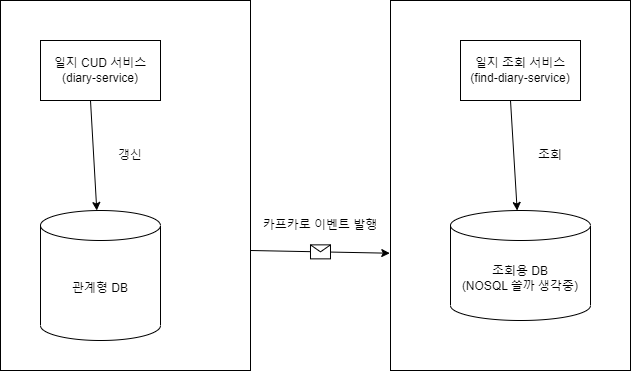
CQRS 패턴 필요성
CQRS 패턴은 명령 조회 책임 분리 패턴의 약자다.
이 패턴을 적용하면 입력,수정,삭제와 조회를 분리해낼 수 있다.
예를 들어, CRUD 중 CUD는 엄격한 스키마를 적용할 수 있고 트랜잭션을 적용할 수 있으며 쓰기 작업에 좋은(정규화로 중복 제거) 관계형 데이터 베이스를 사용하고 R은 조회에 유리한 NOSQL을 사용하는 식이다.
기존 리포지토리 인터페이스 코드
public interface DiaryRepositoryCustom {
/**
* @return 식별자의 최댓값. 혈당 일지 생성 시 id를 지정하기 위해 사용된다. (복합키에는 @GeneratedValue 사용 불가.)
*/
Long findMaxOfId();
Optional<Writer> findWriterOfDiary(Long diaryId);
List<DiabetesDiary> findDiabetesDiariesOfWriter(Long writerId);
Optional<DiabetesDiary> findOneDiabetesDiaryByIdInWriter(Long writerId, Long diaryId);
Optional<DiabetesDiary> findDiabetesDiaryWithSubEntitiesOfWriter(Long writerId, Long diaryId);
List<DiabetesDiary> findDiabetesDiariesWithSubEntitiesOfWriter(Long writerId, List<Predicate> predicates);
List<DiabetesDiary> findDiariesWithWhereClause(Long writerID, List<Predicate> predicates);
void bulkDeleteDiary(Long diaryId);
Optional<Double> findAverageFpg(Long writerId, List<Predicate> predicates);
}
리포지토리 코드 대부분이 find와 연관이 되있다.
create와 update는 기본 JPA 코드를 사용하고 있었다.
문제의 JPA 코드 (Querydsl)
/**
* 단순히 fetch()를 하게 되면, 조인된 테이블의 개수만큼 중복된 엔티티를 얻어오게 된다.
* 따라서 stream().distinct().collect(Collectors.toList()) 를 이용하여 java 단에서 중복을 제거해준다.
*/
@Override
public List<DiabetesDiary> findDiabetesDiariesWithSubEntitiesOfWriter(Long writerId, List<Predicate> predicates) {
return jpaQueryFactory.selectFrom(QDiabetesDiary.diabetesDiary)
.innerJoin(QDiabetesDiary.diabetesDiary.writer, QWriter.writer)
.fetchJoin()
.leftJoin(QDiabetesDiary.diabetesDiary.dietList, QDiet.diet)
.fetchJoin()
.leftJoin(QDiet.diet.foodList, QFood.food)
.fetchJoin()
.where(QDiabetesDiary.diabetesDiary.writer.writerId.eq(writerId)
.and(ExpressionUtils.allOf(predicates)))
.fetch().stream().distinct().collect(Collectors.toList());
}일지 및 연관된 하위 엔티티 모두를 조회하는 코드 예시이다. 각 엔티티들은 기본키가 복합키 형태로 되어있다.
참고로 fetchjoin()은 jpa n+1 문제를 해결하기 위한 코드이다.
이 코드의 문제점은 복잡함이다.
단순히 sql로 작성하면 다음과 같다.
SELECT di.* FROM diabets-diary di
INNER JOIN wrtier w ON di.writer-id=w.id
LEFT JOIN diet d ON di.id=d.diary-id
LEFT JOIN food f ON di.id=f.diary-id
WHERE predicates 조건 ;그래서 읽기 로직에 한해서는 mybatis나 documentDB를 활용하는 게 낫지 않나 싶다.
전자의 경우, n+1 문제를 고려하지 않아도 되며 복잡한 join이 필요한 쿼리라면 단순하게 sql 그대로 작성하면 된다.
후자의 경우 데이터 중심 애플리케이션 설계 (39P)에서 힌트를 얻은 것이다.
데이터가 문서와 비슷한 구조(일대다 관계 트리로 보통 한 번에 전체 트리를 적재)라면 문서 모델을 사용하는 것이 좋다.
내 엔티티 관계의 경우 일대다 관계이며, 계층을 이루는 트리 형태, 그리고 문서 형태로 되어 있다. 그래서 documentDB를 사용해보는게 어떨까 싶다.
물론, 직접 적용하기 전에 충분히 조사해야겠지만.
