 삭제 후 사라지는지를 눈으로 확인했다. API 스크립트만으로는 못 잡는 케이스가 있다. 실제 UI에서 확인하는 게 마지막 안전장치였다.
양쪽 모두 PASSED여야 다음 Phase로 넘어갔다.
왜 이 방식이 효과적이었나
Phase 단위로 작업을 쪼갠 덕분에 문제가 생겨도 원인 특정이 쉬웠다. "방금 이 Phase에서 바꾼 코드" 범위 안에서만 찾으면 됐다. 전체 리팩토링을 한번에 했으면 어디서 깨졌는지 찾는 것부터 난관이었을 것이다.
작게 쪼개고, 매번 검증하고, 양쪽에서 교차 확인한다. 단순하지만 이게 131커밋의 안정성을 만든 구조였다.
회고
2주 동안 131커밋을 찍으면서 느낀 것들을 정리한다.
잘된 것
세션 분리는 확실히 효과가 있었다. 설계 세션에서 충분히 분석하고, 실행 세션에서는 설계 문서만 보고 작업시키니까 AI의 집중도가 눈에 띄게 달랐다. 하나의 세션에서 "이 코드 분석해줘 → 설계 문서 써줘 → 이제 코드 바꿔줘"를 다 하면, 후반부로 갈수록 품질이 떨어지는 걸 체감했다.
설계 문서의 상세도가 결과를 결정했다. 6개 문서, 총 4,279줄. 과하다고 생각할 수 있는데, 이게 없었으면 AI가 제멋대로 해석해서 의도와 다른 코드를 만들었을 것이다. "이 파일은 import 경로만 수정하고, model_rebuild() 구조는 절대 변경하지 마라" 같은 제약 조건을 명시하는 게 특히 중요했다. AI에게 뭘 하라고 알려주는 것만큼, 뭘 하지 말라고 알려주는 게 중요하다.
Phase별 검증 루프가 안정성을 만들었다. 매 Phase마다 GET baseline 비교 + CUD 라이프사이클 + 프론트엔드 교차 검증을 반복한 건 번거로웠지만, 이게 없었으면 운영 사고가 훨씬 많았을 것이다.
아쉬운 것
Docker 빌드를 매번 사람이 직접 했는데, 이것도 Claude Code로 자동화가 가능했다. 빌드 → 컨테이너 재시작 → 로그 확인까지 스크립트로 묶어서 AI에게 맡겼으면 검증 루프가 훨씬 빨라졌을 것이다. 사람이 개입해야 하는 단계가 하나 줄어드는 셈이니까.
테스트 코드를 먼저 짜보는 건 어땠을까. 리팩토링 전에 기존 동작을 검증하는 통합 테스트를 pytest로 만들어두고, 리팩토링할 때마다 돌렸으면 GET baseline 캡처 같은 수동 작업이 필요 없었을 것이다. 다음에 이런 규모의 리팩토링을 한다면 테스트부터 짜겠다.
정리
거대한 문제는 작게 쪼개야 한다. 레이어별로 쪼개고, 도메인별로 쪼개고, Phase별로 쪼갠다. AI를 활용할 때도 마찬가지다. 컨텍스트를 쪼개고(세션 분리), 작업을 쪼개고(설계 문서 Phase), 검증을 쪼갠다(Phase별 루프).
1월에 전면 재작성을 시도했을 때는 한번에 바꾸려다 실패했다. 2월에는 같은 목표를 작게 쪼개서 달성했다. 도구가 바뀐 게 아니라 접근 방식이 바뀐 것이다.