참고
CQRS 패턴 도입 설계 다이어그램
일지 서비스 엔티티 변경
복합키 제거
이전 모놀리식 프로젝트에서는 복합키 클래스를 만들어 사용했었다.
그런데 복합키의 경우 @GeneratedValue를 활용할 수 없기 때문에 기본키를 생성하는 로직을 일일이 추가해야 했다.
그리고 Querydsl에서의 cross join을 피하기 위해 조인할 때마다 fetch join()을 넣어야 해서 지저분했다.
그래서 양방향 관계는 유지하되, 단일 기본키로 JPA 엔티티를 변경했다.
@Entity
@Table(name = "DiabetesDiary")
public class DiabetesDiary extends BaseTimeEntity {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name = "diary_id")
private Long diaryId;
@OneToMany(mappedBy = "diary", cascade = CascadeType.ALL, fetch = FetchType.LAZY)
private final List<Diet> dietList = new ArrayList<>();
}@Entity
@Table(name = "Diet")
public class Diet {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name = "diet_id", columnDefinition = "bigint default 0")
private Long dietId;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "diary_id")
private DiabetesDiary diary;
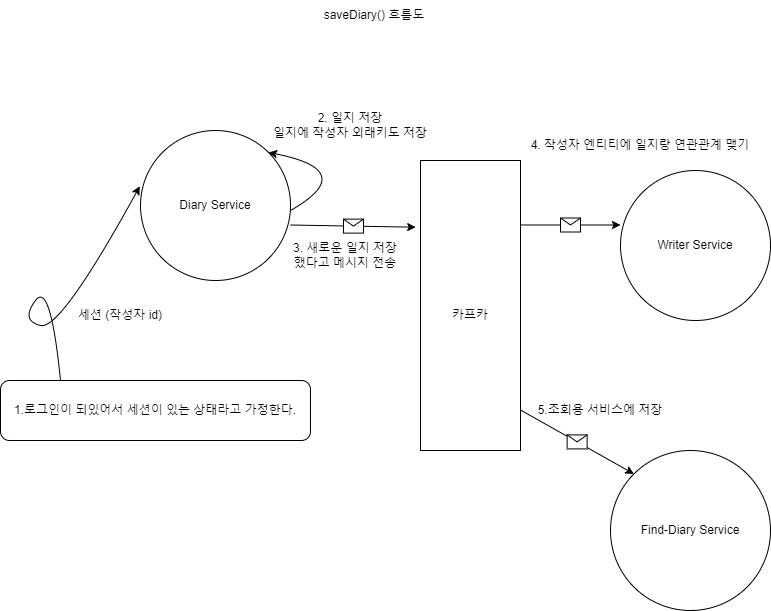
}저장 로직 변경
@Transactional
private Long makeDiaryWithSubEntities(Long writerId, DiaryPostRequestDTO dto, LocalDateTime writtenTime) throws TimeoutException {
logger.info("saving diary in SaveDiaryService correlation id :{}", UserContextHolder.getContext().getCorrelationId());
DiabetesDiary diary = new DiabetesDiary(writerId, dto.getFastingPlasmaGlucose(), dto.getRemark(), writtenTime);
if (dto.getDietList() != null) {
dto.getDietList().forEach(
dietDTO -> {
Diet diet = new Diet(diary, dietDTO.getEatTime(), dietDTO.getBloodSugar());
diary.addDiet(diet);
if (dietDTO.getFoodList() != null) {
dietDTO.getFoodList().forEach(
foodDto -> {
Food food = new Food(diet, foodDto.getFoodName(), foodDto.getAmount());
diet.addFood(food);
}
);
}
});
}
diaryRepository.save(diary);
return diary.getId();
}카프카 메시징 추가
docker-compose에 카프카 추가
zookeeper:
image: zookeeper:3.7.0
ports:
- 2181:2181
networks:
backend:
aliases:
- "zookeeper"
kafkaserver:
image: wurstmeister/kafka:latest
ports:
- 9092:9092
environment:
- KAFKA_ADVERTISED_HOST_NAME=kafka
- KAFKA_ADVERTISED_PORT=9092
- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_CREATE_TOPICS=dresses:1:1,ratings:1:1
volumes:
- "/var/run/docker.sock:/var/run/docker.sock"
depends_on:
- zookeeper
networks:
backend:
aliases:
- "kafka"주키퍼를 띄우고 그 다음 카프카 서버를 띄운다.
CUD 일지 서비스를 메시지 생산자로 지정
카프카 의존성 추가
<!-- message broker -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
</dependency>메시지 생산자로 지정하기
@EnableBinding(Source.class)
@SpringBootApplication
public class DiaryServiceApplication {
public static void main(String[] args) {
SpringApplication.run(DiaryServiceApplication.class, args);
}
}현재 시점에서는 단순하게 메시지 생산만 할 것이기 때문에 @EnableBinding(Source.class)로 했다.
나중에 양방향 통신이 필요하다 싶으면 @EnableBinding(Processor.class)로 부착하면 될 듯 하다.
바인딩 참고
https://www.msaschool.io/operation/implementation/implementation-three/
